We introduce AI co-scientist, a multi-agent AI system built with Gemini 2.0 as a virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries. (View Highlight)
In the pursuit of scientific advances, researchers combine ingenuity and creativity with insight and expertise grounded in literature to generate novel and viable research directions and to guide the exploration that follows. In many fields, this presents a breadth and depth conundrum, since it is challenging to navigate the rapid growth in the rate of scientific publications while integrating insights from unfamiliar domains. Yet overcoming such challenges is critical, as evidenced by the many modern breakthroughs that have emerged from transdisciplinary endeavors. (View Highlight)
Motivated by unmet needs in the modern scientific discovery process and building on recent AI advances, including the ability to synthesize across complex subjects and to perform long-term planning and reasoning, we developed an AI co-scientist system. The AI co-scientist is a multi-agent AI system that is intended to function as a collaborative tool for scientists. Built on Gemini 2.0, AI co-scientist is designed to mirror the reasoning process underpinning the scientific method. Beyond standard literature review, summarization and “deep research” tools, the AI co-scientist system is intended to uncover new, original knowledge and to formulate demonstrably novel research hypotheses and proposals, building upon prior evidence and tailored to specific research objectives. (View Highlight)
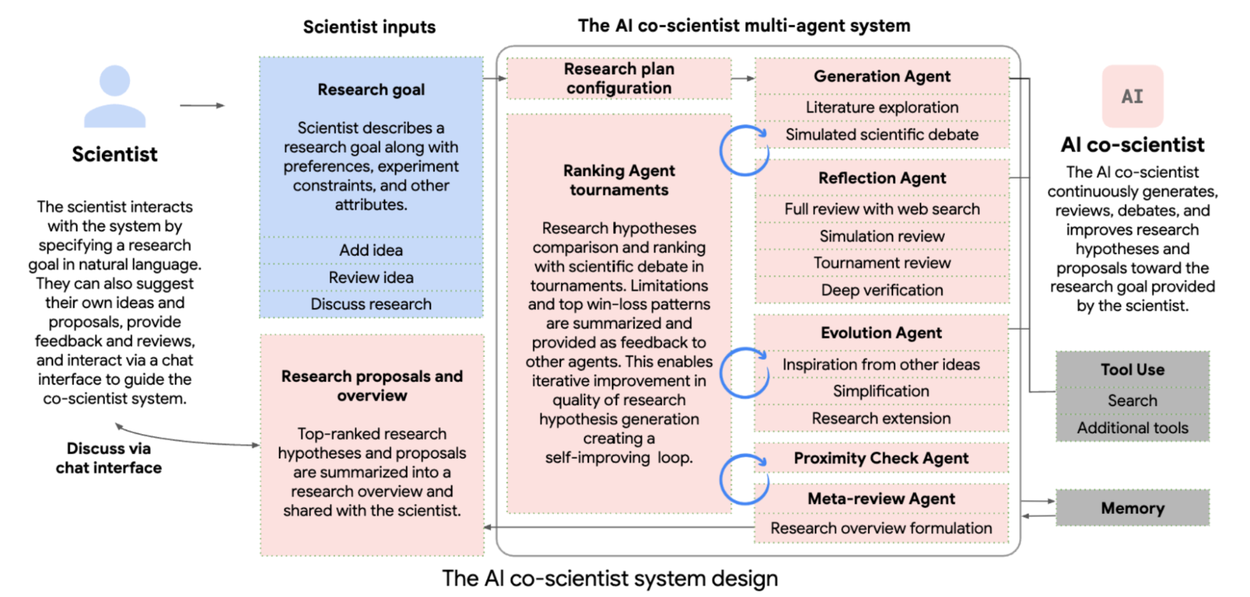
Given a scientist’s research goal that has been specified in natural language, the AI co-scientist is designed to generate novel research hypotheses, a detailed research overview, and experimental protocols. To do so, it uses a coalition of specialized agents — Generation, Reflection, Ranking, Evolution, Proximity and Meta-review — that are inspired by the scientific method itself. These agents use automated feedback to iteratively generate, evaluate, and refine hypotheses, resulting in a self-improving cycle of increasingly high-quality and novel outputs. (View Highlight)
Purpose-built for collaboration, scientists can interact with the system in many ways, including by directly providing their own seed ideas for exploration or by providing feedback on generated outputs in natural language. The AI co-scientist also uses tools, like web-search and specialized AI models, to enhance the grounding and quality of generated hypotheses.
(View Highlight)
The AI co-scientist parses the assigned goal into a research plan configuration, managed by a Supervisor agent. The Supervisor agent assigns the specialized agents to the worker queue and allocates resources. This design enables the system to flexibly scale compute and to iteratively improve its scientific reasoning towards the specified research goal.
(View Highlight)
The AI co-scientist leverages test-time compute scaling to iteratively reason, evolve, and improve outputs. Key reasoning steps include self-play–based scientific debate for novel hypothesis generation, ranking tournaments for hypothesis comparison, and an “evolution” process for quality improvement. The system’s agentic nature facilitates recursive self-critique, including tool use for feedback to refine hypotheses and proposals. (View Highlight)
The system’s self-improvement relies on the Elo auto-evaluation metric derived from its tournaments. Due to their core role, we assessed whether higher Elo ratings correlate with higher output quality. We analyzed the concordance between Elo auto-ratings and GPQA benchmark accuracy on its diamond set of challenging questions, and we found that higher Elo ratings positively correlate with a higher probability of correct answers.
(View Highlight)
Seven domain experts curated 15 open research goals and best guess solutions in their field of expertise. Using the automated Elo metric we observed that the AI co-scientist outperformed other state-of-the-art agentic and reasoning models for these complex problems. The analysis reproduced the benefits of scaling test-time compute using inductive biases derived from the scientific method. As the system spends more time reasoning and improving, the self-rated quality of results improve and surpass models and unassisted human experts.
(View Highlight)
On a smaller subset of 11 research goals, experts assessed the novelty and impact of the AI co-scientist–generated results compared to other relevant baselines; they also provided overall preference. While the sample size was small, experts assessed the AI co-scientist to have higher potential for novelty and impact, and preferred its outputs compared to other models. Further, these human expert preferences also appeared to be concordant with the previously introduced Elo auto-evaluation metric. (View Highlight)
n our report we address several limitations of the system and opportunities for improvement, including enhanced literature reviews, factuality checking, cross-checks with external tools, auto-evaluation techniques, and larger-scale evaluation involving more subject matter experts with varied research goals. The AI co-scientist represents a promising advance toward AI-assisted technologies for scientists to help accelerate discovery. (View Highlight)
Its ability to generate novel, testable hypotheses across diverse scientific and biomedical domains — some already validated experimentally — and its capacity for recursive self-improvement with increased compute, demonstrate its potential to accelerate scientists’ efforts to address grand challenges in science and medicine. (View Highlight)

 (View Highlight)
(View Highlight)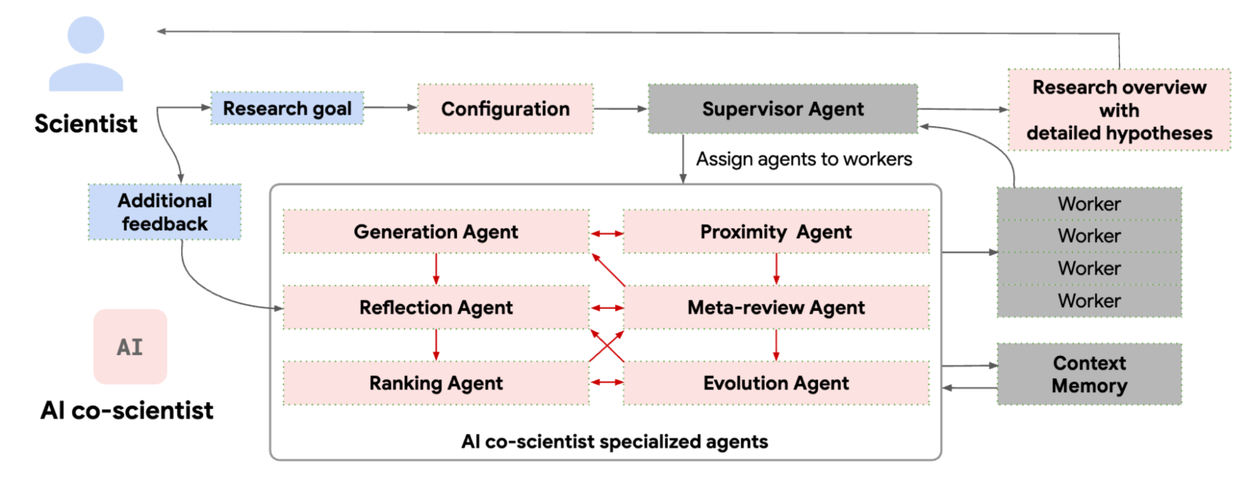 (View Highlight)
(View Highlight)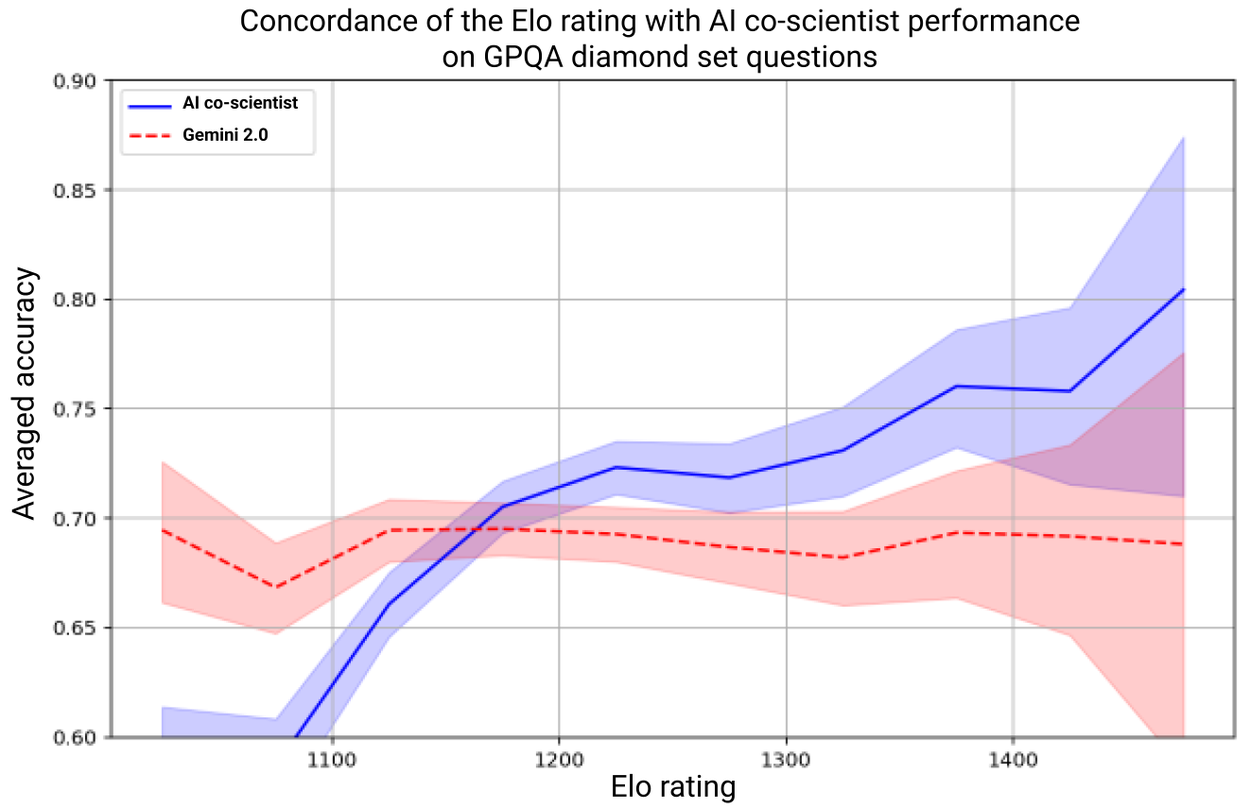 (View Highlight)
(View Highlight)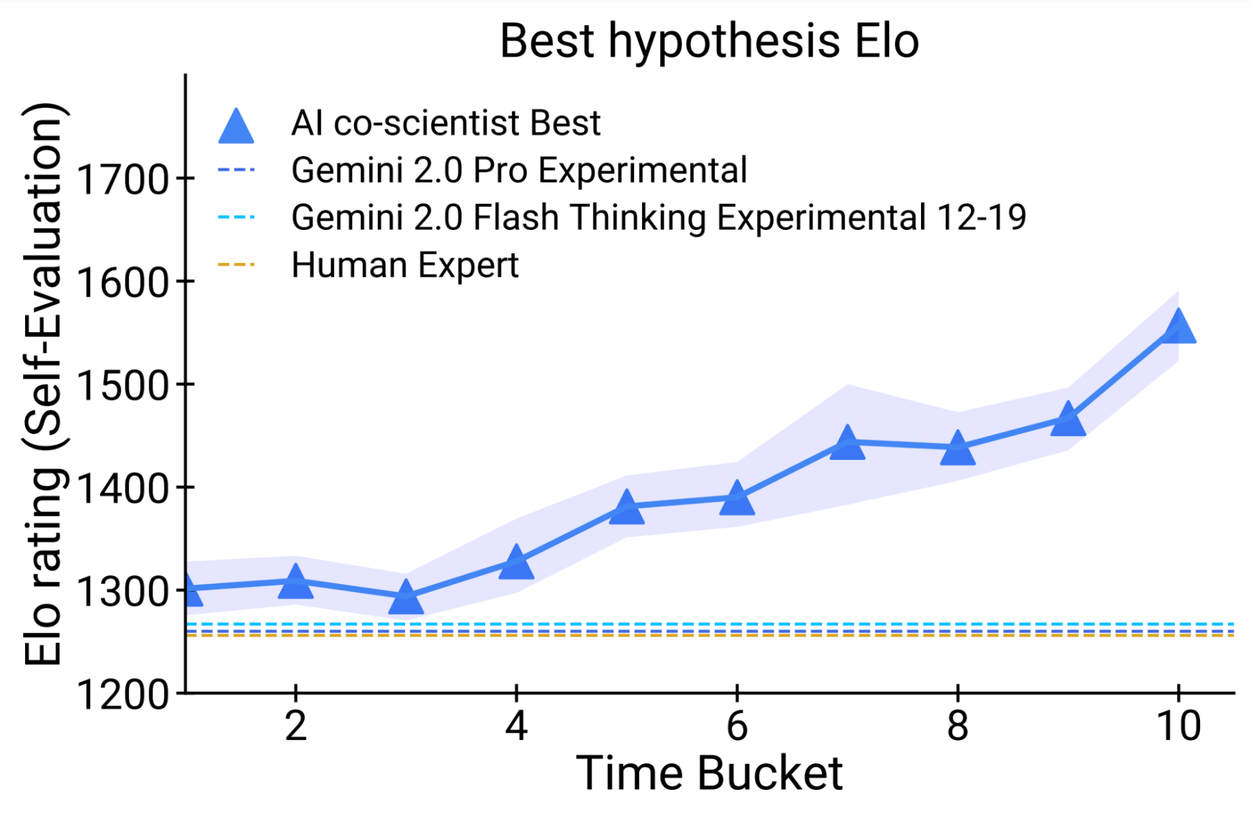 (View Highlight)
(View Highlight)