Metadata
- Author: Anas Awadalla
- Full Title: MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset With One Trillion Tokens
- URL: https://blog.salesforceairesearch.com/mint-1t/?s=09
Highlights
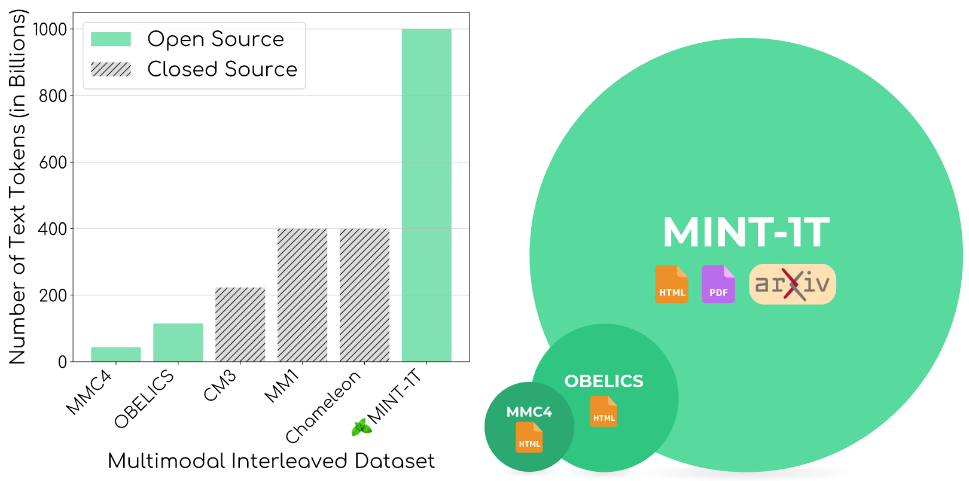
- We are excited to open-source 🍃MINT-1T, the first trillion token multimodal interleaved dataset and a valuable resource for the community to study and build large multimodal models. (View Highlight)
- Multimodal interleaved documents are sequences of images interspersed in text. This structure allows us to train large multimodal models that can reason across image and text modalities. Some of the most capable multimodal models like MM1, Chameleon, and Idefics2 have shown the importance of training on interleaved data to attain best performance. (View Highlight)
- Our key principles behind curating 🍃MINT-1T are scale and diversity. While previous open-source datasets such as OBELICS and MMC4, where at most 115 billion tokens, we collect 1 trillion tokens for 🍃MINT-1T allowing practitioners to train much larger multimodal models. To improve the diversity of 🍃MINT-1T we go beyond HTML documents, and include web-scale PDFs and ArXiv papers. We find that these additional sources improve domain coverage particularly on scientific documents. (View Highlight)
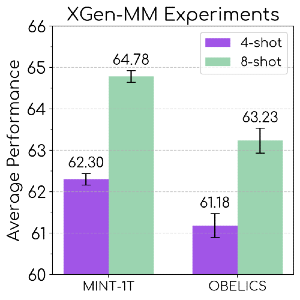 (View Highlight)
(View Highlight)- (View Highlight)
- Note: The axis…