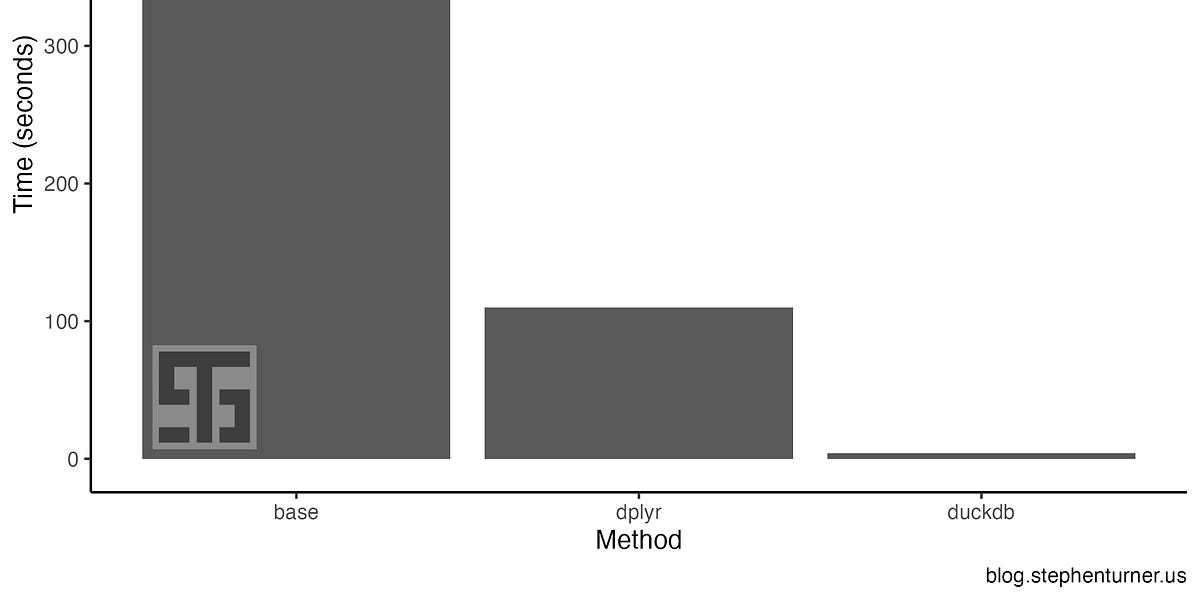
I wanted to see for myself what the fuss was about with DuckDB. DuckDB is an open-source, high-performance, in-process SQL query engine designed specifically for analytical tasks. Often referred to as the “sqlite for analytics” DuckDB is optimized for OLAP (Online Analytical Processing) workloads — data is organized by columns meaning that the database is optimized for fast reading and large, complex queries that involve filtering, aggregations, and joins. It’s “embedded” in the same sense that sqlite is — it has no external dependencies, no DBMS server to install, setup, and maintain. It doesn’t as a separate process — it runs embedded within a host process, conferring the advantage of high-speed data transfer to and from the database, or in some cases direct querying of the data without actually importing or copying any data at all. Read more at duckdb.org/why_duckdb. (View Highlight)
DuckDB has an R API available (see docs). You can install the duckdb package from CRAN or GitHub. Why might you want to use DuckDB in R?
Large Datasets: When you have data too large for memory, DuckDB can efficiently query data from disk without needing the entire dataset in memory.
SQL-Like Queries: If you’re more comfortable with SQL, DuckDB allows you to run SQL queries directly on your R data frames. You can perform complex operations such as grouping, filtering, joining, and aggregating, using familiar SQL syntax. Again, without ever reading data into memory in R.
Efficient Analytical Queries: For workloads involving large aggregations or queries on millions of rows DuckDB can handle large analytical queries while minimizing memory overhead and keeping performance high.
Stay in R! Using DuckDB in R lets you use DuckDB for the heavy lifting analytical queries, giving you results back in a table that you can take forward for visualization or further analysis. (View Highlight)
Data wrangling is the thorny hedge that higher powers have placed in front of the enjoyable task of actually analyzing or visualizing data. Common struggles come from importing data from ill-mannered CSV files, the tedious task of orchestrating efficient data transformation, or the inevitable management of changes to tables. Data wrangling is rife with questionable ad-hoc solutions, which can sometimes even make things worse. The design rationale of DuckDB is to support the task of data wrangling by bringing the best of decades of data management research and best practices to the world of interactive data analysis in R or Python. (View Highlight)