![]()
Metadata
-
Author: a Database guy
-
Full Title: The Birth of chDB
-
Document Note: In “The Birth of chDB,” a database expert shares insights on the development of a Python module that seamlessly integrates the powerful ClickHouse engine, designed to enhance performance and usability for data-intensive applications. With significant optimizations, including a 50% reduction in memory usage and the implementation of zero-copy retrieval techniques, chDB aims to provide an elegant solution for Python users needing efficient access to large datasets. This innovative project not only simplifies the interaction with ClickHouse but also outperforms traditional setups, demonstrating its potential to revolutionize data processing in Python environments.
Highlights
- In February 2023, I started developing chDB with the main goal of making the powerful ClickHouse engine available as an “out-of-the-box” Python module. ClickHouse already has a standalone version called
clickhouse-localthat can be run from command line independently; this makes it even more feasible for chDB. (View Highlight) - Actually, there is a very simple and straightforward implementation: directly include the
clickhouse-localbinary in the Python package, and then pass SQL to it through something likepopen, retrieving the results through a pipe. (View Highlight) 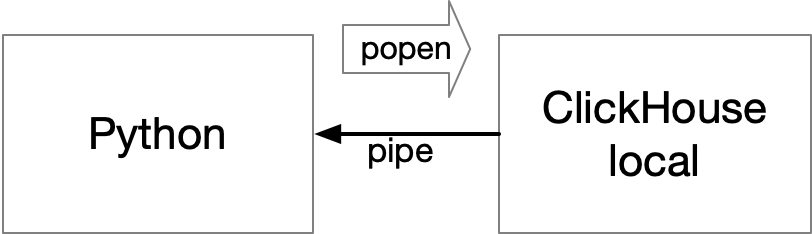 However, this approach brings several additional problems:
However, this approach brings several additional problems:
- Starting an independent process for each query would greatly impact performance, especially when the
clickhouse-localbinary file is approximately 500MB in size. - Multiple copies of SQL query results are inevitable.
- Integration with Python is limited, making it difficult to implement Python UDFs and support SQL on Pandas DataFrame.
- Most importantly, it lacks elegance 😎 (View Highlight)
- Starting an independent process for each query would greatly impact performance, especially when the
- ClickHouse includes a series of implementations called
BufferBase, includingReadBufferandWriteBuffer, which correspond roughly to C++’sistreamandostream. In order to efficiently read from files and output results (e.g., reading CSV or JSONEachRow and outputting SQL execution results), ClickHouse’s Buffer also supports random access to underlying memory. It can even create new Buffers based on vector without copying memory. ClickHouse internally uses derived classes ofBufferBasefor reading/writing compressed files as well as remote files (S3, HTTP). (View Highlight) - To achieve zero-copy retrieval of SQL execution results at the ClickHouse level, I used the built-in
WriteBufferFromVectorinstead of stdout for receiving data. This ensures that parallel output pipelines won’t be blocked while conveniently obtaining the original memory blocks of SQL execution outputs. (View Highlight) - To avoid memory copying from C++ to Python objects, I utilized Python’s
memoryviewfor direct memory mapping.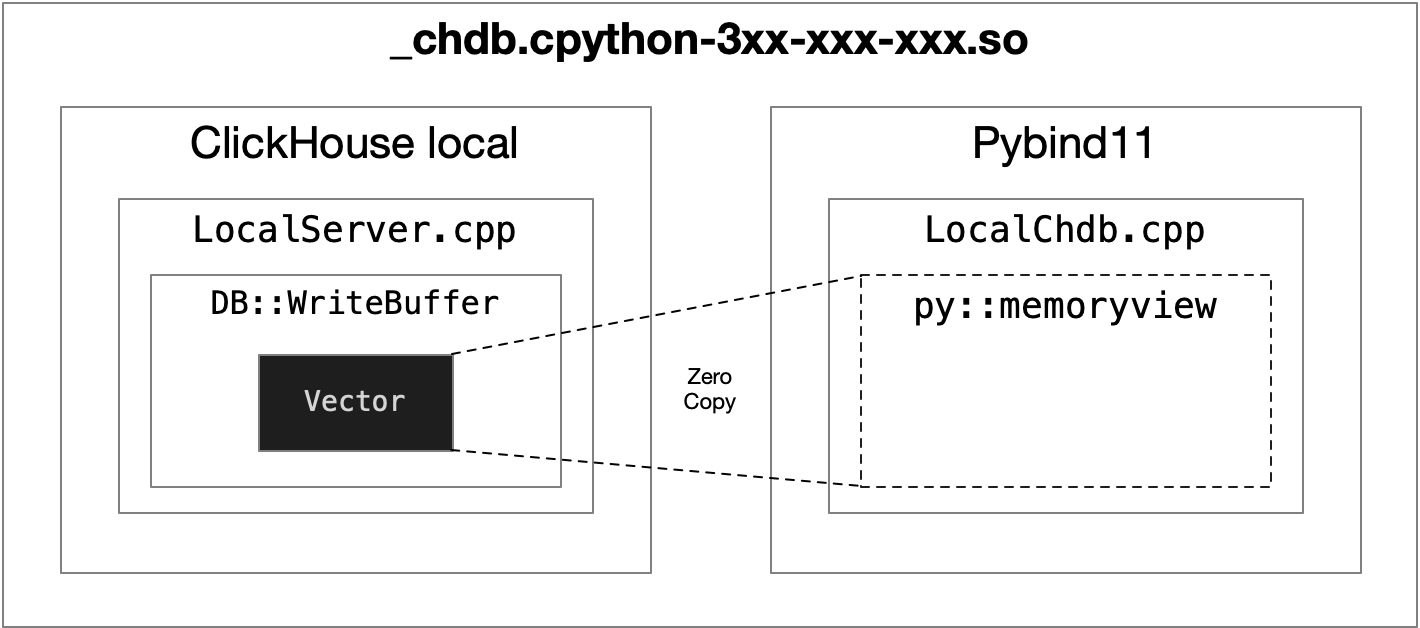 (View Highlight)
(View Highlight) - In this way, chDB can basically be up and running, and I am very excited to release it. The architecture of chDB is roughly depicted in the following diagram:
 (View Highlight)
(View Highlight) - Initially, I developed chDB with the sole purpose of creating a ClickHouse engine that could run independently in Jupyter Notebook. This would allow me to easily access large amounts of annotation information without having to rely on slow Hive clusters when training CV models using Python. Surprisingly, the standalone version of chDB actually outperformed the Hive cluster consisting of hundreds of servers in most scenarios. (View Highlight)
- After carefully analyzing chDB’s performance in Clickbench, it was found that there is a significant performance gap between chDB and clickhouse-local in Q23. It is believed that this difference is due to the fact that when implementing Q23, chDB simplified the process by removing jemalloc. Let’s fix it! (View Highlight)
- ClickHouse engine includes hundreds of submodules, including heavyweight libraries such as Boost and LLVM (View Highlight)
- In order to ensure good compatibility with libc and libc++ and implement JIT execution engine, ClickHouse links with its own version of LLVM as the libc used for linking. The binary of ClickHouse can easily guarantee overall link security. However, for chdb as a shared object (so), this part becomes exceptionally challenging due to several reasons:
- Python runtime has its own libc. After loading chdb.so, many memory allocation & management functions that should have been linked to jemalloc in ClickHouse binary will unavoidably be connected to Python’s built-in libc through @plt.
- To solve the above problem, one solution is modifying ClickHouse source code so that all relevant functions are explicitly called with
je_prefix, such asje_malloc,je_free. But this approach brings two new problems; one of which can be easily solved: - Modifying third-party library’s malloc calling code would be a huge project. I used a trick when linking with clang++:
-Wl,-wrap,malloc. For example, during the linking phase, all calls to malloc symbol are redirected to__wrap_malloc. You can refer to this piece of code in chDB: mallocAdapt.c (View Highlight)
- Through several weeks of effort on ClickHouse and jemalloc, the memory usage of chDB has been significantly reduced by 50%. According to the data on ClickBench, chDB is currently the fastest stateless and serverless database(not including ClickHouse Web) (View Highlight)
- reconstruction based on the latest ClickHouse 23.6 version. It is expected that the performance on Parquet will improve once this version becomes stable. We are also closely collaborating with the ClickHouse team in the following areas:
- Reducing the overall size of the chDB installation package as much as possible (currently compressed to around 100MB, and we hope to slim it down to 80MB this year)
- Supporting Python UDF (User-Defined Functions) and UDAF (User-Defined Aggregate Functions) for chDB
- chDB already supports using Pandas Dataframe as input and output, and we will continue optimizing its performance in this area. (View Highlight)