The diagram above depicts K-fold cross-validation with K = 5. K-fold cross-validation partitions the entire dataset into K disjoint subsets of data called folds. K independent copies of our model are trained, where for each model copy, one fold of the data is held out from its training (the data in this fold may be viewed as a validation set for this copy of the model). Each copy of the model has a different validation set for which we can obtain out-of-sample predicted probabilities from this copy of the model. Since each datapoint is held-out from one copy of the model, this process allows us to get out-of-sample predictions for every datapoint! We recommend applying stratified cross-validation, which tries to ensure the proportions of data from each class match across different folds. (View Highlight)
This method of producing out-of-sample predictions via cross-validation is also referred to as cross-validated prediction, out-of-folds predictions, and K-fold bagging. It can be easily applied to any sklearn-compatible model by invoking cross_val_predict. An additional benefit is that cross-validation produces significantly superior estimates of how the model will perform on new data. (View Highlight)

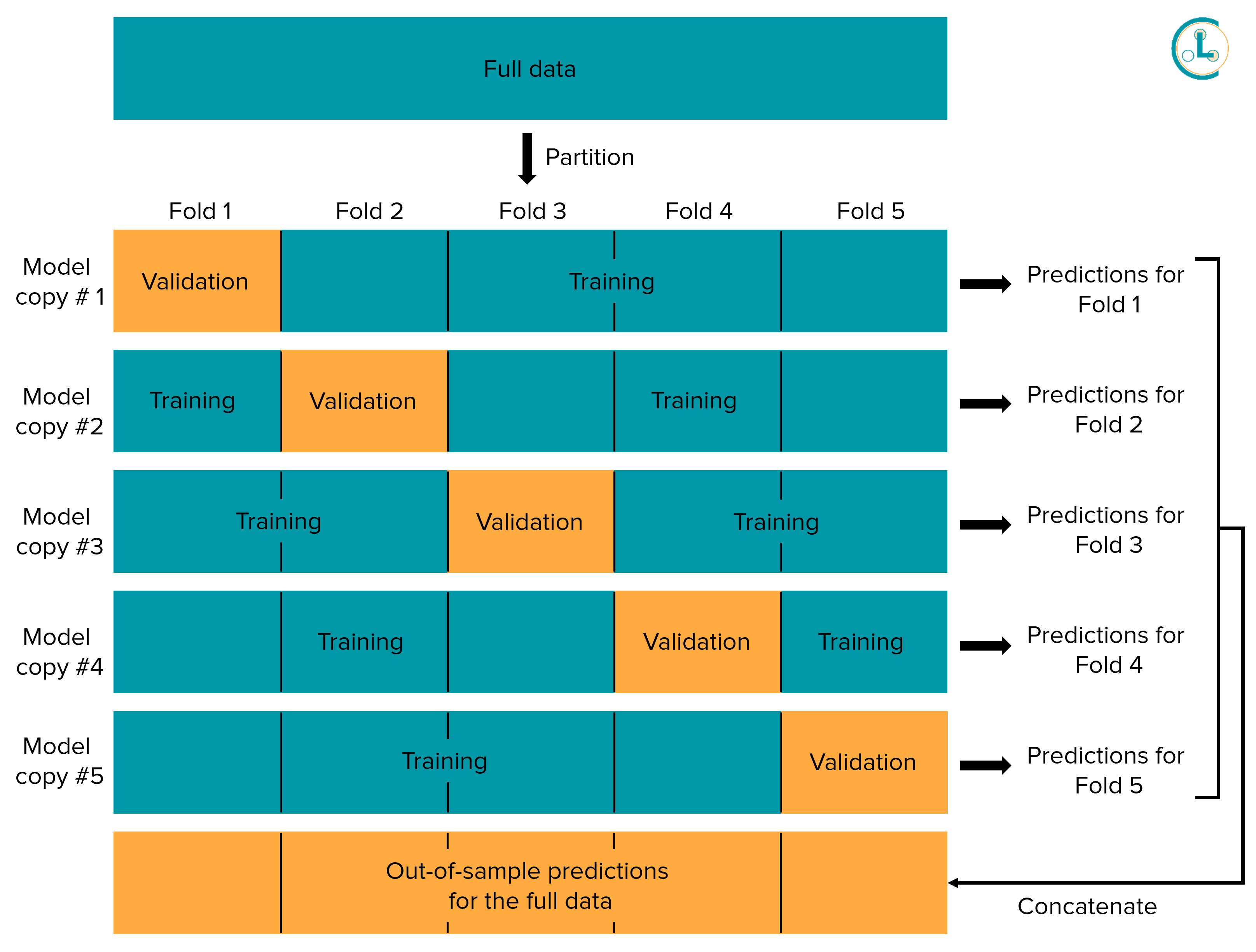 The diagram above depicts K-fold cross-validation with K = 5. K-fold cross-validation partitions the entire dataset into K disjoint subsets of data called folds. K independent copies of our model are trained, where for each model copy, one fold of the data is held out from its training (the data in this fold may be viewed as a validation set for this copy of the model). Each copy of the model has a different validation set for which we can obtain out-of-sample predicted probabilities from this copy of the model. Since each datapoint is held-out from one copy of the model, this process allows us to get out-of-sample predictions for every datapoint! We recommend applying stratified cross-validation, which tries to ensure the proportions of data from each class match across different folds. (View Highlight)
The diagram above depicts K-fold cross-validation with K = 5. K-fold cross-validation partitions the entire dataset into K disjoint subsets of data called folds. K independent copies of our model are trained, where for each model copy, one fold of the data is held out from its training (the data in this fold may be viewed as a validation set for this copy of the model). Each copy of the model has a different validation set for which we can obtain out-of-sample predicted probabilities from this copy of the model. Since each datapoint is held-out from one copy of the model, this process allows us to get out-of-sample predictions for every datapoint! We recommend applying stratified cross-validation, which tries to ensure the proportions of data from each class match across different folds. (View Highlight)