• Multimodal native understanding:
• State-of-the-art performance on a wide range of multimodal and language tasks
• Pre-trained from scratch on a mixture of multimodal and language data
• Lightweight and fast:
• Fine-grained mixture-of-expert model with 3.9B activated parameters per token
• Efficient and informative visual encoding of variable image sizes and aspect ratios
• Long context window:
• Long multimodal context window of 64K tokens, captioning a 256-frame video in 10 seconds
• Open:
• Open model weights 🤗, code repository 💻, technical report 📝 for collaborative development.
• License: Apache 2.0 (View Highlight)
Aria processes text, images, video, and code all at once, without needing separate setups for each type, demonstrating the advantages of a multimodal native model.
We provide a quantifiable definition for the term multimodal native:
A multimodal native model refers to a single model with strong understanding capabilities across multiple input modalities (e.g., text, code, image, video) that matches or exceeds the modality-specialized models of similar capacities. (View Highlight)
We compared Aria against the best open and closed multimodal native models across established benchmarks, highlighting the following key observations:
• Best-in-Class Performance: Aria is the leading multimodal native model, demonstrating clear advantages over Pixtral-12B and Llama3.2-11B across a range of multimodal, language, and coding tasks.
• Competitive Against Proprietary Models: Aria performs competitively against proprietary models like GPT-4o and Gemini-1.5 on multimodal tasks, including document understanding, chart reading, scene text recognition, and video understanding.
• Parameter Efficiency: Aria is the most parameter-efficient open model. Thanks to the MoE framework, Aria activates only 3.9 billion parameters, compared to the full activation in models like Pixtral-12B and Llama3.2-11B. (View Highlight)
Multimodal data is often complex, involving long sequences that combine visuals and text, like videos with subtitles or long documents. For a model to be effective in real-world applications, it must be capable of understanding and processing such data efficiently.
Aria excels in this area, demonstrating superior long multimodal input understanding. It outperforms larger open models, proving its efficiency and effectiveness despite its size. When compared to proprietary models, Aria surpasses GPT-4o mini in long video understanding and outperforms Gemini-1.5-Flash in long document understanding. This makes Aria a preferred choice for processing extensive multimodal data in a compute-and-time-efficient manner, delivering faster and more accurate results in real-world scenarios. (View Highlight)
Aria is highly effective at understanding and following instructions on both multimodal and language inputs, performing better than top open-source models on both MIA-Bench and MT-Bench.
(View Highlight)
Aria is pre-trained from scratch using a 4-stage training pipeline, ensuring that the model progressively learns new capabilities while retaining previously acquired knowledge. (View Highlight)
Multimodal Native Reasoning with Vision, Language, Coding Capabilities (View Highlight)
How does the company’s profit margin change from year 2020 to 2021? What factors cause such changes? Answer step by step.
(View Highlight)
Aria is designed to be developer-friendly, offering extensive support and flexibility. To facilitate development and collaboration, Rhymes AI provides a codebase that facilitates adoptions of Aria in downstream applications.
The codebase features: (View Highlight)

 (View Highlight)
(View Highlight)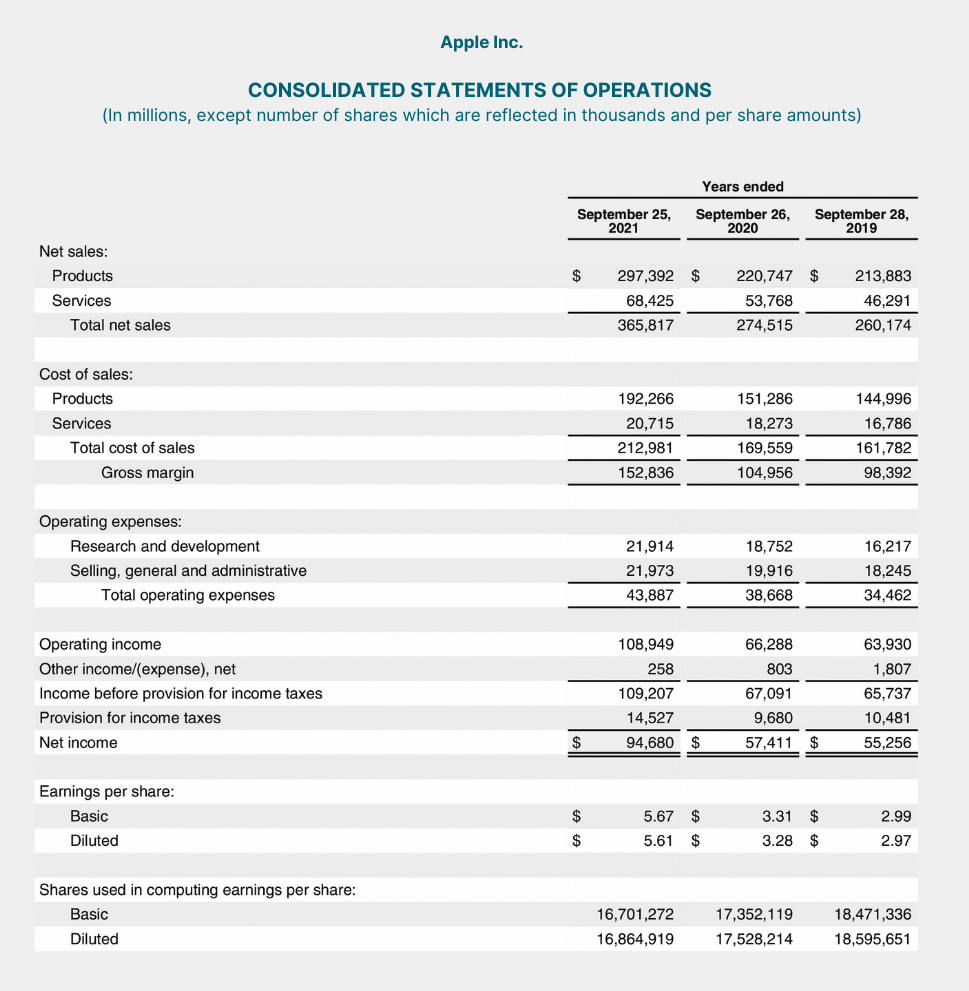 (View Highlight)
(View Highlight)