The Homepage of Pinterest is the one of most important surfaces for pinners to discover inspirational ideas and contributes to a large fraction of overall user engagement. The pins shown in the top positions on the Homefeed need to be personalized to create an engaging pinner experience. We retrieve a small fraction of the large volume of pins created on Pinterest as Homefeed candidate pins, according to user interest, followed boards, etc. To present the most relevant content to pinners, we then use a Homefeed ranking model (aka Pinnability model) to rank the retrieved candidates by accurately predicting their personalized relevance to given users. Therefore, the Homefeed ranking model plays an important role in improving pinner experience. Pinnability is a state-of-the-art neural network model that consumes pin signals, user signals, context signals, etc. and predicts user action given a pin. The high level architecture is shown in Figure 3. (View Highlight)
The Pinnability model has been using some pretrained user embedding to model user’s interest and preference. For example, we use PinnerFormer (PinnerSAGE V3), a static, offline-learned user representation that captures a user’s long term interest by leveraging their past interaction history on Pinterest. (View Highlight)
However, there are still some aspects that pretrained embeddings like PinnerSAGE does not cover, and we can fill in the gap by using a realtime user action sequence feature: (View Highlight)
Model pinners’ short-term interest: PinnerSAGE is trained using thousands of user actions over a long term, so it mostly captures long-term interest. On the other hand, realtime user action sequence models short-term user interest and is complementary to PinnerSAGE embedding. (View Highlight)
More responsive: Instead of other static features, realtime signals are able to respond faster. This is helpful, especially for new, casual, and resurrected users who do not have much past engagement. (View Highlight)
End-to-end optimization for recommendation model objective: We use a user action sequence feature as a direct input feature to the recommendation model and optimize directly for model objectives. Unlike PinnerSAGE, we can attend the pin candidate features with each individual sequence action for more flexibility. (View Highlight)
A stable, low latency, realtime feature pipeline supports a robust online recommendation system. We serve the latest 100 user actions as a sequence, populated with pin embeddings and other metadata. The overall architecture can be segmented to event time and request, as shown in Figure 2. (View Highlight)
To minimize the application downtime and signal failure, efforts are made in:
ML side
• Features/schema force validation
• Delayed source event handling to prevent data leakage
• Itemized actions tracking over time data shifting (View Highlight)
Ops side
• Stats monitoring on core job health, latency/throughput etc.
• Comprehensive on-calls for minimal application downtime
• Event recovery strategy (View Highlight)
We generated the following features for the Homefeed recommender model:
(View Highlight)
Figure 3 is an overview of our Homefeed ranking model. The model consumes a <user, pin> pair and predicts the action that the user takes on the candidate pin. Our input to the Pinnability model includes signals of various types, including pinner signals, user signals, pin signals, and context signals. We now add a unique, realtime user sequence signals input and use a sequence processing module to process the sequence features. With all the features transformed, we feed them to an MLP layer with multiple action heads to predict the user action on the candidate pin. (View Highlight)
Recent literature has been using transformers for recommendation tasks. Some model the recommendation problem as a sequence prediction task, where the model’s input is (S1,S2, … , SL-1) and its expected output as a ‘shifted’ version of the same sequence: (S2,S3, … , SL). To keep the current Pinnability architecture, we only adopt the encoder part of these models. (View Highlight)
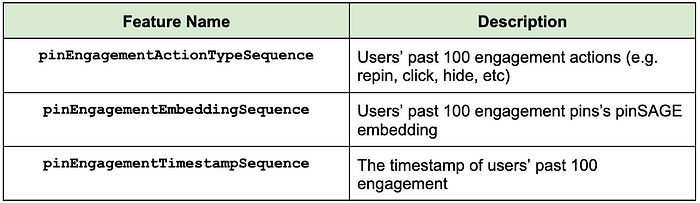
we utilized three important realtime user sequence features:
Engaged pin embedding: pin embeddings (learned GraphSage embedding) for the past 100 engaged pins in user history
Action type: type of engagement in user action sequence (e.g., repin, click, hide)
Timestamp: timestamp of a user’s engagement in user history (View Highlight)
We also use candidate pin embedding to perform early fusion with the above realtime user sequence features.
initial architecture of user sequence transformer module (View Highlight)
As illustrated in Figure 3, to construct the input of the sequence transformer module, we stack the [candidate_pin_emb, action_emb, engaged_pin_emb] to a matrix. The early fusion of candidate pin and user sequence is proved to be very important according to online and offline experiments. We also apply a random time window mask on entries in the sequence where the actions were taken within one day of request time. The random time window mask is used to make the model less responsive and to avoid diversity drop. Then we feed it into a transformer encoder. For the initial experiment, we only use one transformer encoder layer. The output of the transformer encoder is a matrix of shape [seq_len, hidden_dim]. We then flatten the output to a vector and feed it along with all other features to MLP layers to predict multi-head user actions. (View Highlight)
In our second iteration of the user sequence module (v1.1), we made some tuning on top of the v1.0 architecture. We increased the number of transformer encoder layers and compressed the transformer output. Instead of flattening the full output matrix, we only took the first 10 output tokens, concatenated them with the max pooling token, and flattened it to a vector of length (10 + 1) * hidden_dim. The first 10 output tokens capture the user’s most recent interests and the max pooling token can represent the user’s longer term preference. Because the output size became much smaller, it’s affordable to apply an explicit feature crossing layer with DCN v2 architecture on the full feature set as previously illustrated in Fig.2. (View Highlight)
Through online experiments, we saw the user engagement metrics gradually decayed in the group with realtime action sequence treatment. Figure 6 demonstrates that for the same model architecture, if we do not retrain it, the engagement gain is much smaller than if we retrain the model on fresh data. (View Highlight)
Our hypothesis is that our model with realtime features is quite time sensitive and requires frequent retraining. To verify this hypothesis, we retrain both the control group (without realtime user action feature) and the treatment group (with realtime user action feature) at the same time, and we compare the effect of retraining for both models. As shown in Figure 6, we found the retraining benefits in the treatment model much more than in the control model. (View Highlight)
Therefore, to tackle the engagement decay challenge, we retrain the realtime sequence model twice per week. In doing this, the engagement rate has become much more stable. (View Highlight)
With the transformer module introduced to the recommender model, the complexity has increased significantly. Before this work, Pinterest has been serving the Homefeed ranking model on CPU clusters. Our model increases CPU latency by more than 20x. We then migrated to GPU serving for the ranking model and are able to keep neutral latency at the same cost. (View Highlight)
On Pinterest, one of the most important user actions is repin, or save. Repin is one of the key indicators of user engagement on the platform. Therefore, we approximate the user engagement level with repin volume and use repin volume to evaluate model performance. (View Highlight)
We perform offline evaluation on different models that process realtime user sequence features. Specifically, we tried the following architectures: (View Highlight)
Average Pooling: the simplest architecture where we use the average of pin embedding in user sequence to present user’s short term interest (View Highlight)
(Convolutional Neural Network (CNN): uses CNN to encoder a sequence of pin embedding. CNN is suitable to capture the dependent relationship across local information (View Highlight)
Recurrent Neural Network (RNN): uses RNN to encoder a sequence of pin embedding. Compared to CNN, RNN better captures longer term dependencies. (View Highlight)
Lost Short-Term Memory (LSTM): uses LSTM, a more sophisticated version of RNN that captures longer-term dependencies even better than RNN by using memory cells and gating. (View Highlight)
Vanilla Transformer: encodes only the pin embedding sequence directly using the Transformer module. (View Highlight)
For Homefeed surface specifically, two of the most important metrics are HIT@3 for repin and hide prediction. For repin, we try to improve the HIT@3. For hide, the goal is to decrease HIT@3. (View Highlight)
The offline result shows us that even with the vanilla transformer and only pin embeddings, the performance is already better than other architectures. The improved transformer architecture showed very strong offline results: +8.87% offline repin and a -13.49% hide drop. The gain of improved transformer 1.0 from vanilla transformer came from several aspects: (View Highlight)
Using action embedding: this helps model distinguish positive and negative engagement (View Highlight)
Early fusion of candidate pin and user sequence: this contributes to the majority of engagement gain, according to online and offline experiment, (View Highlight)
Random time window mask: helps with diversity (View Highlight)
Then we conducted an online A/B experiment on 1.5% of the total traffic with the improved transformer model v1.0. During the online experiment, we observed that the repin volume for overall users increased by 6%. We define the set of new, casual, and resurrected users as non-core users. And we observed that the repin volume gain on non-core users can reach 11%. Aligning with offline evaluation, the hide volume was decreased by 10%. (View Highlight)
Recently, we tried transformer model v1.1 as illustrated in Figure 4, and we achieved an additional 5% repin gain on top of the v1.0 model. Hide volume remains neutral for v1.0. (View Highlight)
We want to call out an interesting observation: the online experiment underestimates the power of realtime user action sequence. We observed higher gain when we rolled out the model as the production Homefeed ranking model to full traffic. This is because the learning effect of positive feedback loop: (View Highlight)
As users see a more responsive Homefeed, they tend to engage with more relevant content, and their behavior changed (for example, more clicks or repins) (View Highlight)
With this behavior change, the realtime user sequence that logs their behavior in realtime also shifted. For example, there are more repin actions in the sequence. Then we generate the training data with this shifted user sequence feature. (View Highlight)
As we retrain the Homefeed ranking model with this shifted dataset, there’s a positive compounding effect that makes the retrained model more powerful, thus, a higher engagement rate. This then loops us back to 1. (View Highlight)
Our work to use realtime user action signals in Pinterest’s Homefeed recommender system has greatly improved the Homefeed relevance. Transformer architecture turns out to work best among other traditional sequence modeling approaches. There were various challenges along the way and are non-trivial to tackle. We discovered that retraining the model with realtime sequence is important to keep up the user engagement. And that GPU serving is indispensable for large scale, complex models. (View Highlight)
Feature Improvement: We plan to develop a more fine-grained realtime sequence signal that includes more action types and action metadata. (View Highlight)
GPU Serving Optimization: This is the first use case to use GPU clusters to serve large models at organic scale. We plan to improve GPU serving usability and performance. (View Highlight)
Model Iteration: We will continue working on the model iteration so that we fully utilize the realtime signal. (View Highlight)
Adoption on Other Surfaces: We’ll try similar ideas in other surfaces: related pins, notifications, search, etc. (View Highlight)
(View Highlight)
 (View Highlight)
(View Highlight)(View Highlight)
initial architecture of user sequence transformer module (View Highlight)
(View Highlight)