Our mission at Pinterest is to bring everyone the inspiration to create the life they love. Machine Learning plays a crucial role in this mission. It allows us to continuously deliver high-quality inspiration to our 460 million monthly active users, curated from billions of pins on our platform. Behind the scenes, hundreds of ML engineers iteratively improve a wide range of recommendation engines that power Pinterest, processing petabytes of data and training thousands of models using hundreds of GPUs. (View Highlight)
Recently, we started to notice an interesting trend in the Pinterest ML community. As model architecture building blocks (e.g. transformers) became standardized, ML engineers started to show a growing appetite to iterate on datasets. This includes sampling strategies, labeling, weighting, as well as batch inference for transfer learning and distillation. (View Highlight)
While such dataset iterations can yield significant gains, we observed that only a handful of such experiments were conducted and productionized in the last six months. This motivated us to look deeper into the development process of our ML engineers, identify bottlenecks, and invest in ways to improve the dataset iteration speed in the ML lifecycle. (View Highlight)
In this blogpost, we will share our assessment of the ML developer velocity bottlenecks and delve deeper into how we adopted Ray, the open source framework to scale AI and machine learning workloads, into our ML Platform to improve dataset iteration speed from days to hours, while improving our GPU utilization to over 90%. We will go even deeper into this topic and our learnings at the Ray Summit 2023. Please join us at our suggestion there to learn more in detail! (View Highlight)
At Pinterest, ML datasets used for recommender models are highly standardized. Features are shared, represented in ML-friendly types, and stored in parquet tables that enable both analytical queries and large scale training. (View Highlight)
However, even with a high level of standardization, it is not easy to iterate quickly with web-scale data produced by hundreds of millions of users. Tables have thousands of features and span several months of user engagement history. In some cases, petabytes of data are streamed into training jobs to train a model. In order to try a new downsampling strategy, an ML engineer needs to not only figure out a way to process extremely large scales of data, but also pay wall-clock time required to generate new dataset variations. (View Highlight)
Pattern 1: Apache Spark Jobs Orchestrated through Workflow Templates (View Highlight)
Figure 1: Dataset iteration by chaining Spark jobs and Torch jobs using Airflow (Workflow based ML Training Inner loop) (View Highlight)
One of the most common technologies that ML engineers use to process petabyte scale data is Apache Spark. ML engineers chain a sequence of Spark and Pytorch jobs using Airflow, and package them as “workflow templates” that can be reused to produce new model training DAGs quickly. (View Highlight)
However, as ML is rapidly evolving, not all dataset iteration needs can be supported quickly by workflow templates. It often requires a long process that touches many languages and frameworks. ML engineers have to write new jobs in scala / PySpark and test them. They have to integrate these jobs with workflow systems, test them at scale, tune them, and release into production. This is not an interactive process, and often bugs are not found until later. (View Highlight)
We found out that in some cases, it takes several weeks for an ML engineer to train a model with a new dataset variation using workflows! This is what we call the “scale first, learn last” problem. (View Highlight)
Pattern 2: Last Mile Processing in Training Jobs (View Highlight)
Since it takes so long to iterate on workflows, some ML engineers started to perform data processing directly inside training jobs. This is what we commonly refer to as Last Mile Data Processing. Last Mile processing can boost ML engineers’ velocity as they can write code in Python, directly using PyTorch. (View Highlight)
However, this approach has its own challenges. As ML engineers move more data processing workloads to the training job, the training throughput slows down. To address this, they add more data loader workers that require more CPU and memory. Once the CPU / memory limit is reached, ML engineers continue to scale the machines vertically by provisioning expensive GPU machines that have more CPU and memory. The GPU resources in these machines are not adequately utilized as the training job is bottle-necked on CPU. (View Highlight)
Even if we horizontally scale the training workload through distributed training, it is very challenging to find the right balance between training throughput and cost. These problems become more prominent as the datasets get larger and the data processing logic gets more complicated. In order to make optimal usage of both CPU and GPU resources, we need the ability to manage heterogeneous types of instances and distribute the workload in a resource-aware manner. (View Highlight)
Solution: Using Ray for Last Mile Processing (View Highlight)
Having visited the above two patterns, we believe that horizontally scalable Last Mile Data Processing is the direction to achieve fast and efficient dataset iteration. (View Highlight)
The ideal solution should have three key capabilities:
• Distributed Processing: Able to efficiently parallelize large scale data processing across multiple nodes
• Heterogeneous Resource Management: Capable of managing diverse resources, like GPU and CPU, ensuring workloads are scheduled on the most efficient hardware
• High Dev Velocity: Everything should be in a single framework, so that users don’t have context switch between multiple systems when authoring dataset experiments (View Highlight)
After evaluating various open-source tools, we decided to go with Ray. We were very excited to see that Ray not only fulfills all the requirements we have but also presents a unique opportunity to provide our engineers a unified AI Runtime for all the MLOps components, not only just data processing but also distributed training, hyperparameter tuning, serving, etc. with first class support for scalability. (View Highlight)
With Ray, ML engineers start their development process by spinning up a dedicated, heterogeneous Ray Cluster that manages both CPU and GPU resources. This process is automated through the unified training job launcher tool, which also bootstraps the Ray driver that manages both data processing and training compute in the Cluster. In the driver, users can also invoke a programmable launcher API to orchestrate distributed training with the PyTorch training scripts that ML engineers author across multiple GPU nodes. (View Highlight)
Scalable Last Mile Data processing is enabled by adopting Ray Data in this driver. Ray Data is a distributed data processing library built on top of Ray that supports a wide variety of data sources and common data processing operators. One of the key breakthrough functionalities we saw from Ray data is its streaming execution capability. This allows us to concurrently transform data and train at the same time. This means that (1) we do not need to load the entire dataset in order to process them, and (2) we do not need for the data computation to be completely finished in order for training to progress. ML engineers can receive feedback on their new dataset experimentation logic in a matter of minutes. (View Highlight)
With streaming execution, we can significantly lower the resource requirement for petabytes data ingestion, speed up the computation, and give ML engineers immediate, end-to-end feedback as soon as the first data block is ingested. Furthermore, In order to improve the data processing throughput, the ML engineer simply needs to elastically scale the CPU resources managed by the heterogeneous Ray cluster. (View Highlight)
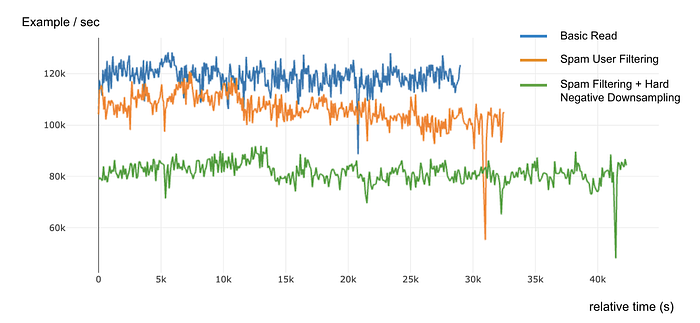
To assess the benefits of using Ray for Last Mile Data Processing, we conducted a set of benchmarks by training models on the same model architecture while progressively increasing the Last Mile Data Processing workloads. (View Highlight)
To our surprise, the Ray dataloader showed a 20% improvement in the training throughput even without any Last Mile Data Processing. Ray dataloader handled extremely large features like user-sequence features much better than torch dataloader. (View Highlight)
The improvement became more prominent as we started to incorporate more complex data-processing and downsampling logic into the data loader. After adding spam-user filtering (map-side join) and dynamic negative downsampling, Ray dataloader was up to 45% faster than our torch based implementation. This means that an ML engineer can now gain 2x the learnings from training experimental models within the same time as before. While we had to horizontally scale the data-loaders by adding more CPU nodes, the decrease in training time ultimately allowed us to save cost by 25% for this application as well. (View Highlight)
When ML engineers conducted the same experiment by writing Spark jobs and workflows, it took them 90 hours to train a new model. With Ray, the ML engineers were able to reduce this down to 15 hours, a whopping +6x improvement in developer velocity! (View Highlight)
This post only touches on a small portion of our journey in Pinterest with Ray and marks the beginning of the “Ray @ Pinterest” blog post series. Spanning multiple parts, this series will cover the different facets of utilizing Ray at Pinterest: infrastructure setup and advanced usage patterns including feature importance and transfer learning. Stay tuned for our upcoming posts! (View Highlight)

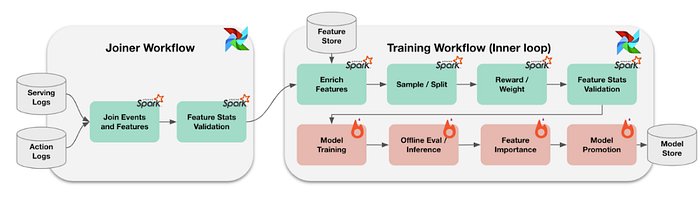 Figure 1: Dataset iteration by chaining Spark jobs and Torch jobs using Airflow (Workflow based ML Training Inner loop) (View Highlight)
Figure 1: Dataset iteration by chaining Spark jobs and Torch jobs using Airflow (Workflow based ML Training Inner loop) (View Highlight)(View Highlight)
 (View Highlight)
(View Highlight)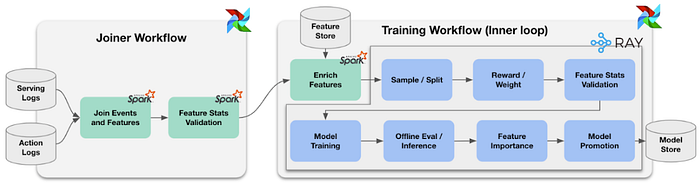 (View Highlight)
(View Highlight)(View Highlight)