
Metadata
- Author: Craig Walls
- Full Title: Optimizing API Output for Use as Tools in Model Context Protocol
- URL: https://thetalkingapp.medium.com/optimizing-api-output-for-use-as-tools-in-model-context-protocol-mcp-07d93a084fbc
Highlights
- Now, as the hot topic of Agentic AI is front and center, it’s becoming increasingly clear that tools are going to be critical to enabling agents to take actions and seek information on our behalf. Moreover, Model Context Protocol (MCP) provides a standardized way to create modules of tools and to share those modules across AI-enabled applications. And there’s definitely a place for MCP Servers that wrap existing APIs to bridge the chasm between GenAI and existing enterprise APIs. (View Highlight)
- MCP has been taking up a rather large space in my mind for the past couple of months. And now that Spring AI has support for developing both MCP Servers and MCP Clients to consume those servers, I’ve spent a lot of time building both. In doing so, I made a few mistakes, learned a few lessons, and now want to share one of those lessons with you so that you can make best use of MCP. I’ve made the mistakes so you don’t have to. (View Highlight)
- My first attempt at creating an MCP Server from ThemeParks.wiki API’s endpoints involved simply exposing each endpoint as a tool. This 1-to-1 mapping from endpoint to tools was very straightforward: Use Spring’s RestClient to make HTTP GET requests to each endpoint in the context of a tool definition. Nothing fancy at all.
Using the new
@Toolannotation from Spring AI (currently in snapshot builds, but soon to be available in the Milestone 6 release), I first created a service class that defined one@Toolmethod for each endpoint. (View Highlight) - And then, I exposed these methods as tools in an MCP Server (View Highlight)
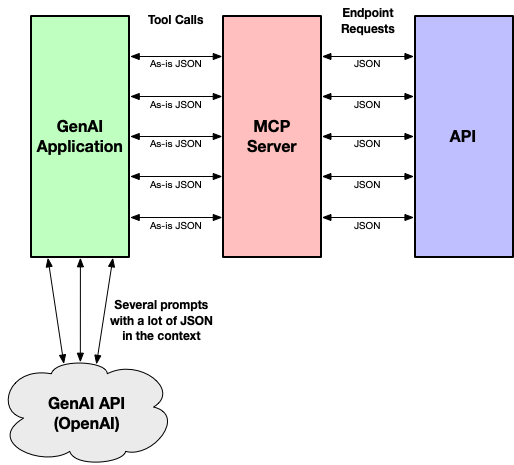
- And, it worked. Well…it sorta worked. Sometimes it worked. But not always. When it worked, it was slow. And when it didn’t work, it often failed because I was exceeding a tokens-per-minute (TPM) rate limit from OpenAI. After turning up the logging and doing a bit of detective work, I realized that while all of the tools were made available to the LLM, including reasonably good descriptions, the LLM was struggling to find the entity IDs for some items. So it was making frequent calls to those tools, in a sort of trial-and-error approach, to find what it was looking for. (View Highlight)
- What’s more, given that the JSON returned from both the destinations and schedule endpoints is so large, the prompt context was being filled with mostly irrelevant data. The destinations endpoint, for example, returns every resort area and theme park supported by the API. And the schedule endpoints each return a full month’s worth of schedule data, even if you only need 1 day. As a result, each time I asked why time a park opens or closes, I was burning through a huge number of tokens. Not only was this wasteful, it fully explained why I kept getting smacked with TPM rate limits. (View Highlight)
- Of course, one choice I could (and did) make is to switch to GPT-4o-mini. This model is significantly less expensive and has a much higher TPM limit (200,000 tokens per minute). But that felt like sweeping the problem under the rug. (View Highlight)
- After a bit of thinking, it became very clear what the issues are: • The data from the destinations endpoint is resort area-centric, but most questions asked are more theme parks-focused. This made things more difficult for the LLM to find the entity ID for a given theme park. • The destinations endpoint and the schedule endpoints returns enormous amounts of JSON, most of which is irrelevant for the questions being asked. If being asked about Epcot, you don’t really need to know the entity ID for Six Flags Over Texas. If asking about park hours for tomorrow, you don’t really need to know the park hours for any date except for tomorrow’s date. (View Highlight)
- These two issues taken together explain why so many tokens were being used for each question. The 23K-93K tokens weren’t sent in a single prompt — the JSON is big, but not that big. But the big JSON being sent as context in several prompts while the LLM was fumbling about trying to find an entity ID added up quickly.
 (View Highlight)
(View Highlight) - Put simply, the ThemeParks.wiki API isn’t designed to be optimally used directly as the underpinnings of an MCP server.
It was suggested to me that I shouldn’t code the MCP Server myself, but rather take advantage of the fact that ThemeParks.wiki API has an OpenAPI (note the “P”) specification and use a prebuilt MCP Server that magically exposes OpenAPI endpoints as tools in the MCP Server. I tried that, but since the OpenAPI MCP Server is exposing one tool per endpoint with no filtering of the data returned, the core issues remain the same. (View Highlight)
- Ideally, the ThemeParks.wiki API would be optimized, offering endpoints that are more focused on specific theme parks, attractions, etc. But we shouldn’t be quick to blame the designer for the problems I’ve encountered. The API was designed before MCP (or even the current buzz around GenAI) existed. There’s no question that network bandwidth could be conserved with some adjustments to the API, but typical use of the API outside of the realm of GenAI isn’t impacted by how the API is currently designed. It’s only in a GenAI/MCP situation where the pain is felt. (View Highlight)
- But if I can’t optimize the API for use with MCP, then I can certainly optimize how it’s used by the MCP Server. So that’s what I did. One seemingly obvious optimization is to cache the results from the destinations endpoint. This would avoid unnecessarily hitting the API repeatedly to fetch the same data the doesn’t change often. But it does absolutely nothing to reduce token usage. (View Highlight)
- Next, I took the JSON coming from the destinations endpoint and inverted it such that instead of having resort areas with theme parks as children, the theme parks are the top level item with properties for the resort area’s entity ID and name. This makes it a bit easier for the LLM to sift through the data to find the entity ID for a given theme park. (View Highlight)
- I then wrote some code to filter the inverted data, seeking out a theme park entry by its name. This is less than perfect, of course. Although the filtering normalizes the name to lowercase and searches for substrings (so that “Animal kingdom” will match “Disney’s Animal Kingdom”), it doesn’t work as well if the requested park has a typo in its name (e.g., “Disbeyland” won’t match “Disneyland”). But for the most part, it works well. I’m already thinking of ways to overcome the shortcomings of this, but for now I’m pleased with how well it works. (View Highlight)
- Note that in both cases, the methods now return a
ListofParkorScheduleEntryinstead of a JSON-filledString. WhileStringresponses were sufficient for the initial work, domain types made it easier to do the filtering and manipulation required. In either case, the results end up as JSON in the prompt context, so the choice ofStringversus domain-specific types had negligible effect on the overall performance.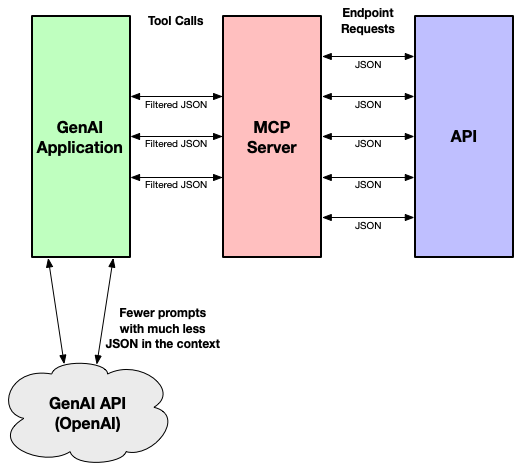 (View Highlight)
(View Highlight) - With these changes made to my MCP Server implementation, I tried everything again. And it worked brilliantly! I was getting good answers to all of my questions, typically faster than before, and was never hitting a rate limit! (View Highlight)
- Although using a prebuilt OpenAPI MCP Server would’ve been an easy way to integrate with the API, there’s no way to achieve these same results without going back to the API itself and applying the optimizations there. (View Highlight)
- The key takeaway is that as GenAI, Agentic AI, and MCP continue to be adopted and applied, there will be a desire to integrate with existing APIs to solve problems. It’s quite likely that those existing APIs will have been designed without consideration of how they may be used as tools made available to an LLM. (View Highlight)