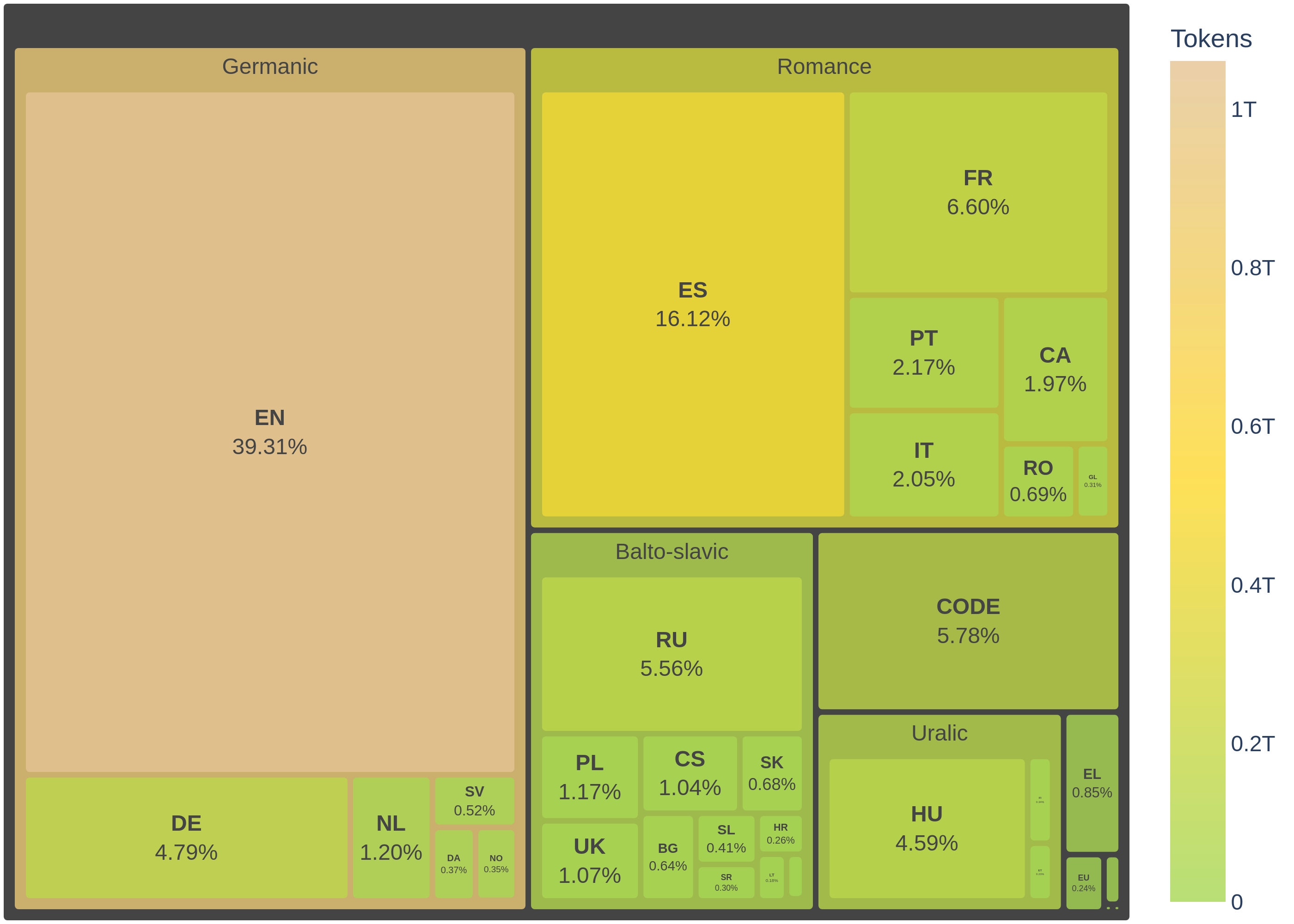
The pre-training corpus comprises data from 35 European languages and 92 programming languages, with detailed data sources provided below. The initial 1.5 training epochs used 2.4 trillion tokens, obtained by manually adjusting data proportion to balance the representation and give more importance to Spain’s co-official (Spanish, Catalan, Galician, and Basque). This way, we downsampled code and English data to half, Spanish co-official languages were oversampled by 2x, and the remaining languages were kept in their original proportions. (View Highlight)
during the following epochs (still training), the Colossal OSCAR dataset was replaced with the FineWebEdu dataset. This adjustment resulted in a total of 2.68 trillion tokens, distributed as outlined below:
(View Highlight)
The pretraining corpus is predominantly composed of data from Colossal OSCAR, which contributes a significant 53,05% of the total tokens. Following this, Starcoder provides 13,67%, and FineWebEdu (350B tokens subset) adds 10,24%. The next largest sources are HPLT at 4,21% and French-PD at 3,59%. Other notable contributions include MaCoCu, Legal-ES, and EurLex, each contributing around 1.72% to 1.41%. These major sources collectively form the bulk of the corpus, ensuring a rich and diverse dataset for training the language model. (View Highlight)
We evaluate on a set of tasks taken from SpanishBench, CatalanBench, BasqueBench and GalicianBench. We also use English tasks already available on the LM Evaluation Harness. These benchmarks include both new and existing tasks and datasets. In the tables below, we include the results in a selection of evaluation datasets that represent model’s performance across a variety of tasks within these benchmarks. (View Highlight)

 (View Highlight)
(View Highlight)