Web pages have a fundamentally simple structure, with semantics that allow the browser to interpret the same content differently for different people based on their own needs and preferences. This is a big part of what we think makes the Web special, and what enables the browser to act as a user agent, responsible for making the Web work for people. (View Highlight)
This is particularly useful for assistive technology such as screen readers, which are able to work alongside browser features to reduce obstacles for people to access and exchange information. For static web pages, this generally can be accomplished with very little interaction from the site, and this access has been enormously beneficial to many people. (View Highlight)
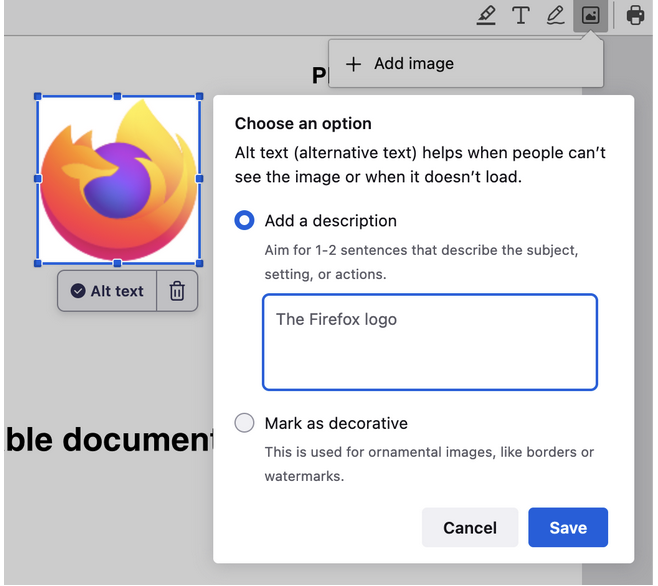
But even for a simple static page there are certain types of information, like alternative text for images, that must be provided by the author to provide an understandable experience for people using assistive technology (as required by the spec). Unfortunately, many authors don’t do this: the Web Almanac reported in 2022 that nearly half of images were missing alt text. (View Highlight)
Until recently it’s not been feasible for the browser to infer reasonably high quality alt text for images, without sending potentially sensitive data to a remote server. However, latest developments in AI have enabled this type of image analysis to happen efficiently, even on a CPU. (View Highlight)
We are using Transformer-based machine learning models to describe images. These models are getting good at describing the contents of the image, yet are compact enough to operate on devices with limited resources. While can’t outperform a large language model like GPT-4 Turbo with Vision, or LLaVA, they are sufficiently accurate to provide valuable insights on-device across a diversity of hardware. (View Highlight)
Model architectures like BLIP or even VIT that were trained on datasets like COCO (Common Object In Context) or Flickr30k are good at identifying objects in an image. When combined with a text decoder like OpenAI’s GPT-2, they can produce alternative text with 200M or fewer parameters. Once quantized, these models can be under 200MB on disk, and run in a couple of seconds on a laptop – a big reduction compared to the gigabytes and resources an LLM requires. (View Highlight)
Firefox Translations uses the Bergamot project powered by the Marian C++ inference runtime. The runtime is compiled into WASM, and there’s a model file for each translation task. (View Highlight)
We’ve decided to embed the ONNX runtime in Firefox Nightly along with the Transformers.js library to extend the translation architecture to perform different inference work. (View Highlight)
Like Bergamot, the ONNX runtime has a WASM distribution and can run directly into the browser. The ONNX project has recently introduced WebGPU support, which will eventually be activated in Firefox Nightly for this feature. (View Highlight)
Transformers.js provides a Javascript layer on top of the ONNX inference runtime, making it easy to add inference for a huge list of model architectures. The API mimics the very popular Python library. It does all the tedious work of preparing the data that is passed to the runtime and converting the output back to a usable result. It also deals with downloading models from Hugging Face and caching them. (View Highlight)