• It’s easy to make something cool with LLMs, but very hard to make something production-ready with them.
• LLM limitations are exacerbated by a lack of engineering rigor in prompt engineering, partially due to the ambiguous nature of natural languages, and partially due to the nascent nature of the field. (View Highlight)
• It’s easy to make something cool with LLMs, but very hard to make something production-ready with them.
• LLM limitations are exacerbated by a lack of engineering rigor in prompt engineering, partially due to the ambiguous nature of natural languages, and partially due to the nascent nature of the field. (View Highlight)
Challenges of productionizing prompt engineering (View Highlight)
In prompt engineering, instructions are written in natural languages, which are a lot more flexible than programming languages. This can make for a great user experience, but can lead to a pretty bad developer experience. (View Highlight)
if someone accidentally changes a prompt, it will still run but give very different outputs. (View Highlight)
We can craft our prompts to be explicit about the output format, but there’s no guarantee that the outputs will always follow this format. (View Highlight)
Inconsistency in user experience: when using an application, users expect certain consistency (View Highlight)
This seems to be a problem that OpenAI is actively trying to mitigate. They have a notebook with tips on how to increase their models’ reliability. (View Highlight)
A couple of people who’ve worked with LLMs for years told me that they just accepted this ambiguity and built their workflows around that. It’s a different mindset compared to developing deterministic programs, but not something impossible to get used to. (View Highlight)
A common technique for prompt engineering is to provide in the prompt a few examples and hope that the LLM will generalize from these examples (fewshot learners). (View Highlight)
Whether the LLM understands the examples given in the prompt. One way to evaluate this is to input the same examples and see if the model outputs the expected scores. If the model doesn’t perform well on the same examples given in the prompt, it is likely because the prompt isn’t clear (View Highlight)
Whether the LLM overfits to these fewshot examples. You can evaluate your model on separate examples. (View Highlight)
Small changes to a prompt can lead to very different results. It’s essential to version and track the performance of each prompt. You can use git to version each prompt and its performance, but I wouldn’t be surprised if there will be tools like MLflow or Weights & Biases for prompt experiments. (View Highlight)
• Prompt the model to explain or explain step-by-step how it arrives at an answer, a technique known as Chain-of-Thought or COT (Wei et al., 2022). Tradeoff: COT can increase both latency and cost due to the increased number of output tokens [see Cost and latency section]
• Generate many outputs for the same input. Pick the final output by either the majority vote (also known as self-consistency technique by Wang et al., 2023) or you can ask your LLM to pick the best one. In OpenAI API, you can generate multiple responses for the same input by passing in the argument n (not an ideal API design if you ask me).
• Break one big prompt into smaller, simpler prompts. (View Highlight)
The more explicit detail and examples you put into the prompt, the better the model performance (hopefully), and the more expensive your inference will cost. (View Highlight)
Depending on the task, a simple prompt might be anything between 300 - 1000 tokens. If you want to include more context, e.g. adding your own documents or info retrieved from the Internet to the prompt, it can easily go up to 10k tokens for the prompt alone. (View Highlight)
prompt engineering is a cheap and fast way get something up and running. For example, even if you use GPT-4 with the following setting, your experimentation cost will still be just over $300. The traditional ML cost of collecting data and training models is usually much higher and takes much longer. (View Highlight)
Input tokens can be processed in parallel, which means that input length shouldn’t affect the latency that much.
However, output length significantly affects latency, which is likely due to output tokens being generated sequentially. (View Highlight)
many teams have told me they feel like they have to redo the feasibility estimation and buy (using paid APIs) vs. build (using open source models) decision every week. (View Highlight)
There are 3 main factors when considering prompting vs. finetuning: data availability, performance, and cost. (View Highlight)
f you have only a few examples, prompting is quick and easy to get started. There’s a limit to how many examples you can include in your prompt due to the maximum input token length. (View Highlight)
. In my experience, however, you can expect a noticeable change in your model performance if you finetune on 100s examples. However, the result might not be much better than prompting. (View Highlight)
The general trend is that as you increase the number of examples, finetuning will give better model performance than prompting. (View Highlight)
• You can get better model performance: can use more examples, examples becoming part of the model’s internal knowledge.
• You can reduce the cost of prediction. The more instruction you can bake into your model, the less instruction you have to put into your prompt. (View Highlight)
tarting with a prompt, instead of changing this prompt, you programmatically change the embedding of this prompt. For prompt tuning to work, you need to be able to input prompts’ embeddings into your LLM model and generate tokens from these embeddings, which currently, can only be done with open-source LLMs and not in OpenAI API. On T5, prompt tuning appears to perform much better than prompt engineering and can catch up with model tuning (View Highlight)
finetune a smaller open-source language model (LLaMA-7B, the 7 billion parameter version of LLaMA) on examples generated by a larger language model (text-davinci-003 – 175 billion parameters). This technique of training a small model to imitate the behavior of a larger model is called distillation (View Highlight)
One direction that I find very promising is to use LLMs to generate embeddings and then build your ML applications on top of these embeddings, e.g. for search and recsys. (View Highlight)
The main cost of embedding models for real-time use cases is loading these embeddings into a vector database for low-latency retrieval. However, you’ll have this cost regardless of which embeddings you use. (View Highlight)
One observation with SituatedQA dataset for questions grounded in different dates is that despite LM (pretraining cutoff is year 2020) has access to latest information via Google Search, its performance on post-2020 questions are still a lot worse than on pre-2020 questions. This suggests the existence of some discrepencies or conflicting parametric between contextual information and model internal knowledge. (View Highlight)
, with prompt engineering, if you want to use a newer model, there’s no way to guarantee that all your prompts will still work as intended with the newer model, so you’ll likely have to rewrite your prompts again. If you expect the models you use to change at all, it’s important to unit-test all your prompts using evaluation examples. (View Highlight)
Newer models might, overall, be better, but there will be use cases for which newer models are worse. (View Highlight)
Experiments with prompts are fast and cheap, as we discussed in the section Cost. While I agree with this argument, a big challenge I see in MLOps today is that there’s a lack of centralized knowledge for model logic, feature logic, prompts, etc. (View Highlight)
The word agent is being thrown around a lot to refer to an application that can execute multiple tasks according to a given control flow (see Control flows section). A task can leverage one or more tools. (View Highlight)
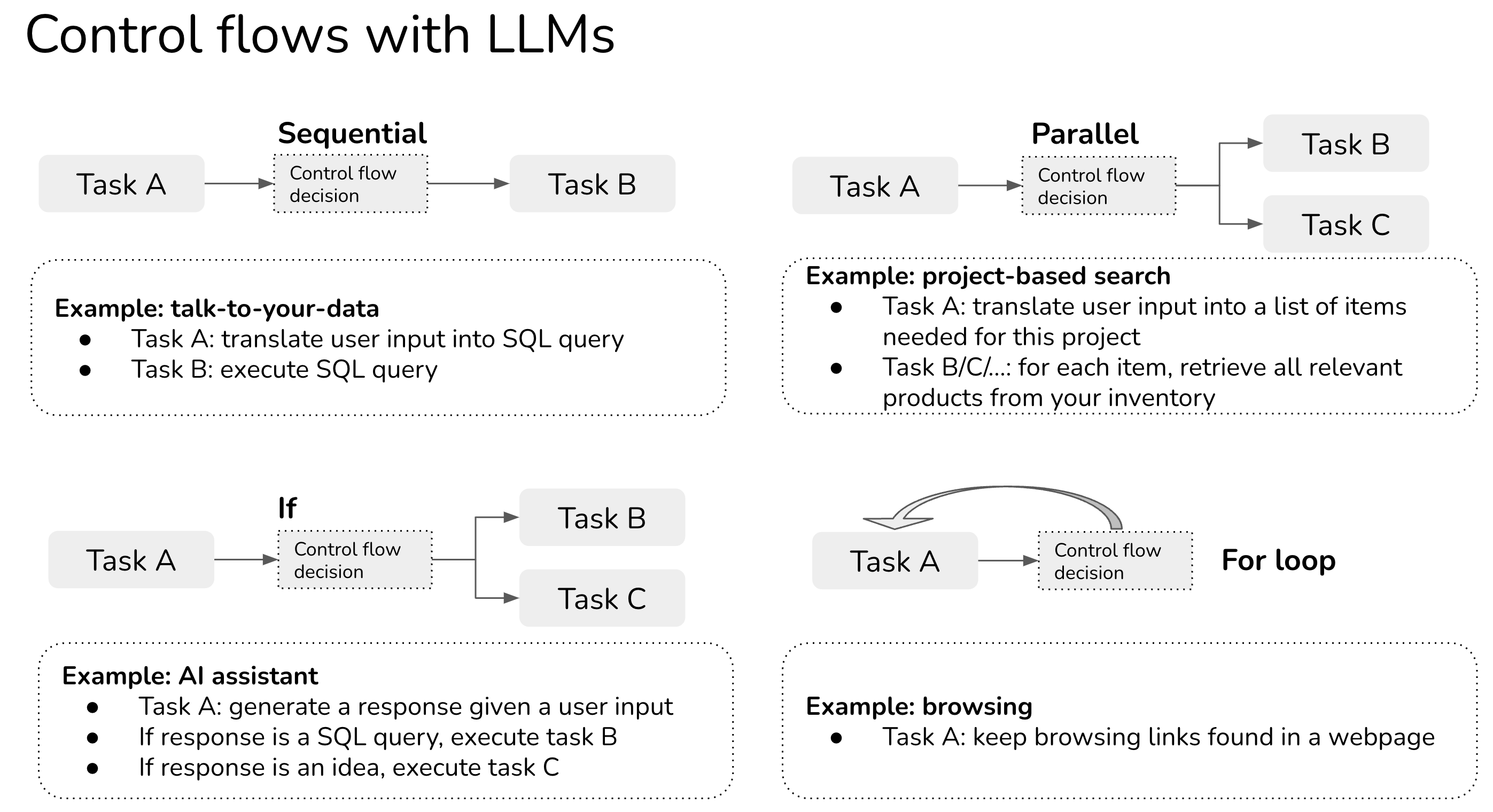
In the example above, sequential is an example of a control flow in which one task is executed after another. (View Highlight)
In traditional software engineering, conditions for control flows are exact. With LLM applications (also known as agents), conditions might also be determined by prompting. (View Highlight)
For agents to be reliable, we’d need to be able to build and test each task separately before combining them. There are two major types of failure modes:
One or more tasks fail. Potential causes:
Control flow is wrong: a non-optional action is chosen
One or more tasks produce incorrect results
All tasks produce correct results but the overall solution is incorrect. Press et al. (2022) call this “composability gap”: the fraction of compositional questions that the model answers incorrectly out of all the compositional questions for which the model answers the sub-questions correctly. (View Highlight)
This is hands down the most popular consumer use case. There are AI assistants built for different tasks for different groups of users (View Highlight)
Chatbots are similar to AI assistants in terms of APIs. If AI assistants’ goal is to fulfill tasks given by users, whereas chatbots’ goal is to be more of a companion (View Highlight)
The most interesting company in the consuming-chatbot space is probably Character.ai. It’s a platform for people to create and share chatbots. The most popular types of chatbots on the platform, as writing, are anime and game characters, but you can also talk to a psychologist, a pair programming partner, or a language practice partner. (View Highlight)
how to incorporate ChatGPT to help students learn even faster. All EdTech companies I know are going full-speed on ChatGPT exploration. (View Highlight)
Many, many startups are building tools to let enterprise users query their internal data and policies in natural languages or in the Q&A fashion. Some focus on verticals such as legal contracts, resumes, financial data, or customer support. Given a company’s all documentations, policies, and FAQs, you can build a chatbot that can respond your customer support requests. (View Highlight)
• Organize your internal data into a database (SQL database, graph database, embedding/vector database, or just text database)
• Given an input in natural language, convert it into the query language of the internal database. For example, if it’s a SQL or graph database, this process can return a SQL query. If it’s embedding database, it’s might be an ANN (approximate nearest neighbor) retrieval query. If it’s just purely text, this process can extract a search query.
• Execute the query in the database to obtain the query result.
• Translate this query result into natural language. (View Highlight)
But what if searching for “things you need for camping in oregon in november” on Amazon actually returns you a list of things you need for your camping trip?
It’s possible today with LLMs. For example, the application can be broken into the following steps:
Task 1: convert the user query into a list of product names [LLM]
Task 2: for each product name in the list, retrieve relevant products from your product catalog. (View Highlight)
If this works, I wonder if we’ll have LLM SEO: techniques to get your products recommended by LLMs. (View Highlight)
many prompt engineering papers remind me of the early days of deep learning when there were thousands of papers describing different ways to initialize weights (View Highlight)

 (View Highlight)
(View Highlight)