As we’re still in the early days of building applications with foundation models, it’s normal to make mistakes. This is a quick note with examples of some of the most common pitfalls that I’ve seen, both from public case studies and from my personal experience. (View Highlight)
Use generative AI when you don’t need generative AI
Every time there’s a new technology, I can hear the collective sigh of senior engineers everywhere: “Not everything is a nail.” Generative AI isn’t an exception — its seemingly limitless capabilities only exacerbate the tendency to use generative AI for everything. (View Highlight)
Confuse ‘bad product’ with ‘bad AI’
At the other end of the spectrum, many teams dismiss gen AI as a valid solution for their problems because they tried it out and their users hated it. However, other teams successfully used gen AI for similar use cases. I could only look into two of these teams. In both cases, the issue wasn’t with AI, but with product. (View Highlight)
I’ve seen this scenario over and over again. A big company wants to use generative AI to detect anomalies in network traffic. Another wants to predict upcoming customer call volume. A hospital wants to detect whether a patient is malnourished (really not recommended).
It can often be beneficial to explore a new approach to get a sense of what’s possible, as long as you’re aware that your goal isn’t to solve a problem but to test a solution. “We solve the problem” and “We use generative AI” are two very different headlines, and unfortunately, so many people would rather have the latter. (View Highlight)
Many people have told me that the technical aspects of their AI applications are straightforward. The hard part is user experience (UX). What should the product interface look like? How to seamlessly integrate the product into the user workflow? How to incorporate human-in-the-loop? (View Highlight)
UX has always been challenging, but it’s even more so with generative AI. While we know that generative AI is changing how we read, write, learn, teach, work, entertain, etc., we don’t quite know how yet. What will the future of reading/learning/working be like? (View Highlight)
Start too complex
Examples of this pitfall:
Use an agentic framework when direct API calls work.
Agonize over what vector database to use when a simple term-based retrieval solution (that doesn’t require a vectordb) works.
Insist on finetuning when prompting works.
Use semantic caching.
Given so many shiny new technologies, it’s tempting to jump straight into using them. (View Highlight)
However, incorporating external tools too early can cause 2 problems:
Abstract away critical details, making it hard to understand and debug your system.
Introduce unnecessary bugs.
Tool developers can make mistakes. (View Highlight)
Eventually, abstractions are good. But abstractions need to incorporate best practices and be tested overtime. As we’re still in the early days of AI engineering, best practices are still evolving, we should be more vigilant when adopting any abstraction. (View Highlight)
Over-index on early success
It took LinkedIn1 month to achieve 80% of the experience they wanted, and an additional 4 months to surpass 95%. The initial success made them grossly underestimate how challenging it is to improve the product, especially around hallucinations. They found it discouraging how difficult it was to achieve each subsequent 1% gain. (View Highlight)
A startup that develops AI sales assistants for ecommerce told me that getting from 0 to 80% took as long as from 80% to 90%. The challenges they faced:
• Accuracy/latency tradeoff: more planning/self-correction = more nodes = higher latency
• Tool calling: hard for agents to differentiate similar tools
• Hard for tonal requests (e.g. "talk like a luxury brand concierge") in the system prompt to be perfectly obeyed
• Hard for the agent to completely understand customers’ intent
• Hard to create a specific set of unit tests because the combination of queries is basically infinite (View Highlight)
• In the paper UltraChat, Ding et al. (2023) shared that “the journey from 0 to 60 is easy, whereas progressing from 60 to 100 becomes exceedingly challenging.” (View Highlight)
This is perhaps one of the first painful lessons anyone who has built an AI product quickly learns. It’s easy to build a demo, but hard to build a product. Other than the issues of hallucinations, latency, latency/accuracy tradeoff, tool use, prompting, testing, … as mentioned, teams also run into issues, such as:
Reliability from the API providers. A team told me that 10% of their API calls timed out. Or product’s behaviors change because the underlying model changes.
Compliance, e.g. around AI output copyrights, data access/sharing, user privacy, security risks from retrieval/caching systems, and ambiguity around training data lineage.
Safety, e.g. bad actors abusing your product, your product generates insensitive or offensive responses. (View Highlight)
Forgo human evaluation
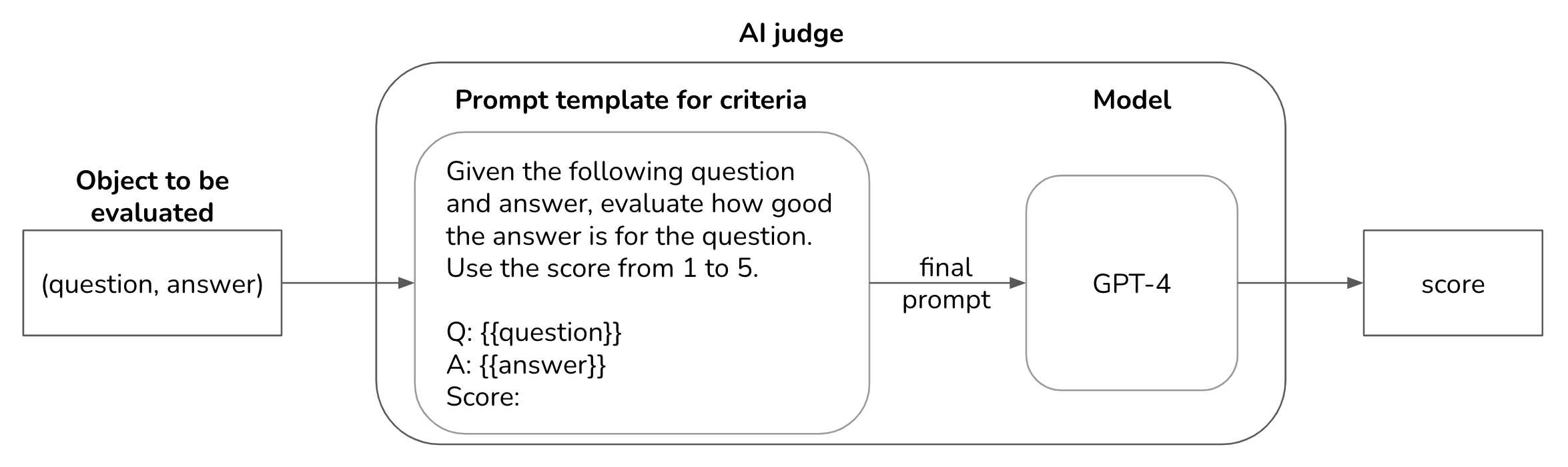
To automatically evaluate AI applications, many teams opt for the AI-as-a-judge (also called LLM-as-a-judge) approach — using AI models to evaluate AI outputs. A common pitfall is forgoing human evaluation to rely entirely on AI judges. (View Highlight)
While AI judges can be very useful, they aren’t deterministic. The quality of a judge depends on the underlying judge’s model, the judge’s prompt, and the use case. If the AI judge isn’t developed properly, it can give misleading evaluations about your application’s performance. AI judges must be evaluated and iterated over time, just like all other AI applications.
(View Highlight)
The teams with the best products I’ve seen all have human evaluation to supplement their automated evaluation. Every day, they have human experts evaluate a subset of their application’s outputs, which can be anywhere from 30 - 1000 examples. (View Highlight)
Daily manual evaluation serves 3 purposes:
Correlate human judgments with AI judgments. If the score by human evaluators is decreasing but the score by AI judges is increasing, you might want to investigate your AI judges.
Gain a better understanding of how users use your application, which can give you ideas to improve your application.
Detect patterns and changes in users’ behaviors, using your knowledge of current events, that automated data exploration might miss. (View Highlight)
The reliability of human evaluation also depends on well-crafted annotation guidelines. These annotation guidelines can help improve the model’s instructions (if a human has a hard time following the instructions, the model will, too). It can also be reused to create finetuning data later if you choose to finetune. (View Highlight)
In every project I’ve worked on, staring at data for just 15 minutes usually gives me some insight that could save me hours of headaches. Greg Brockman tweeted: “Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.” (View Highlight)
Crowdsource use cases
This is a mistake I saw in the early days when enterprises were in a frenzy to adopt generative AI. Unable to come up with a strategy for what use cases to focus on, many tech executives crowdsourced ideas from the whole company. “We hire smart people. Let them tell us what to do.” They then try to implement these ideas one by one.
And that’s how we ended up with a million text-to-SQL models, a million Slack bots, and a billion code plugins. (View Highlight)
While it’s indeed a good idea to listen to the smart people that you hire, individuals might be biased toward the problems that immediately affect their day-to-day work instead of problems that might bring the highest returns on investment. Without an overall strategy that considers the big picture, it’s easy to get sidetracked into a series of small, low-impact applications and come to the wrong conclusion that gen AI has no ROI. (View Highlight)
Use generative AI when you don’t need generative AI
Gen AI isn’t a one-size-fits-all solution to all problems. Many problems don’t even need AI.
Confuse ‘bad product’ with ‘bad AI’
For many AI product, AI is the easy part, product is the hard part.
Start too complex
While fancy new frameworks and finetuning can be useful for many projects, they shouldn’t be your first course of action.
Over-index on early success
Initial success can be misleading. Going from demo-ready to production-ready can take much longer than getting to the first demo.
Forgo human evaluation
AI judges should be validated and correlated with systematic human evaluation.
Crowdsource use cases
Have a big-picture strategy to maximize return on investment. (View Highlight)
 (View Highlight)
(View Highlight)