reasoning) are notoriously difficult. Initial attempts to solve this issue explored fine-tuning LLMs and task-specific verification modules over a supervised dataset of solutions and explanations of various reasoning problems (View Highlight)
The goal of this paper is to endow language models with the ability to generate a chain of thought—a coherent series of intermediate reasoning steps that lead to the final answer for a problem.” - from [1] (View Highlight)
chain-of-thought (CoT) prompting [1] is a recently-proposed technique that improves LLM performance on reasoning-based tasks via few-shot learning. Similar to standard prompting techniques, CoT prompting inserts several example solutions to reasoning problems into the LLM’s prompt. Then, each example is paired with a chain of thought, or a series of intermediate reasoning steps for solving the problem. The LLM then learns (in a few-shot manner) to generate similar chains of thought when solving reasoning problems. (View Highlight)
LLMs within this section. Rather, we will focus upon developing a better understanding of prompting and few-shot learning for LLMs, as well as explore how such techniques may be leveraged to solve a core limitation of these models: their inability to solve reasoning tasks. (View Highlight)
After the proposal of GPT-3 [2], we saw that LLMs of sufficient scale can perform few-shot learning quite well (View Highlight)
These task-solving “prompts” enable zero-shot (i.e., without seeing examples of correct output; see above) or few-shot (View Highlight)
But, sensitivity is a huge consideration in this developing field. LLM performance may change massively given small perturbations to the input prompt (e.g., permuting few-shot exemplars decreases GPT-3 accuracy from 93.4% to 54.3% on SST-2 [13]). Thus, in our study of prompting approaches, we aim to find techniques that i) perform well and ii) are not subject to sensitivity. (View Highlight)
LLM few-shot learning performance improves with scale, but large models are not all that we need. Powerful LLMs require a combination of large models with massive pre-training datasets [14]. (View Highlight)
we tend to see that using larger models and pre-training datasets does not improve LLM reasoning abilities (View Highlight)
With these limitations in mind, it becomes clear that using a prompting-only approach (e.g., CoT prompting) to solving reasoning tasks would be much simpler (View Highlight)
Instead of fine-tuning an LLM to perform a task, we just “prompt” a generic model with a few examples of the correct output before generating a final answer. Such an approach is incredibly successful for a range of tasks. (View Highlight)
prompting only approach is important because it does not require a large training dataset and a single model can perform many tasks without loss of generality.” - (View Highlight)
Although this example is simple, the idea extends to a variety of mental reasoning tasks that we solve as humans. We generate a chain of thought (defined as “a coherent series of intermediate reasoning steps that lead to the final answer for a problem” (View Highlight)
Authors in [1] find that such a prompting approach leads LLMs to generate similar chains of thought when solving problems, which aids reasoning capabilities and has several notable benefits: (View Highlight)
• Interpretability: the LLM’s generated chain of thought can be used to better understand the model’s final answer.
• Applicability: CoT prompting can be used for any task that can be solved by humans via language.
• Prompting: no training or fine-tuning is required of any LLMs. We can just insert a few CoT examples into the prompt! (View Highlight)
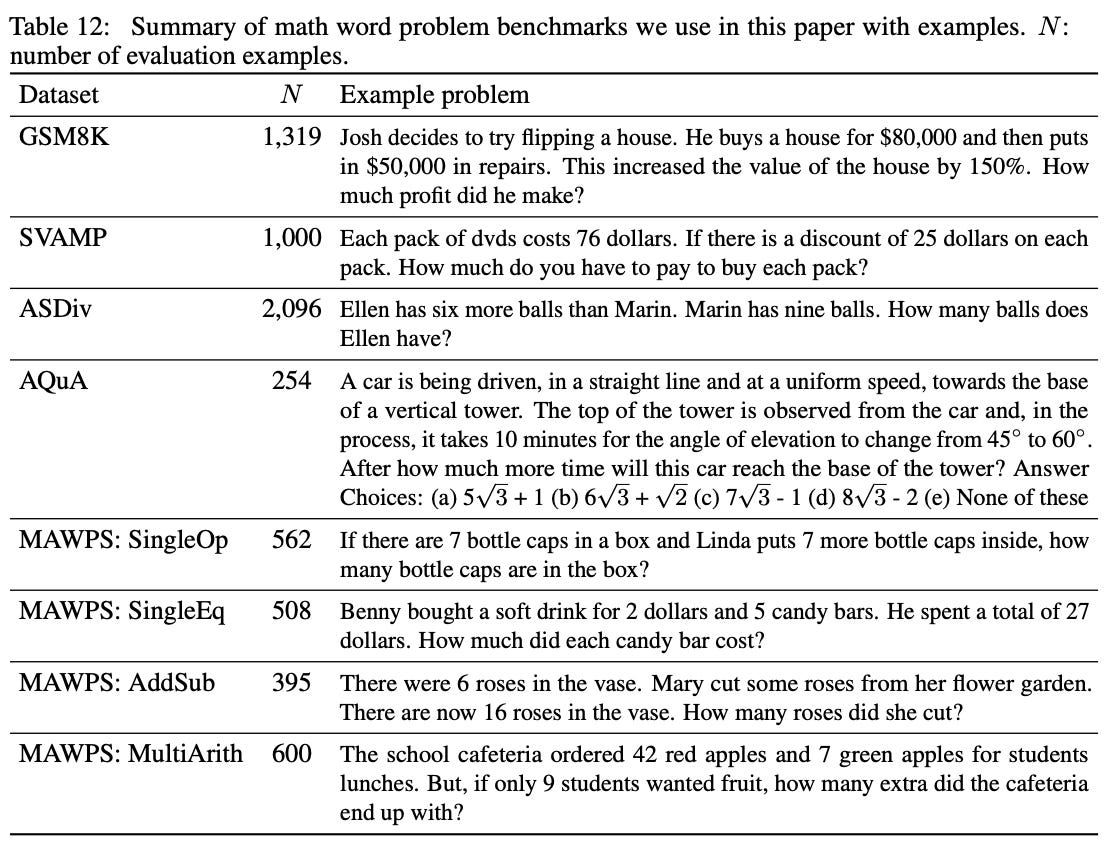
From these experiments, we discover a few notable properties of CoT prompting. First, CoT prompting seems to work much better for larger LLMs (View Highlight)
problems (e.g., GSM8K) see a greater benefit from CoT prompting. Compared to prior state-of-the-art methods (which perform task-specific fine-tuning), CoT prompting with GPT-3 and PaLM-540B achieves comparable or improved performance in all cases. (View Highlight)
commonsense reasoning.Commonsense reasoning problems assume a grasp of general background knowledge and require reasoning over physical and human interactions (View Highlight)
After the proposal of CoT prompting in [1], several variants were proposed that can improve the reasoning capabilities of LLMs (View Highlight)
prompt engineering. As demonstrated by the examples above (and the idea of CoT prompting in general), curating a useful prompt for an LLM is an art (View Highlight)
, we have seen that standard prompting is not enough to get the most out of LLMs. Rather, it seems to provide a sort of “lower bound” for LLM performance, especially on more difficult, reasoning-based tasks. CoT prompting goes beyond standard prompting techniques by leveraging few-shot learning capabilities of LLMs to elicit the generation of coherent, multi-step reasoning processes while solving reasoning-based problems. (View Highlight)

 (View Highlight)
(View Highlight) (View Highlight)
(View Highlight)