Document Note: Sentence transformers have revolutionized natural language processing (NLP) by replacing recurrent neural nets (RNNs) with transformer models such as BERT and GPT. These sentence embeddings can be used to quickly compare sentence similarity for various use cases. The sentence-BERT model was introduced in 2019 to produce accurate sentence vectors and the sentence-transformers library has been adapted and applied to a range of semantic similarity applications. Other newer models such as MPNet are outperforming SBERT and the sentence-transformers library allows for easy switching between models. In future articles, more of these newer models and training of sentence transformers will be explored.
The dense embeddings created by transformer models are so much richer in information that we get massive performance benefits despite using the same final outward layers. (View Highlight)
Semantic search — information retrieval (IR) using semantic meaning. Given a set of sentences, we can search using a ‘query’ sentence and identify the most similar records. Enables search to be performed on concepts (rather than specific words). (View Highlight)
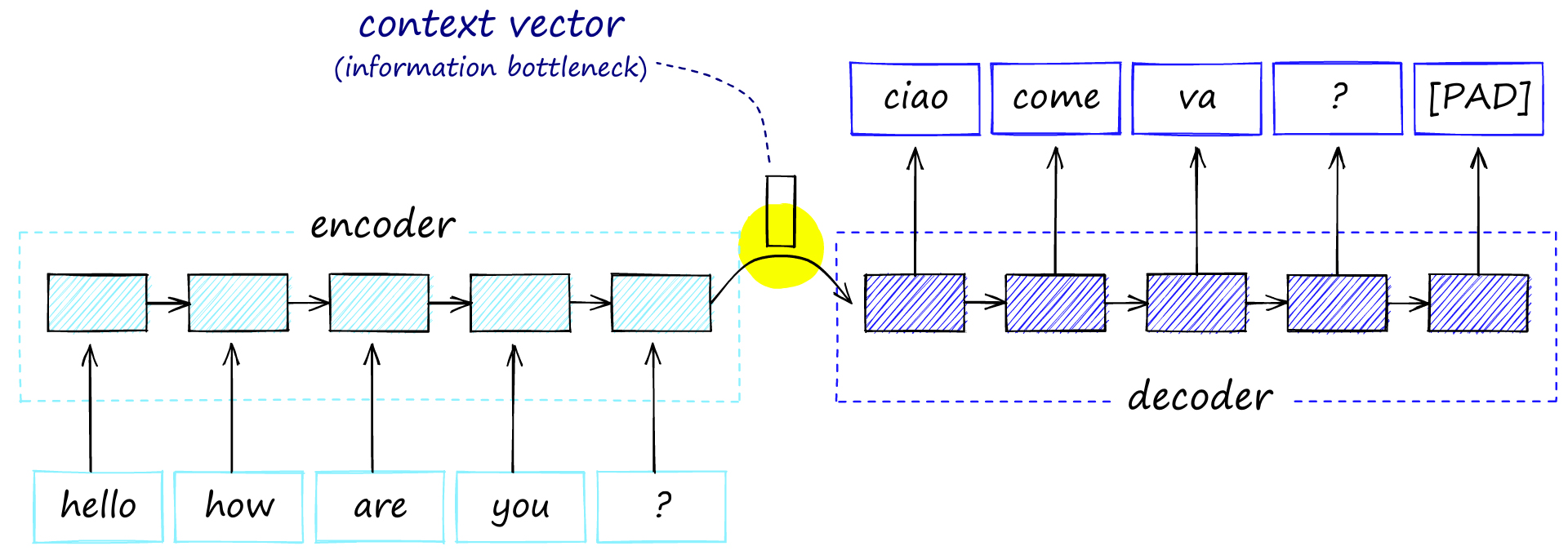
In machine translation, we would find encoder-decoder networks. The first model for encoding the original language to a context vector, and a second model for decoding this into the target language.
Encoder-decoder architecture with the single context vector shared between the two models, this acts as an information bottleneck as all information must be passed through this point.
The problem here is that we create an information bottleneck between the two models. We’re creating a massive amount of information over multiple time steps and trying to squeeze it all through a single connection. This limits the encoder-decoder performance because much of the information produced by the encoder is lost before reaching the decoder. (View Highlight)
ransformer models had one issue when building sentence vectors: Transformers work using word or token-level embeddings, not sentence-level embeddings.
Before sentence transformers, the approach to calculating accurate sentence similarity with BERT was to use a cross-encoder structure. This meant that we would pass two sentences to BERT, add a classification head to the top of BERT — and use this to output a similarity score. (View Highlight)
The cross-encoder network does produce very accurate similarity scores (better than SBERT), but it’s not scalable. I (View Highlight)
Ideally, we need to pre-compute sentence vectors that can be stored and then used whenever required. If these vector representations are good, all we need to do is calculate the cosine similarity between each.
With the original BERT (and other transformers), we can build a sentence embedding by averaging the values across all token embeddings output by BERT (if we input 512 tokens, we output 512 embeddings). Alternatively, we can use the output of the first [CLS] token (a BERT-specific token whose output embedding is used in classification tasks). (View Highlight)
The solution to this lack of an accurate model with reasonable latency was designed by Nils Reimers and Iryna Gurevych in 2019 with the introduction of sentence-BERT (SBERT) and the sentence-transformers library. (View Highlight)
Finding the most similar sentence pair from 10K sentences took 65 hours with BERT. With SBERT, embeddings are created in ~5 seconds and compared with cosine similarity in ~0.01 seconds. (View Highlight)
Although we returned good results from the SBERT model, many more sentence transformer models have since been built. Many of which we can find in the sentence-transformers library. (View Highlight)

 Encoder-decoder architecture with the single context vector shared between the two models, this acts as an information bottleneck as all information must be passed through this point.
The problem here is that we create an information bottleneck between the two models. We’re creating a massive amount of information over multiple time steps and trying to squeeze it all through a single connection. This limits the encoder-decoder performance because much of the information produced by the encoder is lost before reaching the decoder. (View Highlight)
Encoder-decoder architecture with the single context vector shared between the two models, this acts as an information bottleneck as all information must be passed through this point.
The problem here is that we create an information bottleneck between the two models. We’re creating a massive amount of information over multiple time steps and trying to squeeze it all through a single connection. This limits the encoder-decoder performance because much of the information produced by the encoder is lost before reaching the decoder. (View Highlight)