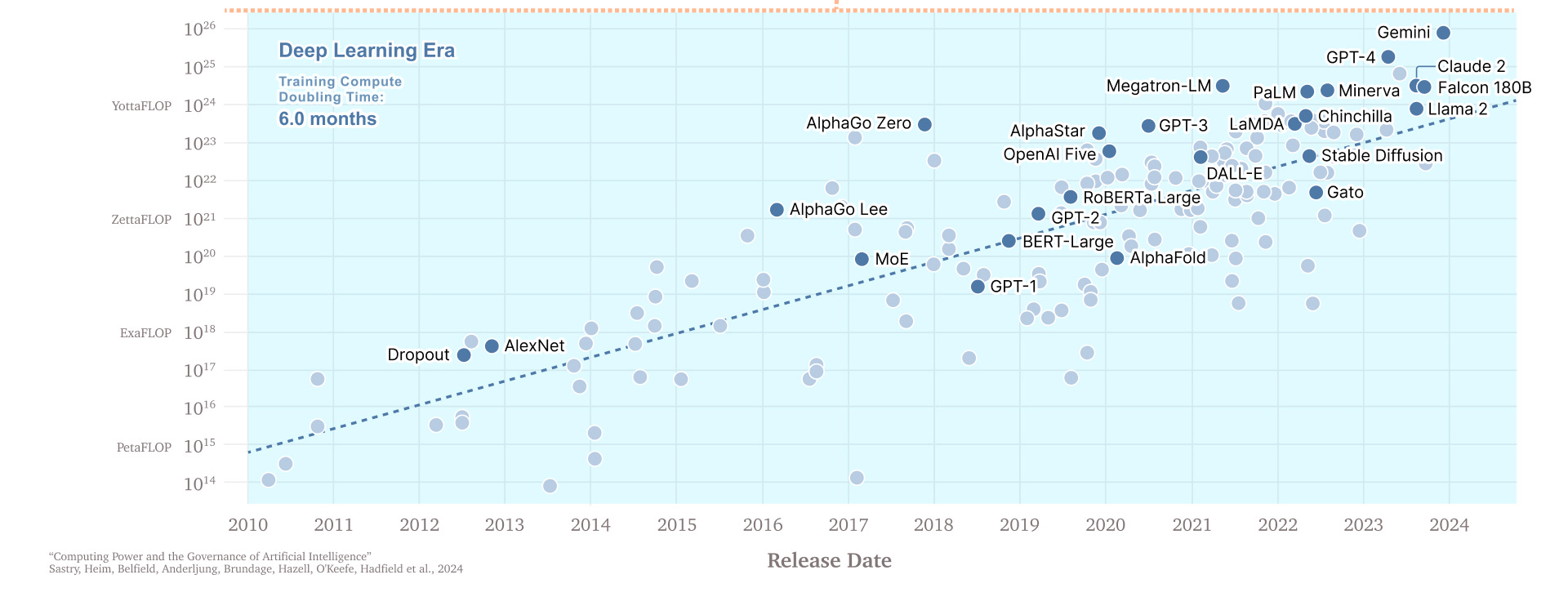
To understand where we are with LLMs you need to understand scale. As I warned, I am going to oversimplify things quite a bit, but there is an “scaling law” (really more of an observation) in AI that suggests the larger your model, the more capable it is. (View Highlight)
Scale really does matter. Bloomberg created BloombergGPT to leverage its vast financial data resources and potentially gain an edge in financial analysis and forecasting. This was a specialized AI whose dataset had large amounts of Bloomberg’s high-quality data, and which was trained on 200 ZetaFLOPs (that is 2 x 10^23) of computing power. It was pretty good at doing things like figuring out the sentiment of financial documents… but it was generally beaten by GPT-4, which was not trained for finance at all. GPT-4 was just a bigger model (the estimates are 100 times bigger, 20 YottaFLOPs, around 2 x 10^25) and so it is generally better than small models at everything. This sort of scaling seems to hold for all sorts of productive work - in an experiment where translators got to use models of different sizes: “for every 10x increase in model compute, translators completed tasks 12.3% quicker, received 0.18 standard deviation higher grades and earned 16.1% more per minute.” (View Highlight)
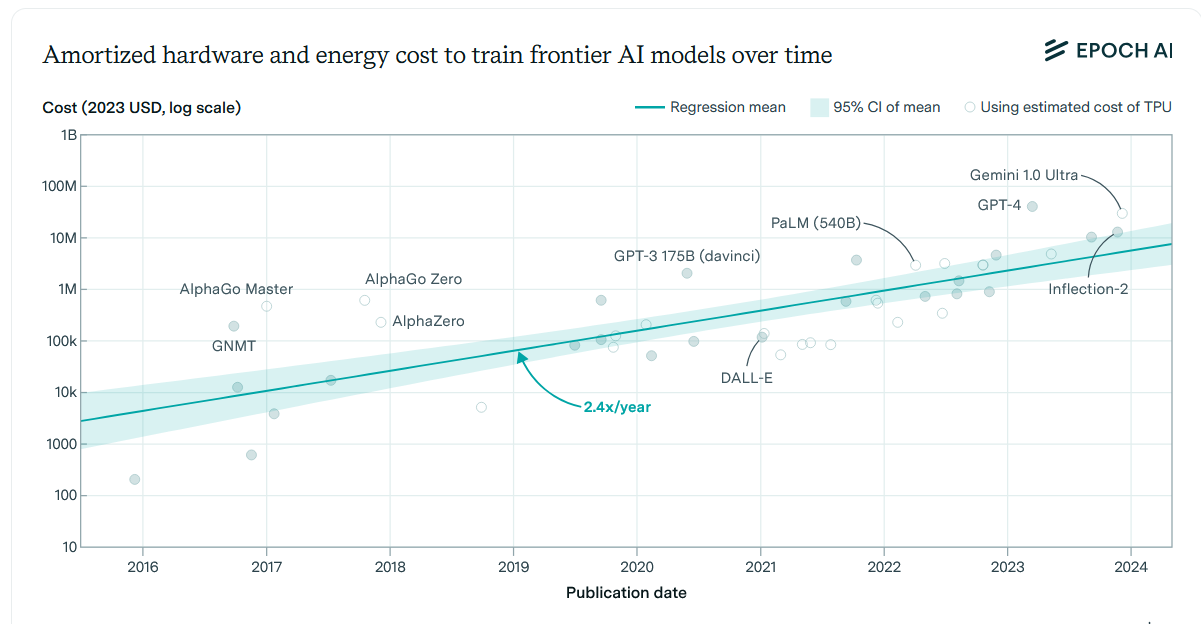
Larger models also require more effort to train. This is not just because you need to gather more data, but also that larger models require more computing time, which in turn requires more computer chips and more power to run them. The pattern of improvement happens in orders of magnitude. To get a much more capable model, you need to increase, by a factor of ten or so, the amount of data and computing power needed for training. That also tends to increase the cost by an order of magnitude as well.
(View Highlight)
So, for simplicity’s sake, let me propose the following very rough labels for the frontier models. Note that these generation labels are my own simplified categorization to help illustrate the progression of model capabilities, not official industry terminology:
• Gen1 Models (2022): These are models with the capability of ChatGPT-3.5, the OpenAI model that kicked off the Generative AI whirlwind. They require less than 10^25 FLOPs of compute and typically cost 10Morundertotrain.TherearemanyGen1models,includingopen−sourceversions.•Gen2Models(2023−2024):ThesearemodelswiththecapabilityofGPT−4,thefirstmodelofitsclass.Theyrequireroughlybetween1025and1026FLOPsofcomputeandmightcost100M or more to train. There are now multiple Gen2 models.
• Gen3 Models (2025?-2026?): As of now, there are no Gen3 models in the wild, but we know that a number of them are planned for release soon, including GPT-5 and Grok 3. They require between 10^26 and 10^27 FLOPs of compute and a billion dollars (or more) to train.
• Gen4 Models, and beyond: We will likely see Gen4 models in a couple of years, and they may cost over $10B to train. Few insiders I have spoken to expect the benefits of scaling to end before Gen4, at a minimum. Beyond that, it may be possible that scaling could increase a full 1,000 times beyond Gen3 by the end of the decade, but it isn’t clear. This is why there is so much discussion about how to get the energy and data needed to power future models. (View Highlight)
GPT-4o. This is the model that powers ChatGPT, as well as Microsoft Copilot. It also has the most bells and whistles of any of the current frontier models and has been the leading model in head-to-head comparisons. It is multimodal, which means it can work with voice, image and files (including PDFs and spreadsheets) data, and can produce code. It is also capable of outputting voice, files, and images (using an integrated image generator, DALL-E3). It also can search the web and run code through Code Interpreter. Unlike other models that use voice, GPT-4o has an advanced voice mode that is much more powerful because the model itself is listening and talking - other models use text-to-speech, where your speech is converted into text and then given to the model, and where a separate program reads the model’s answers. If you are getting started with AI, GPT-4o is a good choice, and it is probably a model most people working seriously with AI will want to use at least some of the time. (View Highlight)
Claude 3.5 Sonnet. A very clever Gen2 model, Sonnet is particularly good at working with large amounts of text. It is partially multimodal and can work with images or files (including PDFs) and can output text or small programs called artifacts that can run directly from the application. It can’t produce images or voices, can’t run data analysis code easily, and is not connected to the web. The mobile app is quite good, and this is a model I find myself using most often right now when working with writing. In fact, I usually ask it for feedback on my blog posts after I am done writing them (it helped come up with a good way to describe FLOPs in this post). (View Highlight)
Gemini 1.5 Pro. This is Google’s most advanced model. It is partially multimodal, so it can work with voice, text, files, or image data, and it is also capable of outputting voice and images (its voice mode uses text to speech, rather than being natively multimodal right now). It has a massive context window, so it can work with a tremendous amount of data, and also can process video. It also can search the web and run code (sometimes, it isn’t always clear when it can run code and when it cannot). It is a little confusing because the Gemini web interface runs a mix of models, but you can access the most powerful version, Gemini 1.5 Pro Experimental 0827 (I told you naming is awful) directly via Google’s AI studio. (View Highlight)
Grok 2. From Elon Musk’s X.AI, it is a dark horse candidate among AIs. A late entrant, X is moving through the scaling generations very quickly thanks to clever approaches to getting rapid access to chips and power. Right now, Grok 2 is a very capable Gen2 model trapped within the Twitter/X interface1. It can pull in information from Twitter, and can output images through an open source image generator called Flux (without many guardrails, so, unlike other image generators, it is happy to make photorealistic fake images of real people). It has a somewhat strained “fun” system prompt option, but don’t let that distract from the fact that Grok 2 is a strong model, and in second place on the major AI leaderboard. (View Highlight)
Llama 3.1 405B. This is Meta’s Gen2 model, and while it is not yet multimodal, it is unique among Gen2 models because it is open weights. That means Meta has released it into the world, and anyone can download and use it, and, to some extent, modify and tweak it as well. Because of that, it is likely to evolve quickly as others figure out ways of extending its capabilities. (View Highlight)
When the o1-preview and o1-mini models from OpenAI were revealed last week, they took a fundamentally different approach to scaling. Likely a Gen2 model by training size (though OpenAI has not revealed anything specific), o1-preview achieves really amazing performance in narrow areas by using a new form of scaling that happens AFTER a model is trained. It turns out that inference compute - the amount of computer power spent “thinking” about a problem, also has a scaling law all its own. This “thinking” process is essentially the model performing multiple internal reasoning steps before producing an output, which can lead to more accurate responses (The AI doesn’t think in any real sense, but it is easier to explain if we anthropomorphize a little). (View Highlight)
Unlike your computer, which can process in the background, LLMs can only “think” when they are producing words and tokens. We have long known that one of the most effective ways to improve the accuracy of a model is through having it follow a chain of thought (prompting it, for example: first, look up the data, then consider your options, then pick the best choice, finally write up the results) because it forces the AI to “think” in steps. What OpenAI did was get the o1 models to go through just this sort of “thinking” process, producing hidden thinking tokens before giving a final answer. In doing so they revealed another scaling law - the longer a model “thinks,” the better its answer is. Just like the scaling law for training, this seems to have no limit, but also like the scaling law for training, it is exponential, so to continue to improve outputs, you need to let the AI “think” for ever longer periods of time. It makes the fictional computer in The Hitchhikers Guide to the Galaxy, which needed 7.5 million years to figure out the ultimate answer to the ultimate question, feel more prophetic than a science fiction joke. We are in the early days of the “thinking” scaling law, but it shows a lot of promise for the future. (View Highlight)
The existence of two scaling laws - one for training and another for “thinking” - suggests that AI capabilities are poised for dramatic improvements in the coming years. Even if we hit a ceiling on training larger models (which seems unlikely for at least the next couple of generations), AI can still tackle increasingly complex problems by allocating more computing power to “thinking.” This dual-pronged approach to scaling virtually guarantees that the race for more powerful AI will continue unabated, with far-reaching implications for society, the economy, and the environment. (View Highlight)
{kind=link}