Low VRAM: For GPU with less than 8GB VRAM. It is an experimental feature. Check if you are out of GPU memory, or want to increase the number of images processed. (View Highlight)
Allow Preview: Check this to enable a preview window next to the reference image. I recommend you to select this option. Use the explosion icon next to the Preprocessor dropdown menu to preview the effect of the preprocessor. (View Highlight)
Weight: How much emphasis to give the control map relative to the prompt. It is similar to keyword weight in the prompt but applies to the control map. (View Highlight)
As you can see, Controlnet weight controls how much the control map is followed relative to the prompt. The lower the weight, the less ControlNet demands the image to follow the control map. (View Highlight)
Since the initial steps set the global composition (The sampler removes the maximum amount of noise in each step, and it starts with a random tensor in latent space), the pose is set even if you only apply ControlNet to as few as 20% of the first sampling steps. (View Highlight)
Balanced: The ControlNet is applied to both conditioning and unconditoning in a sampling step. This is the standard mode of operation.
My prompt is more important: The effect of ControlNet is gradually reducing over the instances of U-Net injection (There are 13 of them in one sampling step). The net effect is your prompt has more influence than the ControlNet.
ControlNet is more important: Turn off ControlNet on unconditioning. Effectively, the CFG scale also acts as a multiplier for the effect of the ControlNet. (View Highlight)
Copying human pose
Perhaps the most common application of ControlNet is copying human poses. This is because it is usually hard to control poses… until now! The input image can be an image generated by Stable Diffusion or can be taken from a real camera. (View Highlight)
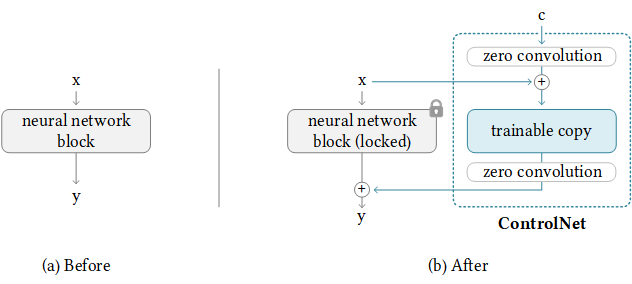
This tutorial won’t be complete without explaining how ControlNet works under the hood.
ControlNet works by attaching trainable network modules to various parts of the U-Net (noise predictor) of the Stable Diffusion Model. The weight of the Stable Diffusion model is locked so that they are unchanged during training. Only the attached modules are modified during training. (View Highlight)
The model diagram from the research paper sums it up well. Initially, the weights of the attached network module are all zero, making the new model able to take advantage of the trained and locked model.
(View Highlight)
During training, two conditionings are supplied along with each training image. (1) The text prompt, and (2) the control map such as OpenPose keypoints or Canny edges. The ControlNet model learns to generate images based on these two inputs.
Each control method is trained independently. (View Highlight)

 (View Highlight)
(View Highlight)