Generating images with a consistent style is a valuable technique in Stable Diffusion for creative works like logos or book illustrations. This article provides step-by-step guides for creating them in Stable Diffusion. (View Highlight)
• Consistent style with Style Aligned (AUTOMATIC1111 and ComfyUI)
• Consistent style with ControlNet Reference (AUTOMATIC1111)
• The implementation difference between AUTOMATIC1111 and ComfyUI
• How to use them in AUTOMATIC1111 and ComfyUI (View Highlight)
Style Alignedshares attention across a batch of images to render similar styles. Let’s go through how it works.
Stable Diffusion models use the attention mechanism to control image generation. There are two types of attention in Stable Diffusion.
• Cross Attention: Attention between the prompt and the image. This is how the prompt steers image generation during sampling.
• Self-Attention: An image’s regions interact with each other to ensure quality and consistency. (View Highlight)
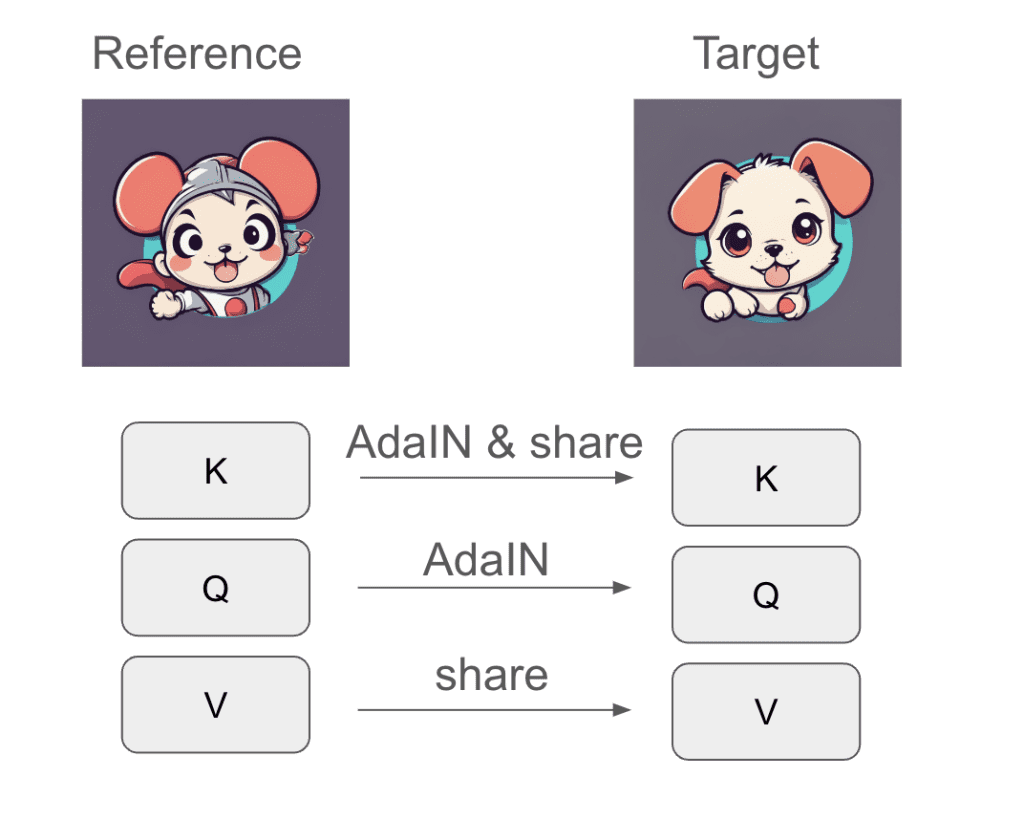
Style Aligned lets images in the same batch share information during self-attention. Three important quantities of attention are query (Q), key (K), and value (V). In self-attention, they are all derived from the latent image. (In cross-attention, the query is derived from the prompt.)
(View Highlight)
Style Aligned injects the style of a reference image by adjusting the queries and keys of the target images to have the mean and variance as the reference. This technique is called Adaptive Instance Normalization (AdaIN) and is widely used in style transfer. The images also share the keys and values. (View Highlight)
The choice of where to apply AdaIN and attention sharing is quite specific. As we will see later, it doesn’t matter that much. Applying AdaIN and sharing in different ways achieves similar results. (View Highlight)
Although both AUTOMATIC1111 and ComfyUI claim to support Style Align, their implementations differ. (View Highlight)
In AUTOMATIC1111, the Style Align option in ControlNet is NOT the Stye Align described in the paper. It is a simplified version that the paper’s authors called fully shared attention. It simply joins the queries, keys, and values of the images together in cross-attention. In other words, it allows the images’ regions in the same batch to interact during sampling. (View Highlight)
As we will see, this approach is not ideal because too much information is shared across the images, causing the images to lose their uniqueness.
However, not all is lost. The reference ControlNet provides a similar function. Three variants are available:
Reference method
Attention hack
Group normalization hack
Reference_only
Yes
No
Reference_adain
No
Yes
Reference_adain+attn
Yes
Yes (View Highlight)
The attention hack adds the query of the reference image into the self-attention process.
(View Highlight)
The group normalizationhack injects the distribution of the reference image to the target images in the group normalization layer. It predates Style Aligned and uses the same AdaIN operation to inject style but into a different layer.
(View Highlight)
Consistent style in ComfyUI
The style_aligned_comfy implements a self-attention mechanism with a shared query and key. It is faithful to the paper’s method. In addition, it has options to perform A1111’s group normalization hack through the shared_norm option. (View Highlight)

 (View Highlight)
(View Highlight)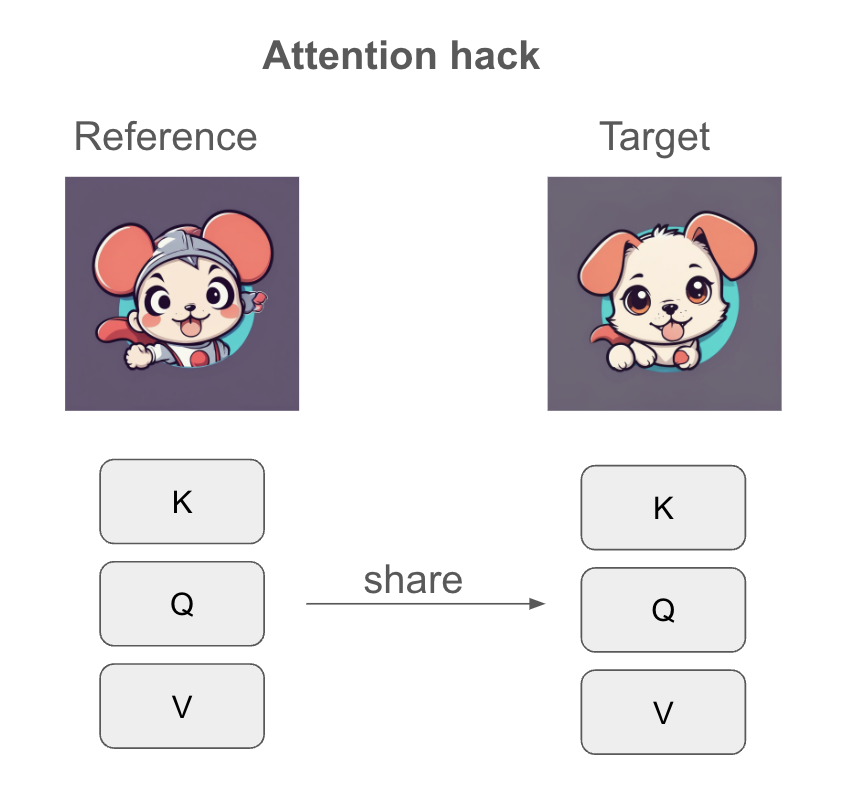 (View Highlight)
(View Highlight)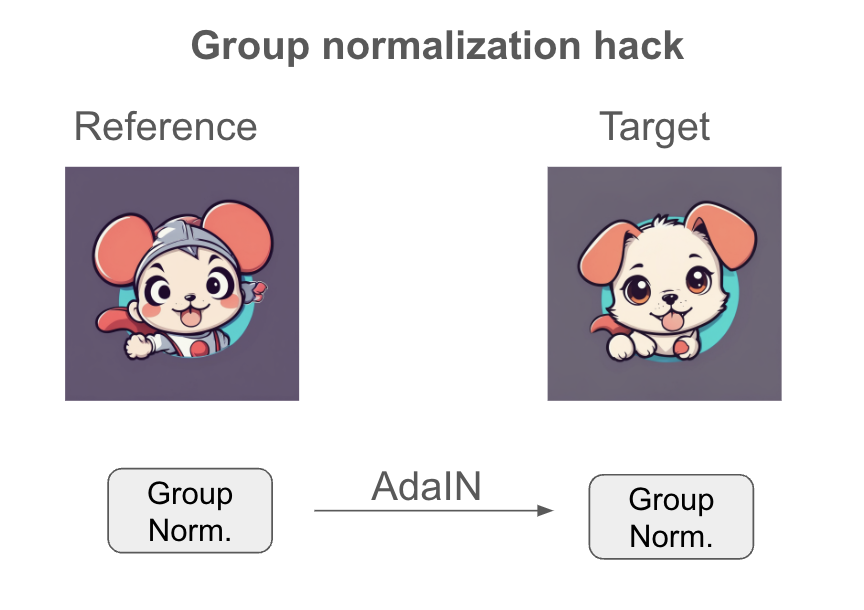 (View Highlight)
(View Highlight)