Document Note: The article argues that data engineering is still very immature compared to software engineering and that the rise of the modern data stack has exacerbated existing problems. It suggests that data teams are losing control and are creating expensive and confusing piles of garbage, driving costs and causing compliance and security issues. It states that data teams don’t understand the lifecycle of the data and have ignored long-standing best practices, which has led to an explosion of tables and dashboards that decay in value. It proposes aligning data teams with business goals, managing cost at the right level, and understanding the cost, usage, and lineage of data assets to address these issues.
data engineering is still very immature compared to software engineering and also why simply adopting tools and frameworks is, at best, a shallow way of establishing best practices in data engineering. (View Highlight)
The most prominent change in the data space over the last 5 years has been the adoption of software engineering practices (View Highlight)
, the rise of the modern data stack has exacerbated existing problems by putting very powerful (and expensive) tools in the hands of people without the full knowledge of how to harness them (View Highlight)
The tangible financial cost is significant as the number of tables and dashboards increases. Of course, not all of this is technical debt, but from what I’ve observed, most data teams using dbt feel like they’re losing control over their environments. (View Highlight)
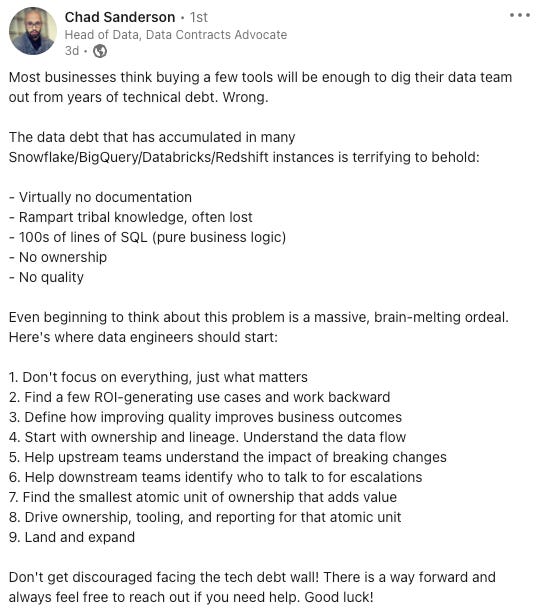
Chad makes a similar salient point here — no tool alone can help you manage your technical debt, and there are no quick fixes:
(View Highlight)
We have power tools: We have data warehouses that swallow inefficient queries without a hiccup — and tools to generate new tables in seconds (View Highlight)
We’re using power tools to efficiently produce piles of garbage. (View Highlight)
Remember those piles of garbage from the previous point? That’s data that no one needs or uses, and that’s driving no value. (View Highlight)
“quick request for data” can no longer be fulfilled. Data engineers like to make fun of the business user asking for data “real quick”. While these requests used to be handled ad hoc and found their way into a spreadsheet, now it’s so fast to create and execute a new dbt model (maybe even a dashboard?). Often, this new model is essentially a duplicate of another model, maybe with some filter or aggregation. (View Highlight)
now we have the power to expedite these “one-off” requests into version control, and they will stay there forever since no one knows if they are used or not. The “best practices” of version control and data as code are now working against us since the code is piling up and there is no good way of managing its lifecycle. (View Highlight)
We have tools that allow us to produce and consume data at an unprecedented rate, but very rarely do we talk about the lifecycle of the data itself. When ownership is not established, it’s hard to engage in maintaining what is being created. The “hard stuff” like maintenance, refactoring, and architectural reviews are not done. There is no culture of “less is more” (View Highlight)
most senior engineers see their best days as deleting and simplifying code, leaving the world slightly better than they found it that morning. This seems a far cry from how most data teams operate these days. (View Highlight)
the biggest elephant in the room is data modeling. Fact tables, dimension tables and slowly changing dimensions are becoming relics of the past in the rush for more and more data (View Highlight)
data (as everything) is about culture and people — not about just the tools. I do still think that tools play a vital role, but the path is a mix of technical and organizational considerations that must be taken seriously (View Highlight)
the frameworks we currently have are all about producing data. We are not yet talking cohesively about ownership and managing the lifecycle of data — which also includes deprecation and removal of data. (View Highlight)
get closer to the business and work to provide tangible value. Essentially, the data team needs to actively work to be seen as a valuable partner that helps other business departments hit their goals: close more business, reduce churn, increase current accounts, provide better support (View Highlight)
SQL itself can be parsed to automatically infer the DAG relationship and lineage between tables (like we do at Alvin). In this regard, I’m also happy to see some initiatives like SQLMesh. It is really exciting — and it gets away from those annoying refs, and allows for writing our data pipeline and dependencies in just plain ol’ SQL. (View Highlight)
Enforce linting and standards in SQL (no more SELECT *) to have uniform formatting and styles. (View Highlight)
The best product teams talk to their users to understand their needs, but they also use product analytics heavily to prioritize and de-prioritize features. (View Highlight)
have a strong conviction that for data engineering tasks, many of the problems are far more easily solved. By holistically understanding the cost, usage, and lineage of data assets it’s a lot easier to ask (and answer) the right questions. (View Highlight)

 (View Highlight)
(View Highlight) (View Highlight)
(View Highlight)