Online job ads contain valuable information that can help companies and policy makers better understand job markets. How have salaries for different occupations changed over time? How have regional labor markets evolved? To answer these questions well, skills mentioned in unstructured text need to be extracted and mapped to complex, changing taxonomies, presenting a challenging language processing task. (View Highlight)
For instance, there are many different types of software development positions, all with different requirements, must-have experience and salary trends. We need to look at skills in much more detail to understand how job markets are changing. (View Highlight)
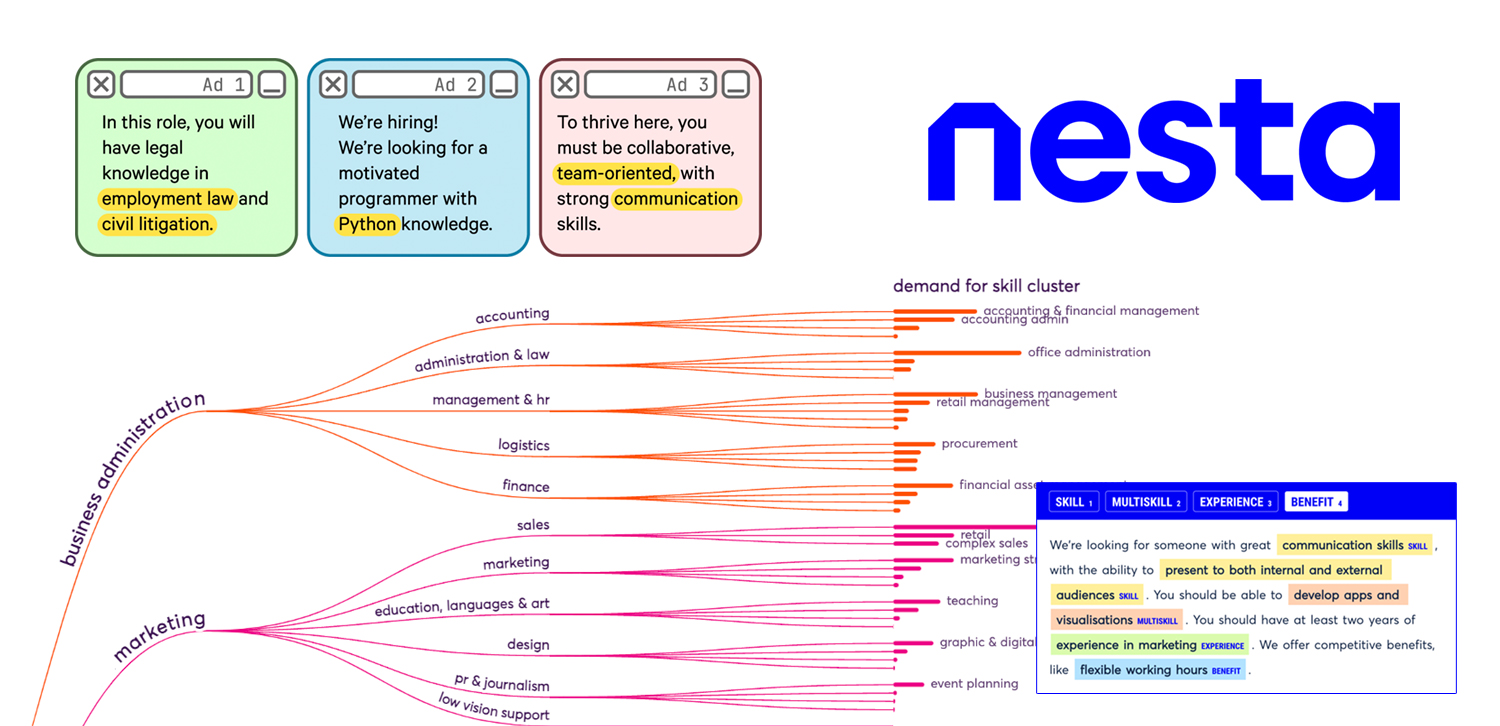
In this post, I’ll show you how our Data Science team at Nesta built an NLP pipeline using spaCy and Prodigy to extract skills from 7 million online job ads to better understand UK skill demand. Core to the pipeline is our custom mapping step, that allows users to match extracted skills to any government standard, like the European Commission’s Skills, Competences, Qualifications and Occupations (ESCO) taxonomy. (View Highlight)
Our flexible, transparent approach means that data science teams across the UK government, like the Cabinet Office, can easily use our system to understand evolving skill requirements, and discover internal mismatches. (View Highlight)
While proprietary data vendors provide metadata like skill lists and Standardized Occupation Codes (SOC), their methodology for doing so is often a black box and the data comes with restrictions on what can be shared publicly. So we decided to build the open-source alternative for insights from job advertisements to be more transparent and to have more control over what we could share. (View Highlight)
• Extract relevant information from a given job advert, like company descriptions or qualification level;
• Standardize the extracted information to official, government-released standards by developing custom mapping steps and;
• Open source our approaches (View Highlight)
Understanding what skills are required for occupations is relevant for many groups like policy makers, local authorities and career advisors. This information means that they can make informed labor market policies, address regional skill shortages or advise job seekers. To aid in this, we developed a custom NLP solution to extract skills from unstructured job ads and map them onto official skill lists. (View Highlight)
Instead, we developed a custom NLP solution to predict generic entities and added a custom mapping step to handle different, official taxonomies. Our approach used spaCy pipelines and Prodigy for efficient annotation, model training, quality control and evaluation. (View Highlight)
The end-to-end workflow we developed starts with identifying mentions of SKILL, MULTISKILL and EXPERIENCE from online job adverts. In this first step, we annotated 375 examples manually to train spaCy’s NER model. As part of our annotation process, the team labeled a handful of job adverts collectively to get a sense of the task and discuss edge cases as they came up. This approach allowed us to highlight frequent mentions of multiple skills that were not easily separable. For example, the skill “developing visualizations and apps” is in fact two skills: “developing visualizations” and “developing apps”. However, a purely out-of-the-box NER approach wouldn’t nicely separate the skill entity mentioned. (View Highlight)
Therefore, the second step aimed to separate multi-skill entities into their constituent skills. We trained a simple classifier to binarily predict if skills were multi-skill or not by using a training set of labeled skill and multi-skill entities. The features included the length of the entity, a boolean if the token "and" was in the entity and a boolean if the token "," was in the entity. If the entity was a multi-skill, we use spaCy’s dependency parsing to split them based on a series of linguistic rules such as splitting on noun phrases and the token "and". (View Highlight)
Our custom mapping step uses semantic similarity and the structure of a given taxonomy to standardize the extracted skills. This means that we can take advantage of metadata associated with skills, like skill definitions and categories. (View Highlight)
We embed extracted skills and a taxonomy to calculate the cosine similarity with every skill or skill group. If the cosine similarity is above a certain threshold, we map directly at the skill level. If it is below a certain threshold we then calculate both the max share and max cosine similarity with skills in a skill group. (View Highlight)
For example, the skill “mathematics” may be too vague to be mapped at the skill level, but it maps nicely to a number of similar skills like “philosophy of mathematics” and “using mathematical tools and equipment”, which sit under the skill group “natural sciences, mathematics and statistics”. In this instance, the share of similar-ish skills is above a certain threshold and we are able to assign “mathematics” to the appropriate skill group. We move up a given taxonomy until a broad-enough skill group can be confidently assigned to the given entity. (View Highlight)
Although the NER model’s accuracy appears not as high, partial matches are still useful for our purposes. For example, if the model predicts “Excel” as a skill, as opposed to “Microsoft Excel”, it is still usefully mapped to an appropriate standard skill. This is similarly the case for extracted skills that might be missing the appropriate verb, like “industrial trucks” as opposed to “drive industrial trucks”. (View Highlight)
We can extract skills that have not been seen before. For example, although the ESCO taxonomy does not contain the programming skill “React”, the model was able to detect “React” as a skill, and map it to “use scripting programming”. (View Highlight)
The library can be adapted to your chosen taxonomy. We have built the library in such a way that you can map skills to a custom taxonomy if desired. (View Highlight)
You can match to different levels of the taxonomy. This can be handy when a job advert mentions a broad skill group (e.g. “computer programming”) rather than a specific skill (e.g. “Python”). (View Highlight)
Metaphors: The phrase “understand the bigger picture” is matched to the ESCO skill “interpreting technical documentation and diagrams”. (View Highlight)
Multiple skills: We use basic semantic rules to split multi-skill sentences up, e.g. “developing visualizations and apps”, but the rules aren’t complete enough to split up more complex sentences. (View Highlight)