In previous posts, we started by analyzing the efforts to carry out Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF), and the importance of having high-quality data (first and second blog posts). Nevertheless, RLHF is complex and usually unstable, so we examined a promising alternative, Direct Preference Optimization (DPO), to align the LLM with human preferences without requiring RL (third blog post). Still, DPO does not solve all the shortcomings, for instance, a large amount of preference data is needed to fine-tune. To tackle this, researchers have come up with new methods. Some of them are Reinforcement Learning AI Feedback (RLAIF) or Self-Play Fine-Tuning (SPIN) (fourth and fifth blog posts). For better data alignment, we also explored the benefits of Identity Preference Optimization (IPO) and Kahneman-Tversky Optimization (KTO) (sixth and seventh blog posts). (View Highlight)
To improve the process, several approaches have been developed from different perspectives. However, have you ever thought about implementing RL directly during the SFT? That’s exactly what Odds Ratio Preference Optimization (ORPO) suggests. (View Highlight)
Currently, the number of models is continually increasing, and training each one demands significant resources and time. So when we want to tailor them to our needs, we apply instruction tuning and preference alignment. First, we fine-tune the model with instructions specific to the task we want it to perform. Then, through preference tuning, we improve its responses, ensuring they’re accurate and steer clear of any harmful or unethical content, and optimizing its performance across other NLP tasks. (View Highlight)
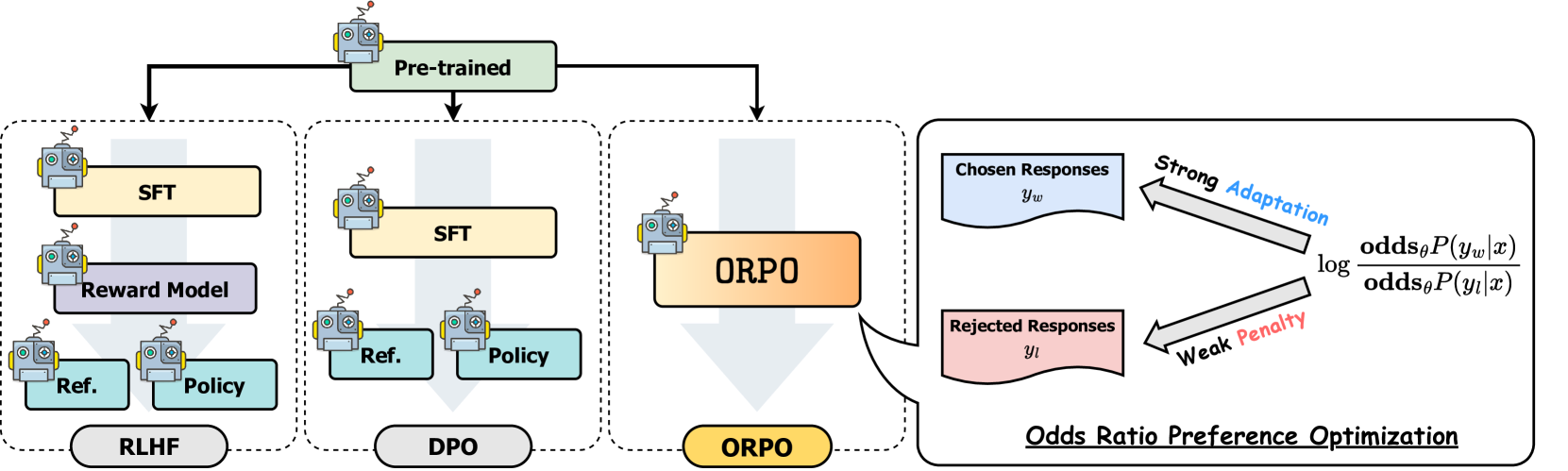
However, this approach involves several models and training stages to achieve the expected results (think RLHF with its SFT, RM, and PPO steps, or DPO with its SFT and DPO stages). And, in the center of all of them, SFT plays a crucial role in achieving a successful convergence.
(View Highlight)
Although previous studies had already shed light on the relevance of SFT in alignment, the researchers analyzed it in deep and found a shortcoming. SFT increased the likelihood of obtaining the desired tokens, but it also raised the probability of generating undesired outcomes. This led to the search for a mechanism that would still adapt the models to the specific domain, but at the same time penalize undesired responses. This is how ORPO came about. (View Highlight)
ORPO combines instruction tuning and preference alignment in a single process, making it reference model-free and computationally more efficient. It is not only more efficient in terms of resources but also saves memory and should perform fewer FLOPs.
ORPO creates a new objective by using an odds ratio-based loss to penalize undesirable responses along with conventional negative log-likelihood loss (NLL), allowing it to distinguish between favorable and unfavorable responses. Thus, it includes two main components:
• SFT loss: The NLL loss function for conventional language causal modeling, maximizes the probability of generating the reference tokens.
• Relative ratio loss: Maximizes the odds ratio between the generation of the favored and the disfavored response.
Together, these components guide the LLM to adapt to the desired generations for the specific domain and disfavor the generations in the set of rejected responses. (View Highlight)
When comparing the win rate and reward distribution of ORPO with those of SFT, PPO, and DPO, an increase was observed across all model sizes in both data sets. In the first case, ORPO was preferred over SFT and PPO, reaching a maximum win rate of 85%; while the win rate of DPO showed a proportional increase with model size. Moreover, upon examining lexical diversity, it became apparent that ORPO tended to assign higher probabilities to desirable tokens and to generate more specific responses.
(View Highlight)
While ORPO has demonstrated encouraging results, its generalizability across various tasks, and domains, or when scaled to larger language models, remains to be thoroughly examined. A broader comparative analysis with other preference alignment algorithms beyond the commonly referenced DPO and RLHF would be beneficial. Additionally, exploring the potential integration of ORPO with these algorithms could provide valuable insights.
ORPO, with its novel approach based on likelihood ratios, offers a fresh perspective on model alignment that could lead to significant efficiency gains in resources. Its methodology is straightforward yet effective, enabling the fine-tuning of language models to not only specific domains but also to align their responses. In a context where LLMs are becoming more numerous and experimentation more frequent, ORPO presents itself as a valuable alternative. Although further research and experiments are needed, the results so far are promising. (View Highlight)

 (View Highlight)
(View Highlight)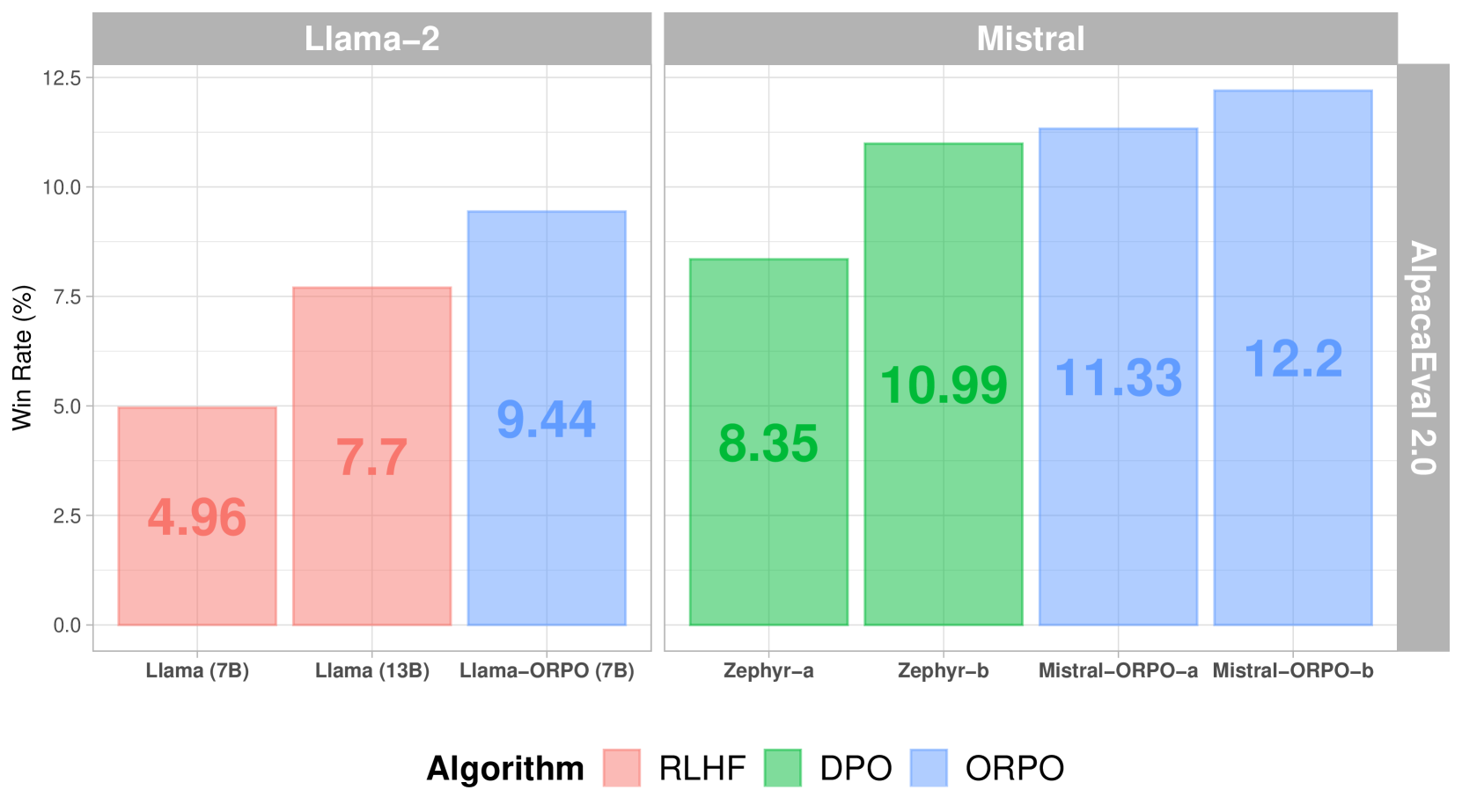 (View Highlight)
(View Highlight)