Here’s what most resources/tutorials mention about Dropout:
• Zero out neurons randomly in a neural network. This is done to regularize the network.
• Dropout is only applied during training, and which neuron activations to zero out (or drop) is decided using a Bernoulli distribution:
“p” is the dropout probability specified in, say, PyTorch → nn.Dropout(p).
Of course, these details are correct.
But this is just 50% of how Dropout works. (View Highlight)
How Dropout actually works?
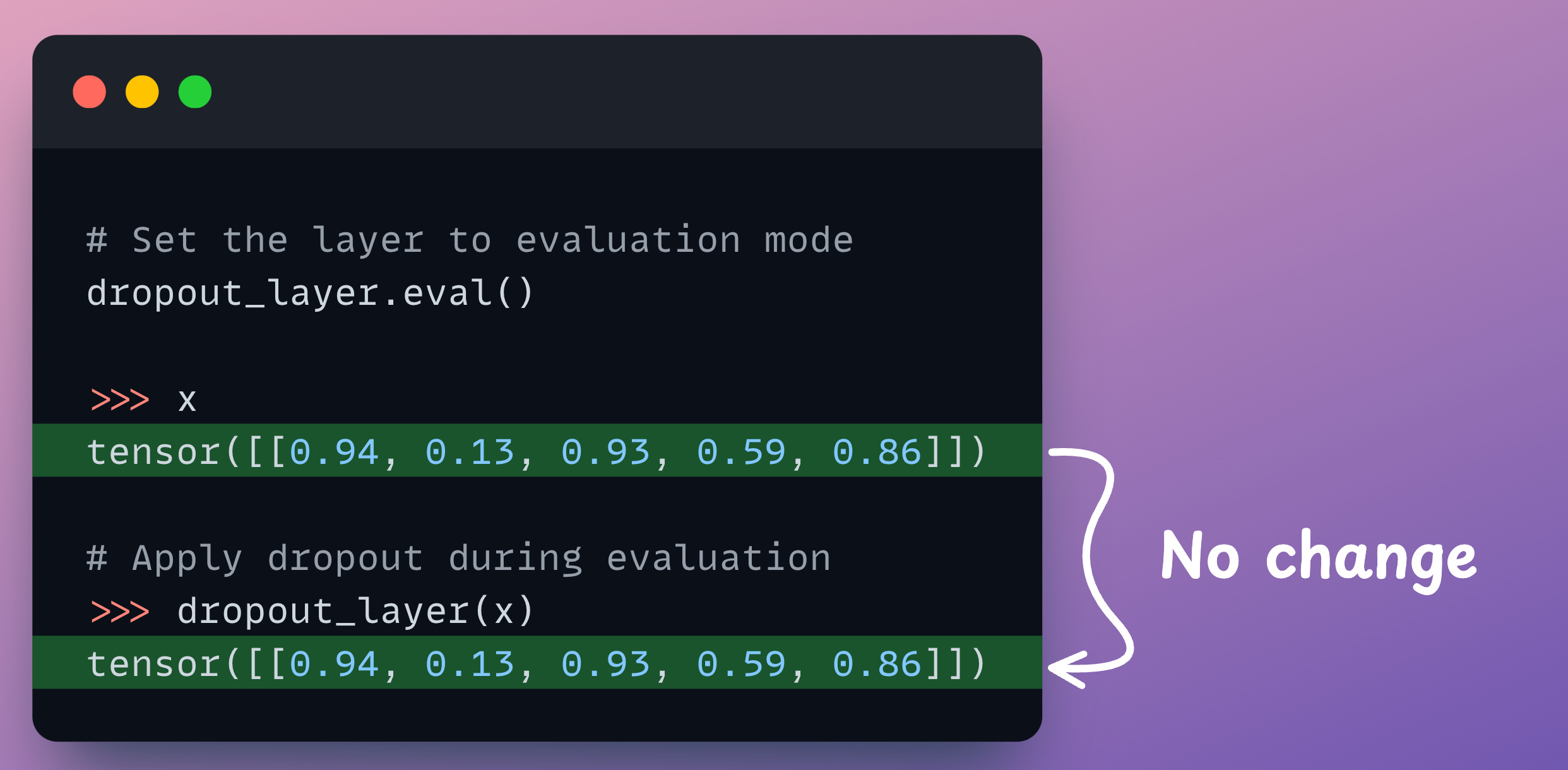
To begin, we must note that Dropout is only applied during training, but not during the inference/evaluation stage:
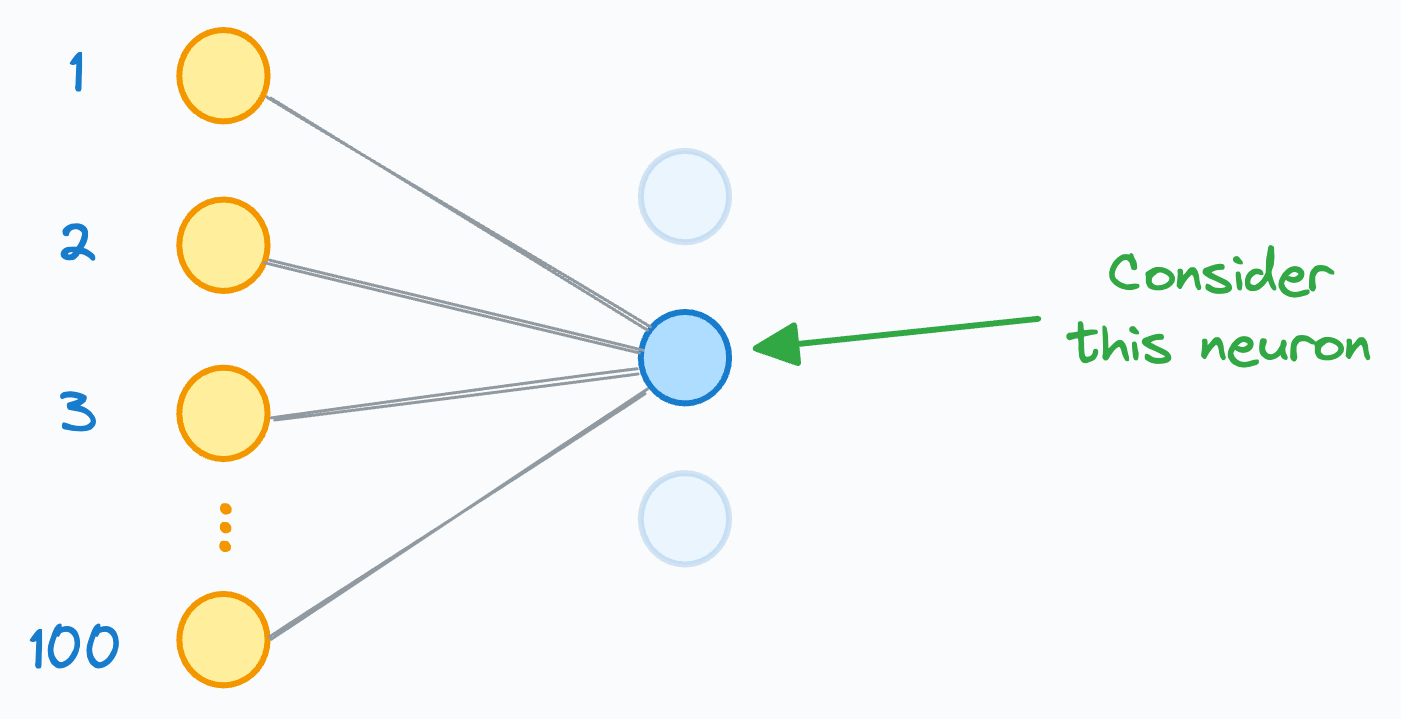
Now, consider that a neuron’s input is computed using 100 neurons in the previous hidden layer:
(View Highlight)
During training, the average neuron inputs are significantly lower than those received during inference. (View Highlight)
More formally, using Dropout significantly affects the scale of the activations.
However, it is desired that the neurons throughout the model must receive the roughly same mean (or expected value) of activations during training and inference.
To address this, Dropout performs one additional step.
This idea is to scale the remaining active inputs during training.
The simplest way to do this is by scaling all activations during training by a factor of 1/(1-p), where p is the dropout rate.
For instance, using this technique on the neuron input of 60, we get the following (recall that we set p=40%):
As depicted above, scaling the neuron input brings it to the desired range, which makes training and inference stages coherent for the network. (View Highlight)
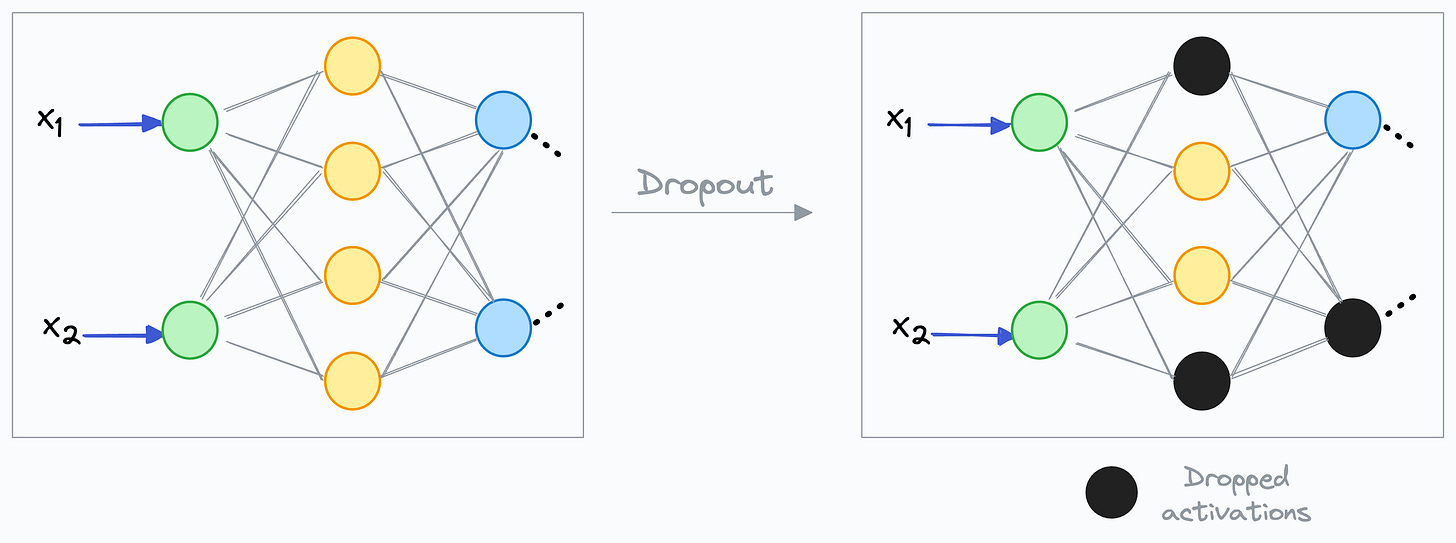 • Dropout is only applied during training, and which neuron activations to zero out (or drop) is decided using a Bernoulli distribution:
• Dropout is only applied during training, and which neuron activations to zero out (or drop) is decided using a Bernoulli distribution:
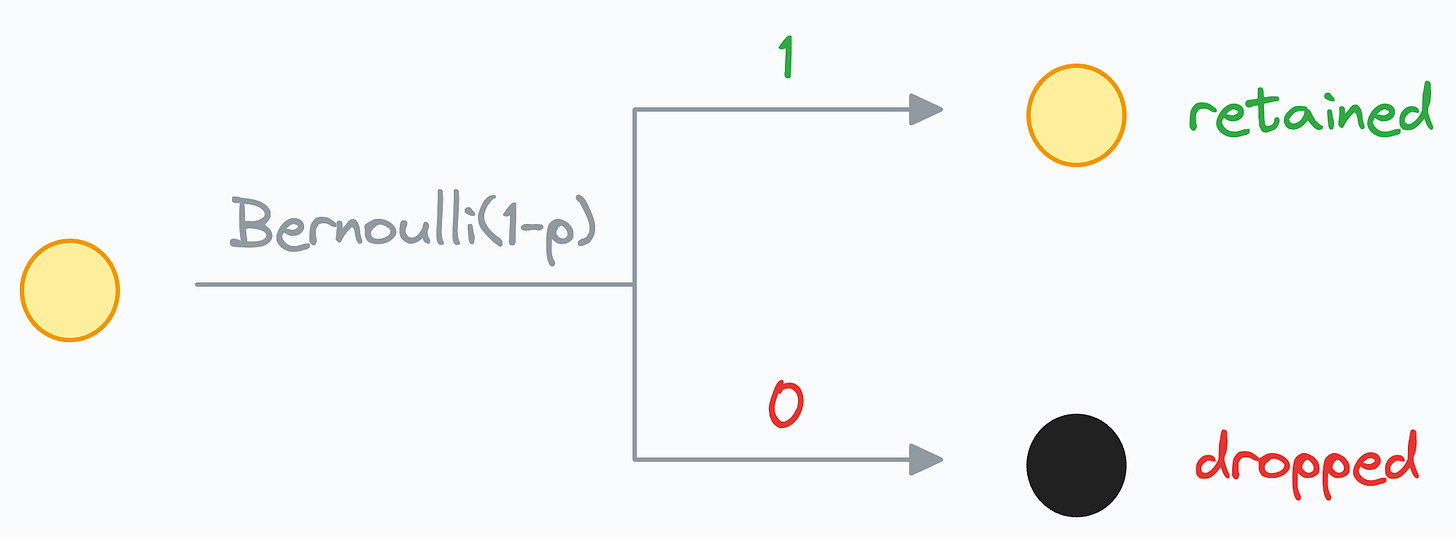 “
“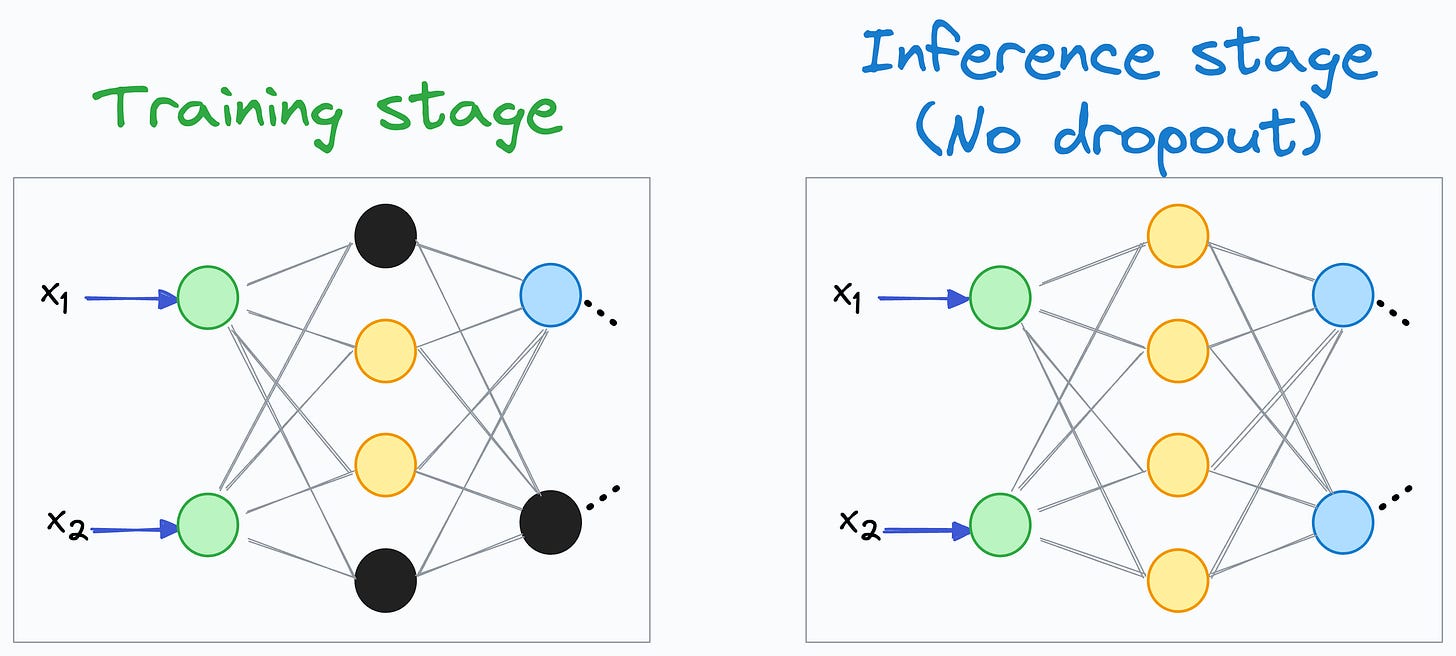 Now, consider that a neuron’s input is computed using 100 neurons in the previous hidden layer:
Now, consider that a neuron’s input is computed using 100 neurons in the previous hidden layer:
 (View Highlight)
(View Highlight)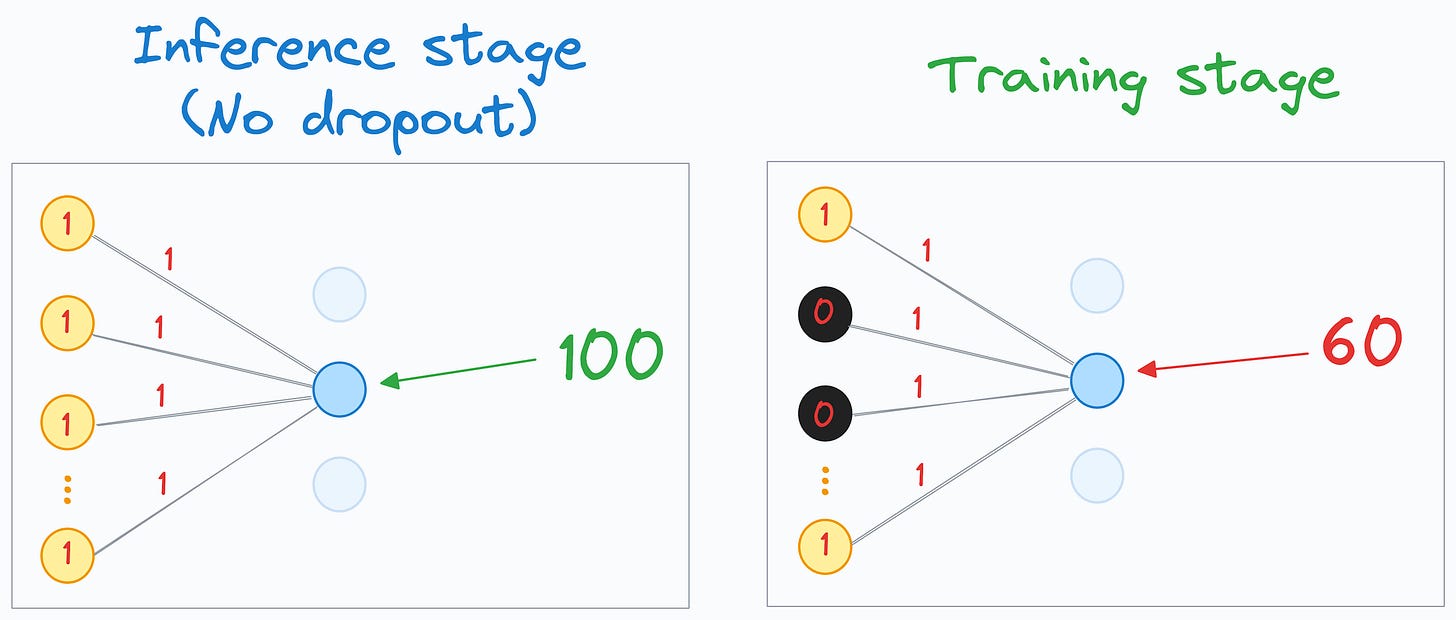 (View Highlight)
(View Highlight)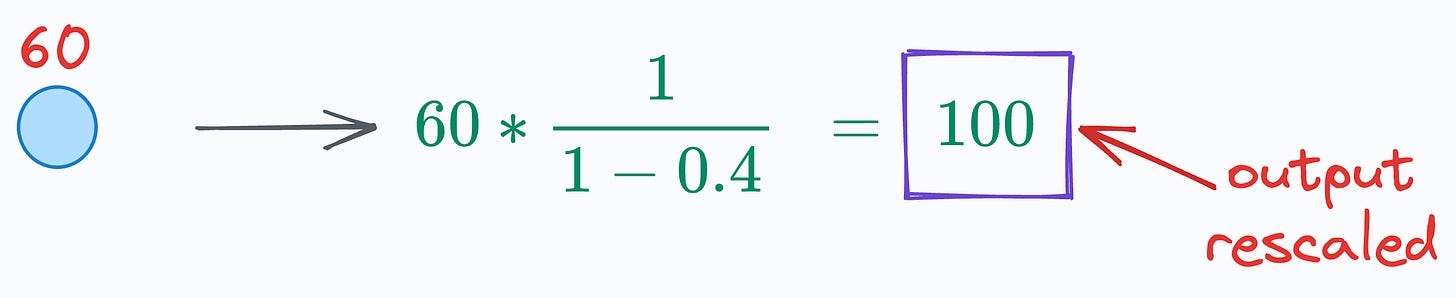 As depicted above, scaling the neuron input brings it to the desired range, which makes training and inference stages coherent for the network. (View Highlight)
As depicted above, scaling the neuron input brings it to the desired range, which makes training and inference stages coherent for the network. (View Highlight)