Graphs have emerged as a fundamental tool for understanding complex systems across various domains. By representing entities as nodes and relationships as edges, graphs offer a versatile framework for characterizing, analyzing, and visualizing interactions between objects of interest. This approach facilitates the identification of patterns, trends, and anomalies within intricate datasets. (View Highlight)
The adoption of graph-based analysis has been increasingly prominent at BBVA. This article introduces BBVA’s open-source implementation for automatically generating graph-based features to enhance model performance. (View Highlight)
To make the methodologies discussed in this article more accessible and practical, we have made our code publicly available on mercury-graph. This resource enables readers to run their own experiments and apply these concepts to their specific case studies, thereby promoting a deeper understanding and ensuring the reproducibility of our findings. (View Highlight)
Machine learning models’ effectiveness depends on relevant patterns within the underlying data. Certain patterns, however, particularly those derived from relationships within a network, can be challenging for models to learn without explicitly modeling the data as a graph. Incorporating graph-based variables into the feature set enables models to uncover complex patterns that might otherwise be overlooked, thereby improving their overall performance. (View Highlight)
This idea is summarized by the famous quote from linguist John R. Firth: “You shall know a word by the company it keeps”. Just like a word’s meaning can be inferred from the words around it, we can learn a lot about a person by looking at who they’re connected to. In a network, the people (or nodes) with whom someone interacts often reflect shared interests, habits, or backgrounds. That’s the intuition behind aggregating information from neighbors in a graph — it helps the model pick up on patterns that aren’t obvious from an individual’s features alone. (View Highlight)
Suppose we’re training a supervised model. Prior to the introduction of graph-based variables, our model was unable to see any further than each observation’s own attributes. In contrast, once we model the data as a graph, we enable our model to use the information surrounding each observation. (View Highlight)
In a traditional dataset, each observation has its own set of attributes (income, expenses, and so on). In order to engineer graph-based features, we must model the data as a graph, use its network structure to aggregate each node’s information and pass it on to a nearby neighbor. This way, your neighbor receives your information whilst you receive that of your neighbors. (View Highlight)
This process is formally known as message passing because we pass our neighbors’ messages (features) using the graph’s edges. Multiple frameworks can do this, with PyTorch Geometric being the most popular implementation. Unfortunately, such implementations were developed to run on a single computer, and real-world graphs are usually too large to fit in a single memory. We therefore developed our own distributed solution and published it in mercury-graph1. (View Highlight)
We start with a standard dataset where each observation has a set of attributes and a target. Our goal is to boost the model’s performance by adding features containing information about a node’s neighbors. The principle that underlies this idea is that our behavior is influenced by those around us. (View Highlight)
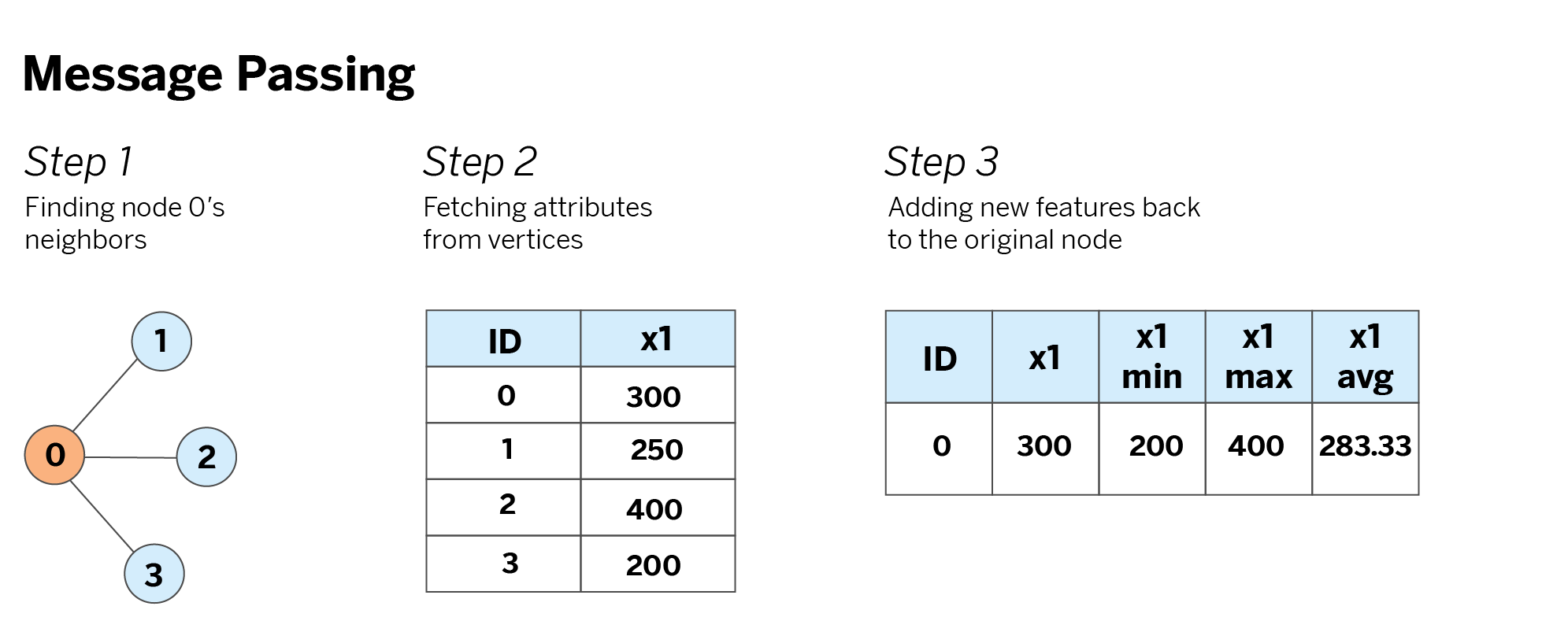
In order to add features of the people in our surroundings, we first need to determine who’s connected to whom. In graph terms, this means defining a set of edges that model pairwise relationships between nodes. We will use the edges to find everyone’s neighbors, fetch their features, apply some aggregation function (like an average), and pass this information back to the original node. (View Highlight)
In addition to the node-level attributes in the original dataset, these graph-based features provide richer context, allowing the model to uncover hidden patterns in the data and ultimately improve its predictive performance. (View Highlight)
We now have a mercury-graph object that represents the network. Our goal is to generate new features by taking the information from its vertices and passing them to other nodes through the structure defined by its edges. (View Highlight)
First, we use the graph’s edges to find the neighbors of the node of interest. For example, if we’re interested in generating new features for node 0, we use the edges to find its neighbors 1, 2, and 3. Then, we look up the neighbors in the graph’s vertices and fetch their individual attributes. (View Highlight)
Finally, we aggregate the attributes we fetched with our desired aggregation functions (minimum, maximum, and average in this example) and add this new information to the original node. (View Highlight)
As a technical note, a node does not need to be directly connected to another node in the graph for them to be considered neighbors. To see this, think of your neighbor’s neighbor; are they not your neighbors too? Two nodes connected through an intermediary are known as second-order neighbors because they are connected through a two-step path. Likewise, third-order connections represent nodes connected through three-step paths and so on. (View Highlight)
The first step is using the graph’s edges to determine the neighbor relationships – not for a single node, but for all nodes at once. In an undirected graph, we achieve this by taking the edges table and concatenating a copy of itself with the source and destination columns swapped (src becomes dst and dst becomes src). The result is what we call the first-order neighbors table, which serves a similar purpose to an adjacency matrix but is stored more efficiently because of its longitudinal form. (View Highlight)
Technically, we can do this to find all n-order connections, but this process becomes computationally expensive because it involves joining the edges table (which is presumably very large) with itself n consecutive times. Additionally, it’s hard to argue that third-degree (or greater) connections truly affect your behavior because of the distance between yourself and your neighbors’ neighbors’ neighbors. (View Highlight)
The effectiveness of machine learning models depends heavily on their ability to capture relevant patterns within the data. Incorporating graph-based variables into our feature space enables our model to leverage complex customer relationships, enhancing its predictive power. Prior to the inclusion of these graph-based variables, our models are limited to evaluating each observation in isolation. (View Highlight)

 (View Highlight)
(View Highlight)