When it comes to scalability, Spotify’s Data Collection platform collects more than 1 trillion events per day. Its event delivery architecture is constantly evolving through numerous iterations. To learn more about the event delivery evolution, its inception, and subsequent improvements, check out this blog post. (View Highlight)
Data Collection is needed, so we can:
• Understand what content is relevant to Spotify users
• Directly respond to user feedback
• Have a deeper understanding of user interactions to enhance their experience
(View Highlight)
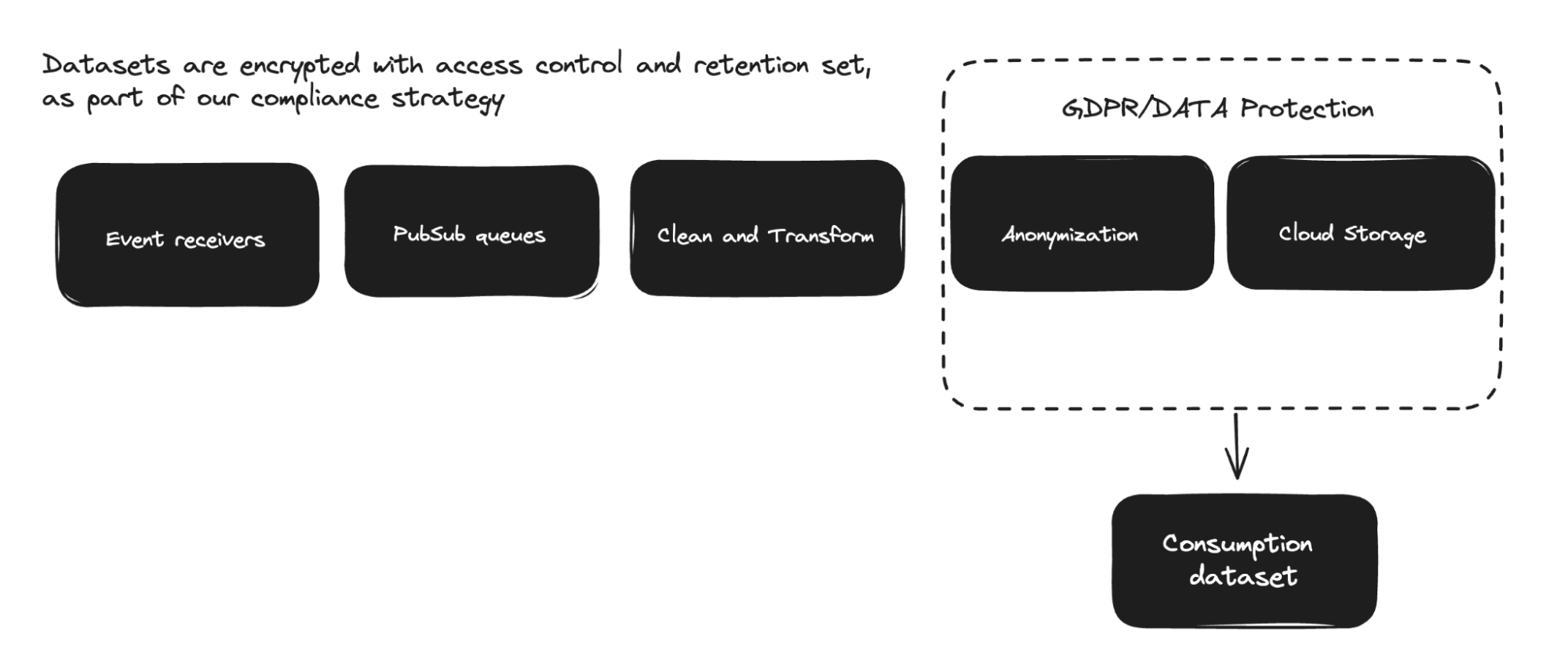
When a team at Spotify decides to instrument their functionality with event delivery, aside from writing code using our SDs, they only need to define the event schemas. The infrastructure then automatically deploys a new set of event-specific components (such as PubSub queues, anonymization pipelines, and streaming jobs) using K8 operators. Any changes to the event schema triggers the deployment of corresponding resources. Anonymization solutions, including internal key-handling systems, are covered in detail in this article. (View Highlight)
The balance between centralized and distributed ownership allows most updates to be managed by consumers of the consumption dataset, without requiring intervention from the infrastructure team. (View Highlight)
Today, over 1800 different event types — or signals representing interactions from Spotify users — are being published. In terms of team structure, the data collection area is organized to focus on the event delivery infrastructure, supporting and enhancing client SDKs for event transmission, and building the high quality datasets that represent the user journey experience, as well as the infrastructure needed behind it. (View Highlight)
Our Data Processing efforts focus on empowering Spotify to utilize data effectively, while Data Management is dedicated to ensuring data integrity through tool creation and collaborative efforts. With more than 38,000 actively scheduled pipelines handling both hourly and daily tasks, scalability is a key consideration. (View Highlight)
Data Management and Data Processing are essential for Spotify to effectively manage its extensive data and pipelines. It’s crucial to maintain data traceability (lineage), searchability (metadata), and accessibility, while implementing access controls and retention policies to manage storage costs and comply with regulations. These functions enable Spotify to extract maximum value from its data assets while upholding operational efficiency and regulatory standards. (View Highlight)
The scheduling and orchestration of workflows are essential components of Data Processing. Once a workflow is picked up by the scheduler, it’s executed on BigQuery, or either Flink or Dataflow clusters. Most pipelines utilize Scio, a Scala API for Beam. (View Highlight)
Data pipelines generate data endpoints, each adhering to a specific schema and possibly containing multiple partitions. These endpoints are equipped with retention policies, access controls, lineage tracking, and quality checks.
Defining a workflow or endpoint involves custom K8 operators, which help us to easily deploy and maintain complex structures. In that manner, the resource definition lives in the same repo as the pipeline code and gets deployed and maintained by the codeowners. (View Highlight)
Monitoring options include alerts for data lateness, long-running or failing workflows, and endpoints. Backstage integration facilitates easy resource management, monitoring, cost analysis, and quality assurance. (View Highlight)
Building a data platform is non-trivial — it needs to be flexible enough to satisfy a variety of different use cases, aligning with cost effectiveness and return on investment goals, and at the same time keeping the developer experience lean. The data platform needs to be easy to onboard to and have seamless upgrade paths (nobody likes to be disrupted by platform upgrades and breaking changes). And the platform needs to be reliable — if teams have the expectation to build business critical logic on top of your platform, we treat the platform as a critical use case as well. (View Highlight)
There are multiple ways to elevate engagement with your product:
• Documentation(which is easy to find). We all have been in situations where, “I remember reading about it, but I don’t remember where.” It should be easier to find documentation than to ask a question (considering the waiting time).
• Onboard teams. There is no better way to learn about your product than to start using it yourself. Go to users and embed there. Learn about different use cases, make sure that your product is easy to use in all possible environments, and bring the learnings back to the platform.
• Fleetshiftthe changes. People love evolving and making changes to their infrastructure and having the code being highlighted as deprecated, right? Not really. That is why we should automate all possible toils and migrations. Plan to deal with risks. Make time to support your customers.
• Build a community where people are free to ask questions and where there are dedicated goalies to answer these questions. Answering community questions should not be left to free will, but should instead be encouraged and taken seriously. At Spotify we have a slack channel data-support, where all data questions are addressed. (View Highlight)

 (View Highlight)
(View Highlight)