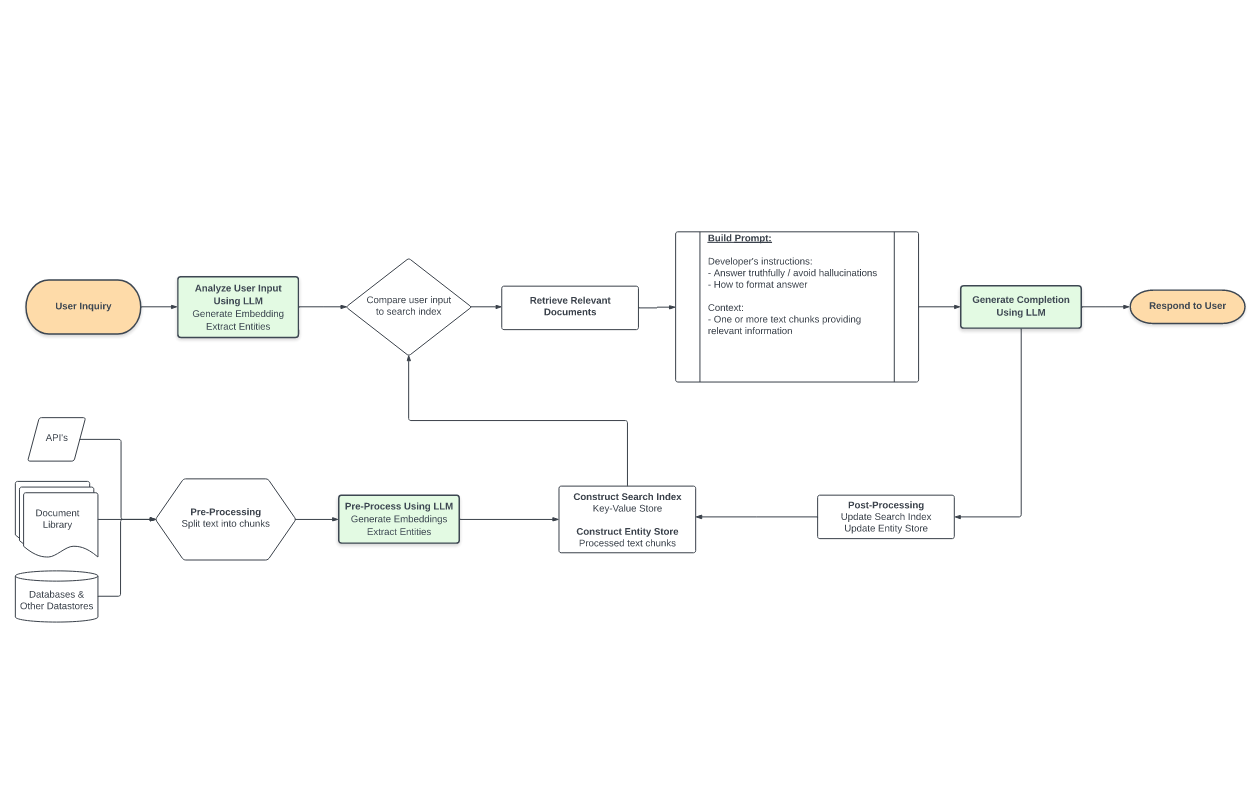
there are instances in which you want the language model to generate an answer based on specific data, rather than supplying a generic answer based on the model’s training set. (View Highlight)
Retrieval-augmented generation a) retrieves relevant data from outside of the language model (non-parametric) and b) augments the data with context in the prompt to the LLM. (View Highlight)
a typical prerequisite is to split text into sections (for example, via utilities in the LangChain package), then calculate embeddings on those chunks. (View Highlight)
when a user submits a question, an LLM processes the message in multiple ways, but the key step is calculating another embedding - this time, of the user’s text. (View Highlight)
This semantic search is based on the “learned” concepts of the language model and is not limited to just a search for keywords. From the results of this search, we can quantitatively identify one or more relevant text chunks that could help inform the user’s question. (View Highlight)
Finally, we provide the relevant information from which the language model can answer using specific data. In its simplest form, we simply append (“Document 1: ”+ text chunk 1 + “\nDocument 2: ” + text chunk 2 + …) until the context is filled. (View Highlight)
. Embedding this document and searching for relevant (real) examples in the datastore retrieves more relevant results; the relevant results are used to generate the actual answer seen by the user (View Highlight)
Vector Store Index - This is equivalent to the simple design that I explained in the previous section. Each text chunk is stored alongside an embedding; comparing a query embedding to the document embeddings returns the k most similar documents to feed into the context. (View Highlight)
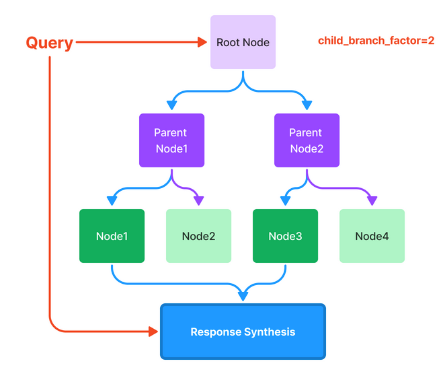
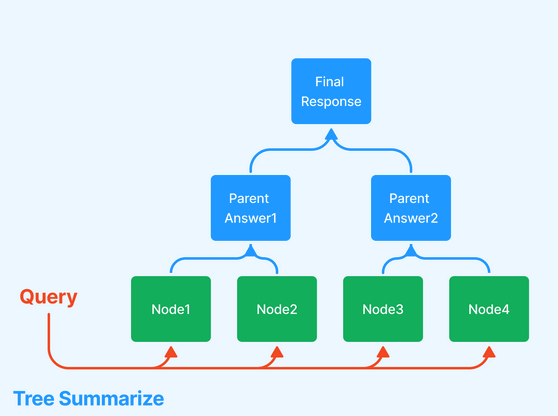
• Tree Index - This is extremely useful when your data is organized into hierarchies. Consider a clinical documentation application: you may want the text to include both high-level instructions (“here are general ways to improve your heart health”) and low-level text (reference side effects and instructions for a particular blood pressure drug regimen). There are a few different ways of traversing the tree to generate a response, two of which are shown below.
(View Highlight)
(View Highlight)
 (View Highlight)
(View Highlight)