In many use cases, like understanding spending behavior based on transaction history, such continuous variables are better understood when they are discretized into meaningful groups → youngsters, adults, and seniors. (View Highlight)
This would result in some coefficients for each feature, which would tell us the influence of each feature on the final prediction. (View Highlight)
But if you think again, in our goal of understanding spending behavior, are we really interested in learning the correlation between exact age and spending behavior? (View Highlight)
Instead, it makes more sense to learn the correlation between different age groups and spending behavior. (View Highlight)
Now that we understand the rationale, there are 2 techniques that are widely preferred. (View Highlight)
One way of discretizing features involves decomposing a feature into equally sized bins. (View Highlight)
Another technique involves decomposing a feature into equal frequency bins: (View Highlight)
After that, the discrete values are one-hot encoded. (View Highlight)
One advantage of feature discretization is that it enables non-linear behavior even though the model is linear. (View Highlight)
This can potentially lead to better accuracy, which is also evident from the image below: (View Highlight)
A linear model with feature discretization results in a:
• non-linear decision boundary.
• better test accuracy.
So, in a way, we get to use a simple linear model but still get to learn non-linear patterns. (View Highlight)
Simply put, “signal” refers to the meaningful or valuable information in the data. (View Highlight)
Binnng a feature helps us mitigate the influence of minor fluctuations, which are often mere noise. (View Highlight)
Before I conclude, do remember that feature discretization with one-hot encoding increases the number of features → thereby increasing the data dimensionality. (View Highlight)
And typically, as we progress towards higher dimensions, data become more easily linearly separable. Thus, feature discretization can lead to overfitting. (View Highlight)
To avoid this, don’t overly discretize all features. (View Highlight)
Instead, use it when it makes intuitive sense, as we saw earlier. (View Highlight)
Of course, its utility can vastly vary from one application to another, but at times, I have found that:
• Discretizing geospatial data like latitude and longitude can be useful.
• Discretizing age/weight-related data can be useful.
• Features that are typically constrained between a range makes sense, like savings/income (practically speaking), etc. (View Highlight)

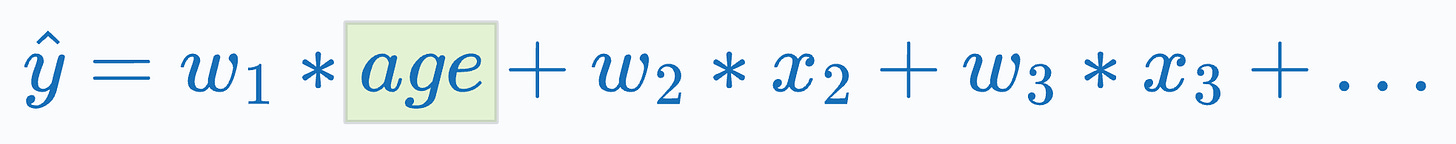 (View Highlight)
(View Highlight)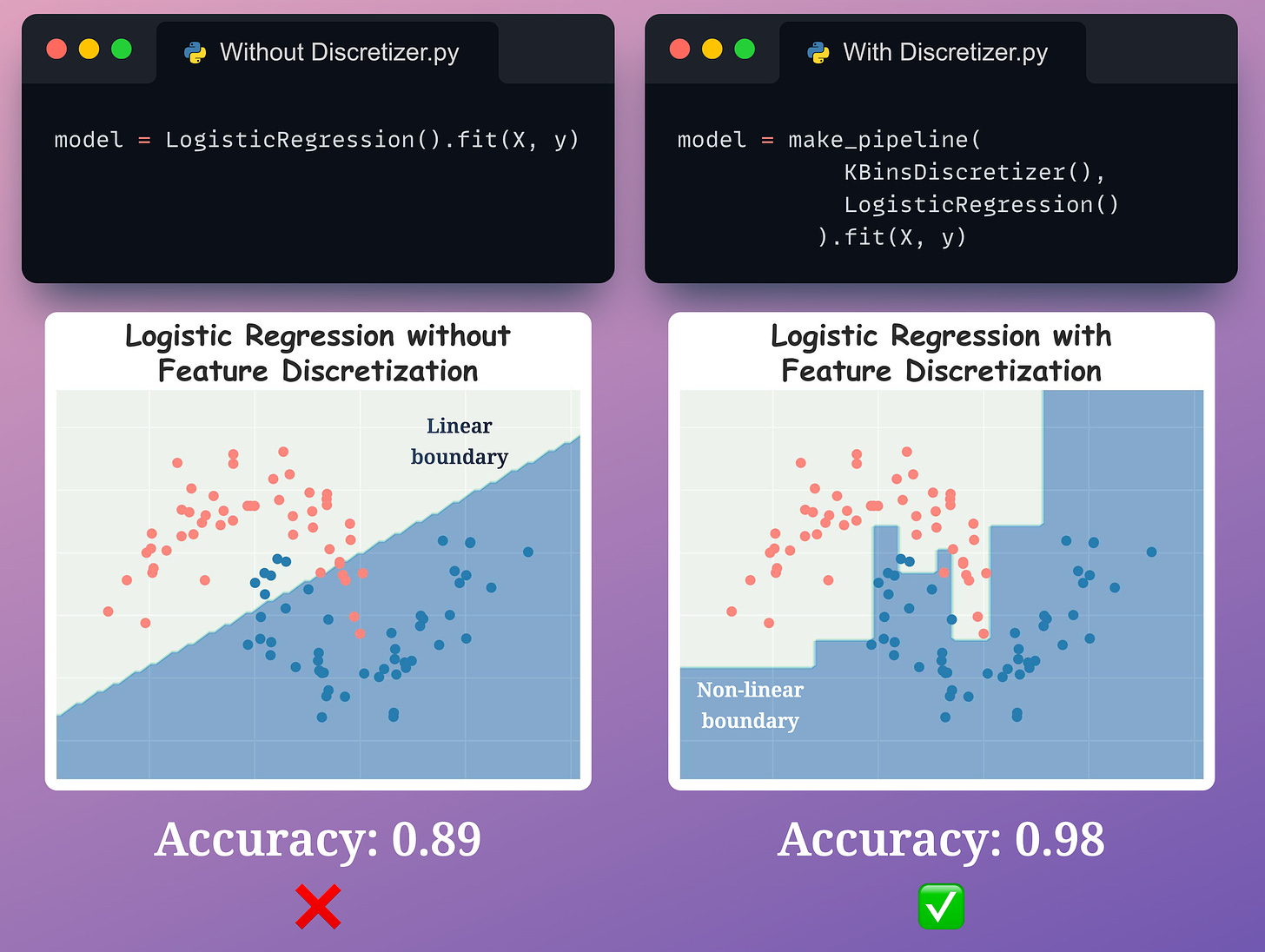 (View Highlight)
(View Highlight)