was found that ImageNet had over 100k mislabeled images.
Real-world datasets are messy.
They often come with noisy labels, missing values, and outliers that can severely degrade your model’s performance.
No sophisticated ML algorithms can compensate for poor-quality or mislabeled data. (View Highlight)
Researchers from MIT developed Cleanlab, which is an open-source library that cleans your data in just a few lines of code. (View Highlight)
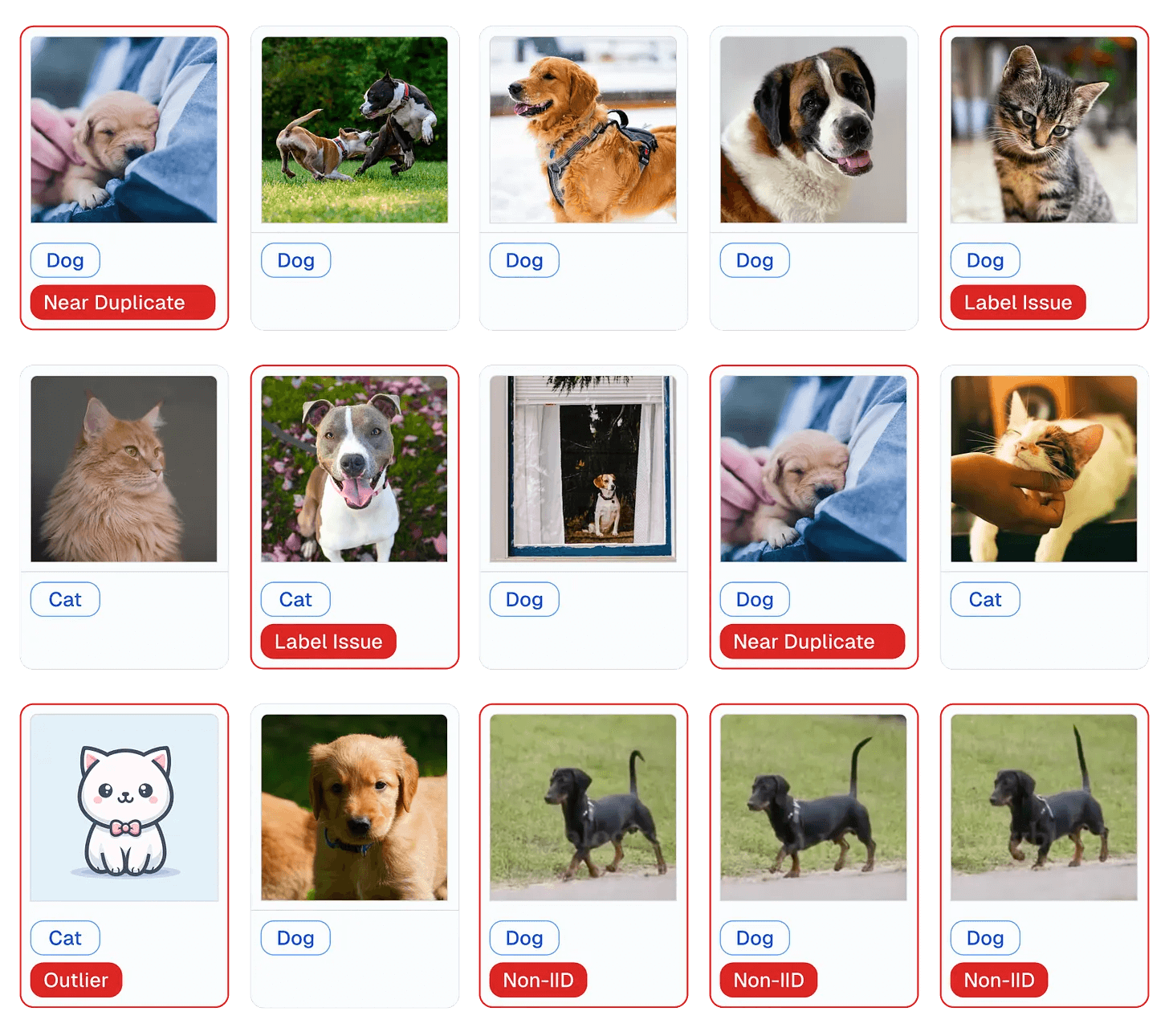
As shown in the image above, Cleanlab can flag errors in any type of data (text, image, tabular, audio), like:
• out-of-distribution samples
• outliers
• label issues
• duplicates, etc.
All it takes is just four lines of code:
• Import the package.
• Pass the dataset and specify the label column.
• Find issues by passing the embedding matrix and the probabilities predicted by the model.
• Finally, generate the report!
Done!
It will generate a report like the one shown above.
This way, you can easily clean your datasets for training accurate ML models. (View Highlight)
 (View Highlight)
(View Highlight) • Import the package.
• Pass the dataset and specify the label column.
• Find issues by passing the embedding matrix and the probabilities predicted by the model.
• Finally, generate the report!
Done!
It will generate a report like the one shown above.
This way, you can easily clean your datasets for training accurate ML models. (View Highlight)
• Import the package.
• Pass the dataset and specify the label column.
• Find issues by passing the embedding matrix and the probabilities predicted by the model.
• Finally, generate the report!
Done!
It will generate a report like the one shown above.
This way, you can easily clean your datasets for training accurate ML models. (View Highlight)