By combining these approaches, we are releasing the StackLlama model. The model is available on the 🤗 Hub and the entire training pipeline is available as part of the TRL library (View Highlight)
When doing RLHF, it is important to start with a capable model: the RLHF step is only a fine-tuning step to align the model with how we want to interact with it and how we expect it to respond (View Highlight)
Gathering human feedback is a complex and expensive endeavor. In order to bootstrap the process for this example while still building a useful model, we make use of the StackExchange dataset. The dataset includes questions and their corresponding answers from the StackExchange platform (including StackOverflow for code and many other topics). It is attractive for this use case because the answers come together with the number of upvotes and a label for the accepted answer (View Highlight)
For the reward model, we will always need two answers per question to compare, as we’ll see later. Some questions have dozens of answers, leading to many possible pairs. We sample at most ten answer pairs per question to limit the number of data points per question (View Highlight)
Reinforcement Learning from Human Feedback (RLHF) to be better aligned with how we expect them to behave and would like to use them. (View Highlight)
Loading the model in 8bit reduces the memory footprint drastically since you only need one byte per parameter for the weights (e.g. 7B LlaMa is 7GB in memory). Instead of training the original weights directly, LoRA adds small adapter layers on top of some specific layers (usually the attention layers); thus, the number of trainable parameters is drastically reduced. (View Highlight)
In this scenario, a rule of thumb is to allocate ~1.2-1.4GB per billion parameters (depending on the batch size and sequence length) to fit the entire fine-tuning setup. As detailed in the attached blog post above, this enables fine-tuning larger models (up to 50-60B scale models on a NVIDIA A100 80GB) at low cost (View Highlight)
Now we can fit very large models into a single GPU, but the training might still be very slow. The simplest strategy in this scenario is data parallelism: we replicate the same training setup into separate GPUs and pass different batches to each GPU. With this, you can parallelize the forward/backward passes of the model and scale with the number of GPUs. (View Highlight)
We use either the transformers.Trainer or accelerate, which both support data parallelism without any code changes, by simply passing arguments when calling the scripts with torchrun or accelerate launch. The following runs a training script with 8 GPUs on a single machine with accelerate and torchrun, respectively. (View Highlight)
Before we start training reward models and tuning our model with RL, it helps if the model is already good in the domain we are interested in. In (View Highlight)
There is nothing special about fine-tuning the model before doing RLHF - it’s just the causal language modeling objective from pretraining that we apply here (View Highlight)
With this approach the training is much more efficient as each token that is passed through the model is also trained in contrast to padding tokens which are usually masked from the loss (View Highlight)
We train the model for a few thousand steps with the causal language modeling objective and save the model. Since we will tune the model again with different objectives, we merge the adapter weights with the original model weights. (View Highlight)
In principle, we could fine-tune the model using RLHF directly with the human annotations. However, this would require us to send some samples to humans for rating after each optimization iteration. This is expensive and slow due to the number of training samples needed for convergence and the inherent latency of human reading and annotator speed. (View Highlight)
A trick that works well instead of direct feedback is training a reward model on human annotations collected before the RL loop. The goal of the reward model is to imitate how a human would rate a text. There are several possible strategies to build a reward model: the most straightforward way would be to predict the annotation (View Highlight)
. In practice, what works better is to predict the ranking of two examples, where the reward model is presented with two candidates (y_k, y_j) (yk,yj) for a given prompt x x and has to predict which one would be rated higher by a human annotator. (View Highlight)
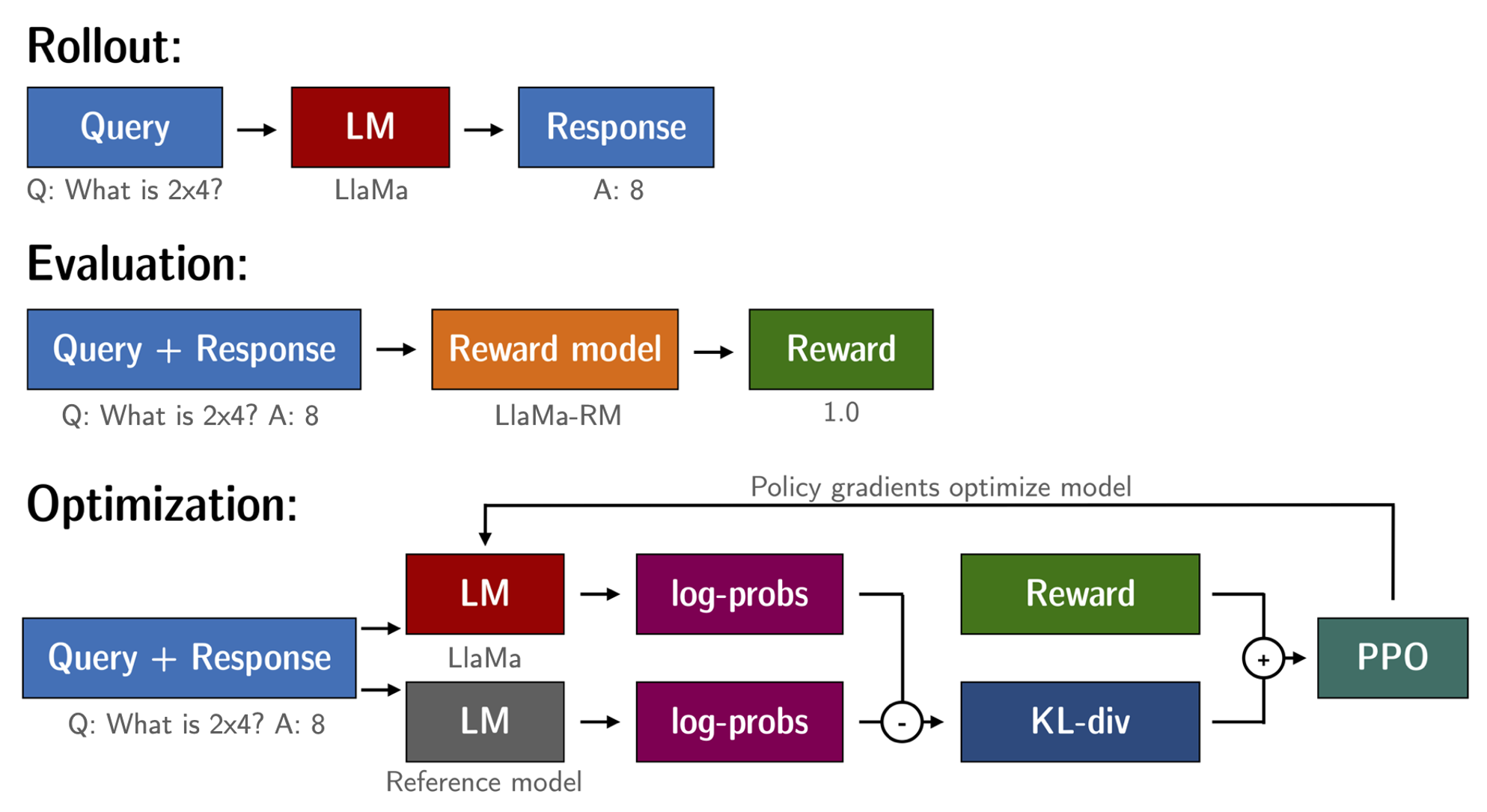
With the fine-tuned language model and the reward model at hand, we are now ready to run the RL loop. It (View Highlight)
Generate responses from prompts
Rate the responses with the reward model
Run a reinforcement learning policy-optimization step with the ratings
(View Highlight)
A common issue with training the language model with RL is that the model can learn to exploit the reward model by generating complete gibberish, which causes the reward model to assign high rewards. To balance this, we add a penalty to the reward: we keep a reference of the model that we don’t train and compare the new model’s generation to the reference one by computing the KL-divergence: (View Highlight)
Training LLMs with RL is not always plain sailing. The model we demo today is the result of many experiments, failed runs and hyper-parameter sweeps (View Highlight)
In general in RL, you want to achieve the highest reward. In RLHF we use a Reward Model, which is imperfect and given the chance, the PPO algorithm will exploit these imperfections. This can manifest itself as sudden increases in reward, however when we look at the text generations from the policy, they mostly contain repetitions of the string ```, as the reward model found the stack exchange answers containing blocks of code usually rank higher than ones without it. Fortunately we this issue was observed fairly rarely and in general the KL penalty should counteract such exploits (View Highlight)
In this post, we went through the entire training cycle for RLHF, starting with preparing a dataset with human annotations, adapting the language model to the domain, training a reward model, and finally training a model with RL (View Highlight)
For a real use case, this is just the first step! Once you have a trained model, you must evaluate it and compare it against other models to see how good it is. This can be done by ranking generations of different model versions, similar to how we built the reward dataset. (View Highlight)
Once you add the evaluation step, the fun begins: you can start iterating on your dataset and model training setup to see if there are ways to improve the model. You could add other datasets to the mix or apply better filters to the existing one (View Highlight)

 (View Highlight)
(View Highlight)