Metadata
- Author: The Outerbounds Team
- Full Title: How to Organize Continuous Delivery of ML/AI Systems: A 10-Stage Maturity Model
- URL: https://outerbounds.com/blog/continuous-delivery-of-ml-ai/
Highlights
- Every production-oriented ML/AI team grapples with the same challenge: how to work with data, code, and models effectively so that projects are readily deployable to production. (View Highlight)
- he challenge is not new. If you ignore the data and models part, software engineers have been facing and addressing the challenge for decades. Best practices and processes for doing this effectively are often found under the moniker Continuous Delivery (CD) which is concisely defined at continuousdelivery.com:
Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way. (View Highlight)
- Consider these three core challenges that are endemic in ML, AI, and data projects:
- Development and debugging cycles are more tedious due to computational requirements of models and data processing. Specialized hardware like GPUs pose extra challenges for dependency management, cause tricky cross-platform issues, and create gaps between development and production environments.
- Data introduces entropy - systems that deal with constantly changing data are less predictable, and hence inherently harder to make reproducible and debuggable than traditional software that has smaller surface area against the outside world.
- It is hard to ascertain that ML/AI systems work correctly. A key tenet of continuous delivery is to follow a process, such as rigorous testing and manual reviews, to ensure that changes don’t cause breakage. In the case of ML/AI, ensuring correctness often happens empirically over time after the deployment, not before:
 (View Highlight)
(View Highlight)
- We have observed problems, solutions, and best practices for CD at hundreds of advanced ML/AI organizations that we have worked with. It is clear that every organization is different - there isn’t a cookie-cutter approach that works as such for all - but the following four building blocks seem foundational in all successful CD implementations:
0. Embrace GitOps: As a baseline, you should follow all the existing GitOps best practices from pull requests to automated testing. When it comes to CD for ML/AI, this is necessary but not sufficient.
- Scalable compute built-in, from prototype to production: To address the compute requirements, we provide compute-optimized cloud workstations, coupled with a scalable, multi-cloud compute backend out of the box - as well as solutions for dependency management and specialized hardware like GPUs and other accelerators.
- First-class support for data, artifacts, and change management: To tame the entropy, Outerbounds provides various tools that help dealing with real-world data securely, as well as managing state and change with minimal overhead.
- Isolated, flexible, secure environments: Since one can’t ascertain the quality and correctness of every model and deployment in advance, we make it possible create isolated environments and deployments which allow you to experiment safely and test new approaches without interfering with production. This helps with compliance too in scenarios where production deployments are under high scrutiny, or projects must be kept isolated from each other. (View Highlight)
- This is a familiar baseline in many ML/AI projects. You have a few developers, like Alex and Avery below, hacking code locally on their laptops or maybe cloud-based notebooks like Google Colab or Amazon Sagemaker Studio, accessing data from a common data store:
 (View Highlight)
(View Highlight) - Notebooks are convenient for exploratory data analysis and as a quick scratchpad for code snippets. When it comes to developing production-ready code, it is beneficial to use a full-fledged IDE like VSCode, which allows you to develop modular, idiomatic Python projects - including Metaflow flows - while following GitOps best practices. (View Highlight)
- The Stage 1 resembles a typical setup in traditional software engineering: Developers hack code on their laptops, checking in code to Git periodically to keep track of changes. In projects involving ML, AI, and data improvements happen not only through changes in the code but also in changing data, models, and configuration. Keeping track of these changes and their impact becomes critical. (View Highlight)
- Many tools and services, such as MLFlow, Weights and Biases, and Comet, have emerged to address this need, often categorized as experiment tracking. They provide a layer of metadata that keeps track of models, metrics, and other artifacts produced as Alex and Avery develop their projects:
 (View Highlight)
(View Highlight) - Since keeping track of code, data, models - as well as the state of systems in general - is such a fundamental part of ML/AI projects, it is beneficial to consider it as an integral part of the systems we build, not as a separate add-on. Metaflow takes this approach by recording, persisting, and versioning the full state of the workflow automatically, so you can observe any part of your system, not just models or specific pieces of data, consistently across experimentation and production, as shown in this quick example: As shown in the video, you can also present the data tracked through custom, real-time visualizations which are easily viewable in the UI. (View Highlight)
- What happens if Alex needs to load a dataframe that doesn’t fit in the memory of their workstation, or Avery wants to fine-tune a set of LLMs on beefy GPUs? In scenarios like this, which are very common in ML/AI projects, developers need access to scalable compute resources outside their personal development environment - the more quickly and frictionlessly the better.
 (View Highlight)
(View Highlight) - In the past, ML developers and data scientists were often required to learn a new paradigm, rewrite their code, and move to a different set of libraries - say, to move from Python to Spark - to test things at scale, severely slowing down development cycles and creating a massive gap in the delivery process. (View Highlight)
- Developers working concurrently can inadvertently interfere with each other’s work. For instance, consider two experiments running in parallel, both writing results to the same file or a database table. (View Highlight)
- The challenge is amplified by shared compute pools, as workloads execute outside the confines of personal workstations. It is hard to achieve repeatable, worry-free continuous delivery, if there’s a chance of developers stepping on each other’s toes. Preferably, all developers would stay on their own swimlane by default - without fear of interference - while making it easy to collaborate whenever opportunities arise. (View Highlight)
- Metaflow organizes all data, code, and models automatically under namespaces. A developer can safely develop their code as if no other developers existed, but accessing a colleague’s results is just a matter of switching the namespace: Besides namespaces, Metaflow allows you to organize results with user-defined tags which make it possible to define various human-in-the-loop processes, for instance, to approve models before deployment. (View Highlight)
- The stages 1-4 ensure that developers are able to develop and test their projects, even at scale, and collaborate effectively. This establishes a robust foundation for development of production-grade ML/AI projects.
An absolute requirement for production deployments are stable execution environments, that is, careful management of all software dependencies that are required to execute the code. Problems arise if there’s a mismatch between the development and production environments. Preferably, one would use exactly the same environment from prototyping to production.
A popular solution is to use container (Docker) images. This is a perfectly valid solution but it brings up additional challenges:
• Are data scientists and other developers supposed to maintain their own images? This is a non-trivial challenge by itself.
• How to handle change management for images, say, Alex wants to update the version of
torch(the yellow boxes in the image) but Avery wants to keep an older version (the orange boxes)? • What should be included in the image? Certainly it is not convenient to bake a new image every time the code or configuration changes. • How to manage the whole software supply chain, ensuring that images don’t contain security vulnerabilities? (View Highlight) - To enable stable, consistent environments between development and production, without hindering the speed of iteration, Metaflow provides built-in support for dependency management. This video shows Metaflow’s three main mechanisms for defining stable environments for cloud execution:
Starting from the simplest pattern,
- Metaflow packages the user code automatically, including any custom modules and packages.
- It provides
@pypiand@condadecorators which can be used to include 3rd party dependencies safely, without having to manage container images manually. - Finally, to enable arbitrarily advanced cases, Metaflow allows you to use custom images - just specify
@kubernetes(image=). (View Highlight)
- Stage 6: Deployments via CI/CD
While one-click deployments are convenient, many organizations prefer to follow a more rigorous GitOps process where production deployments are done through a CI/CD system, such as GitHub Actions.
 Using a CI/CD system provides a number of benefits over Stage 5: (View Highlight)
Using a CI/CD system provides a number of benefits over Stage 5: (View Highlight) - • You can define arbitrary gates and policies, such as code reviews or automated tests, which must be passed before a deployment can commence. • Only the CI/CD system needs to access the production environment directly, making it more secure and protected from inadvertent actions. • You get a clear audit trail of deployments in the CI/CD system. (View Highlight)
- This illustration outlines a typical path from development environment to production on Outerbounds, when including a CI/CD system like GitHub Actions:
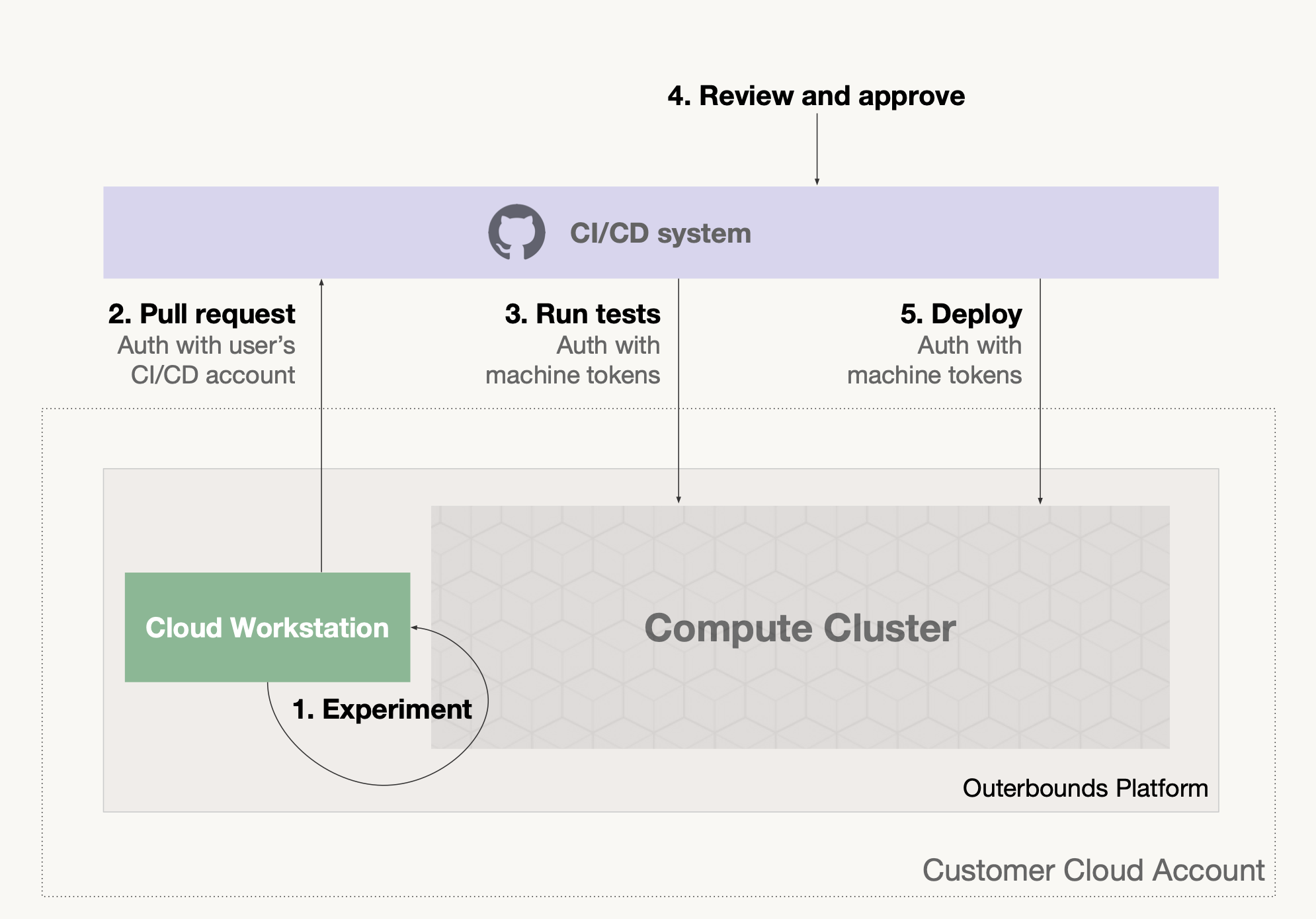 (View Highlight)
(View Highlight) - Crucially, the arrows 4 and 5, test execution and deployments, require GitHub Actions to communicate with the platform which is enabled via secure machine tokens. The beginning of this video shows how to set up GitHub Actions for Outerbounds, and the rest of the video goes through the path illustrated above:
At this stage, you are able to
- Experiment locally, running code at scale if needed.
- Commit changes to GitHub, which triggers a test execution.
- If the test execution passes, the flow is deployed to production. (View Highlight)
- Stage 6 is getting close to the continuous delivery nirvana. For small teams with a handful of projects it may be a perfectly sufficient setup.
However, if your use cases are business or security-critical, the setup may be lacking, as experiments, tests, and production executions exist in the same environment with the same set of permissions. In particular, for data governance reasons you may need to limit access to production data only to production systems and let experiments access only test data. Or, you may want to limit the compute resources available to experimentation.
 (View Highlight)
(View Highlight) - Outerbounds provides a core feature called a perimeter which allows you to create separate environments, such as staging and production, each with a different set of policies and permissions, like IAM permissions, container policies, and compute resources policies shown here: Through this mechanism, you can grant access to production tables, say in a Snowflake database, only to production perimeters, and let staging access other tables. Or, you can require that all container images used in production must come from a trusted registry. (View Highlight)
- A killer feature in many mature continuous delivery platforms, like Vercel that targets web applications, is the ability to create multiple parallel deployments, say, one for each pull request. This allows the developer to eyeball changes in a real environment before promoting their branch to production.
As we mentioned in the beginning, ascertaining the quality of ML/AI branches is less straightforward - you can’t just eyeball the results quickly. Instead, you may have to leave the branch running side-by-side with the current production, A/B testing the new version against the existing production version over time.
 (View Highlight)
(View Highlight) - Stage 9: Isolated, secure environments
In a large organization, it is not only Alex and Avery working on ML/AI but they have potentially hundreds of colleagues, spread across various lines of business. Each team is responsible for their own products and services, and hence they need their own isolated staging and production environments. In other words, the organization needs multiple copies of Stage 8, each with their own set up and policies.
The organization may be distributed over multiple jurisdictions, so often it is critical that the environments are securely isolated from each other. To complicate things further, the teams may require different technical resources.
For instance, in the illustration below, Blake and Casey may need the latest TPU accelerators from the Google Cloud for their compute vision project, whereas Alex and Avery use the company’s main AWS account.
 (View Highlight)
(View Highlight) - Finally, what sets a trailblazing tech company like Netflix, Google, or Meta apart from other large organizations? Similar to any large organization, they have myriads of teams and products with diverse needs.
They operate massive-scale shared platforms, compute in particular, on top of which each line of business can build solutions and workflows matching their requirements. This affords them benefits of scale, including higher utilization of compute resources in contrast to siloed deployments. As a result, the cost of compute is decreased and more resources can be made available to every team.
 (View Highlight)
(View Highlight)