tl;dr Metaflow is an extensible ML orchestration framework that can interoperate with Ray.io. We collaborated with Outerbounds in developing a @ray_parallel decorator to seamlessly run Ray applications within Metaflow flows, leveraging AWS Batch and Ray for distributed computing. We successfully battle-tested this extension through applying many different Ray use cases, including fine-tuning an LLM using Ray Train. This collaboration enhances Metaflow’s distributed computing capabilities, allowing users to leverage Ray’s features within their Metaflow flows. (View Highlight)
Although Metaflow can be leveraged by Data Scientists and Machine Learning Engineers across the entire ML stack, we will be focusing strictly on its compute layer. As of August 2023, Metaflow offers two distinct options for its compute layer today: AWS Batch, a managed AWS service that facilitates autoscaling through ECS and container-based jobs, and Kubernetes. Metaflow makes it trivial for us to access an incredibly large amount of compute on AWS Batch for our ML workloads — allowing our data scientists to be fully self-served. We have been very pleased with how simple yet robust Metaflow has proven to be. A key consideration for us has always been the remarkable adaptability of Metaflow, especially in handling the challenges associated with distributed training of large-scale models. As such, we wanted to work on ensuring that it was sufficiently future-proof for our AI needs by integrating it with other frameworks in the space. (View Highlight)
Ray is an open source distributed computing framework that has gained a lot of traction in recent years, particularly due to its substantial role in training ChatGPT. Its primary utility lies in accelerating and streamlining ML workloads and training tasks, and it provides a scalable and efficient platform for large-scale data processing. Ray is a massive framework with a lot of bells and whistles that cover many facets of the end-to-end ML workflow. Some of its capabilities include :
• Ray Core: serves as the foundation of the entire Ray ecosystem. It provides the building blocks for developing distributed computing applications and functions
• Ray Train: a module dedicated towards distributed training of ML models enabling users to leverage distributed data parallelism and other distributed training techniques. It supports popular ML frameworks such as Tensorflow, PyTorch, and HuggingFace
• Ray Tune: a library geared towards streamlining and distributing the process of hyper-parameter tuning for ML models. It offers many search algorithms like HyperOpt and Optuna. (View Highlight)
We immediately recognized Ray’s potential as a pivotal element of our training infrastructure for distributed computing. We discovered that Ray is designed for extensibility and both Metaflow and Ray greatly complement each other. For example, AWS Batch operates at the infrastructure level, setting up the driver and workers, while Ray functions at the framework level, making efficient use of the underlying hardware. Armed with this newfound understanding and the realization that Ray could fundamentally be installed on top of AWS Batch, we endeavoured to integrate Ray with Metaflow. This integration would allow users to seamlessly run Ray applications within their Metaflow flows, creating a solution that combines the strengths of both frameworks. (View Highlight)
Distributed Computing Using Ray Orchestrated By Metaflow
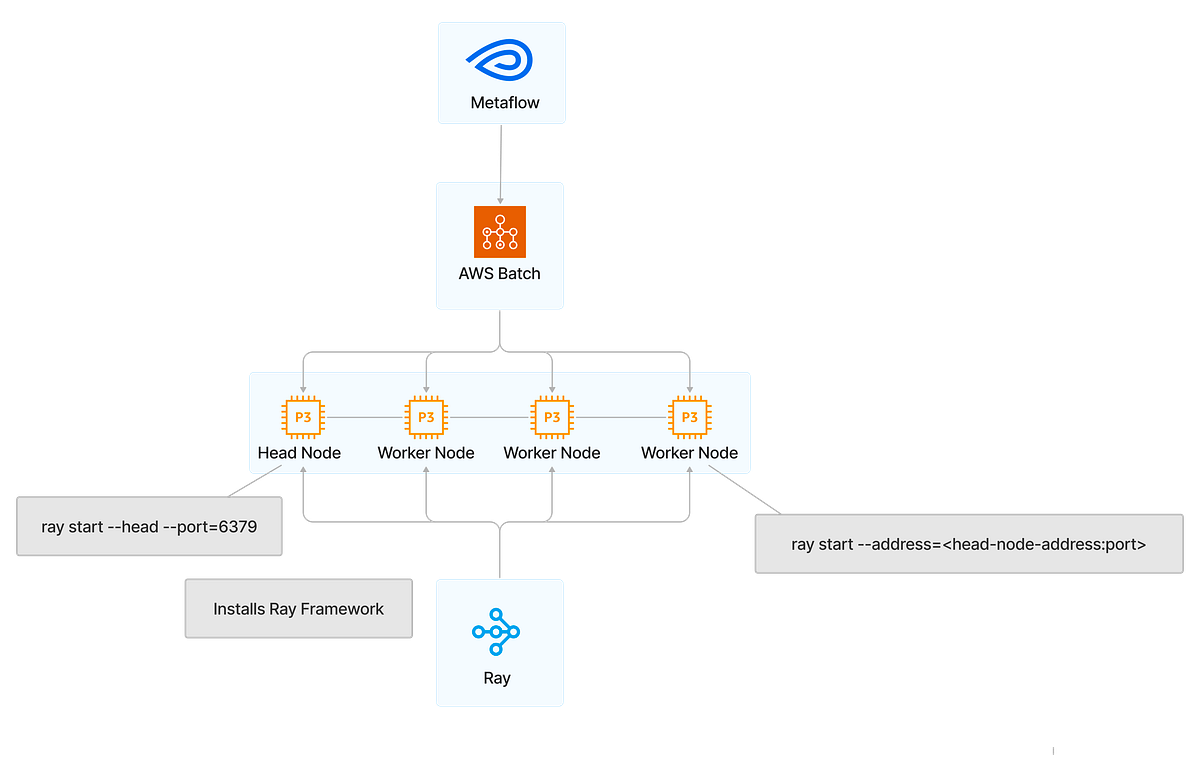
Metaflow already lays the groundwork for enabling distributed computing through gang-scheduled clusters. The [@parallel](https://github.com/Netflix/metaflow/blob/master/metaflow/plugins/parallel_decorator.py) decorator already exists in Metaflow and can be used to run remote Metaflow tasks on an AWS Batch multi-node parallel job. We collaborated with Outerbounds, the team that developed Metaflow, and worked off their existing abstractions to introduce the @ray_parallel decorator to run distributed Ray workloads.
Using @ray_parallel , Metaflow initiates the underlying hardware for the cluster components using AWS Batch multi-node. Subsequently, users can then embed their Ray code within a Metaflow step. At runtime, Metaflow will automatically launch a transient Ray cluster, run the Ray application specified in the Metaflow @ray_parallel task, and then tear down the cluster automatically upon completion of the @ray_parallel task.
Our implementation of the @ray_parallel decorator does all the underlying setup for installing Ray on an on-premise cluster discussed in the docs here. A setup_distributed_env method extends the base @parallel decorator’s functionality and ensures that a ray start command is executed for the head node on the @ray_parallel control task. Correspondingly, each of the worker nodes runs the ray start command to connect to the head node, which forms the Ray cluster. (View Highlight)
We made some other considerations while developing @ray_parallel , particularly to enhance the user experience. Most prominently, one challenge we discovered was that the worker nodes created by AWS Batch multi-node parallel jobs would prematurely terminate without coordinating with the head node upon receiving a ray application to execute. For instance, when a user submits their training code to the control task within the Metaflow step, the AWS Batch worker nodes themselves would have nothing to execute, so they complete their tasks prematurely and exit the Ray cluster. To address this challenge, it became necessary to ensure that the worker nodes stayed alive and could communicate with the head node to determine when to complete their respective tasks. (View Highlight)
We made sure to test the @ray_parallel decorator rigorously across a wide variety of different Ray applications, including distributed training of an XGBoost model, fine-tuning the GPT-J 6 Billion parameter model, and hyper-parameter tuning with Ray Tune. For fine-tuning an LLM, we reproduced this example from the Ray docs. Here is what we did to set this example up on Metaflow.
We install metaflow-ray via pip which gives us access to the @ray_parallel decorator.
pip install metaflow-ray
We then import @ray_parallel
from metaflow import ray_parallel
We then use Metaflow’s[for_each](https://docs.metaflow.org/metaflow/basics#foreach) to specify the number of Ray workers we intend to have in our Ray cluster, and then we decorate our train step with @ray_parallel . The example in the Ray docs used 16 nodes, so we do the same. (View Highlight)
One very neat thing is we can also leverage Metaflow’s means of handling external dependencies through the @conda decorator, and these packages will propagate to the Ray workers as well, in addition to the rest of the feature set that Metaflow offers.
Upon executing this flow, 16 g5.4xlarge instances were provisioned by Metaflow to form the Ray cluster. Our test used a batch size of 16, so the effective batch size was 256 across all 16 nodes — the training job was completed in just under 50 minutes, not including initialization time and checkpoint synchronization. Ray makes checkpointing a breeze, so all we needed to do was set an S3 uri as a Metaflow parameter and feed this into Ray’s HuggingFace Trainer. We used the Metaflow GUI to monitor the Ray training job and track execution time. We found the UI very useful for displaying and collating the logs outputted by the Ray workers. We could even take advantage of Metaflow’s @card decorator to plot some gpu profiling visualizations to the UI. (View Highlight)
The integration between Metaflow and Ray has long been on the wishlists of many in the Metaflow user community. We are very proud to release this experimental extension as an enhancement to Metaflow’s distributed computing capabilities and to open up boundless possibilities for users to run their own Ray applications that are orchestrated by Metaflow. This work would not have been possible without the collaboration between our team, the team at Outerbounds, and the team at Anyscale. We invite anyone to give the @ray_parallel decorator a try and provide any comments or feedback. (View Highlight)