Instruction tuning improves the zero and few-shot generalization abilities of Large Language Models (LLMs). The NLP community has successfully leveraged this idea to build LLMs like InstructGPT, FLAN-T5, and FLAN-PaLM, which can act as general-purpose assistants. The user provides task instructions and guides the model to solve it through conversation. (View Highlight)
But we humans use more than just words. We use visuals to enrich our conversations, explain complex ideas, and understand the world. Recognizing this need, various language-augmented2 “foundation” vision models have emerged in the last two years. However, in these models, language was used primarily as a tool to describe the image content. The result was often a single large vision model with a fixed interface. It wasn’t great at adapting to user preferences or interactivity. (View Highlight)
Using “visual” instruction tuning, researchers have built a model that operates in the language-image multimodal space. It rivals GPT-4, excelling in chat capabilities and scientific question answering. What’s even more impressive is that the dataset used to train the model, weights, and code have been open-sourced. (View Highlight)
The authors of LLaVA thus resort to using the language-only GPT-4 to create instruction-following data. (View Highlight)
For an image Xv and its associated caption Xc, it is natural to create a set of questions Xq with the intent to instruct the assistant to describe the image content. We prompt GPT-4 to curate such a list of questions (see details in Appendix). Therefore, a simple way to expand an image-text pair to its instruction-following version is Human : Xq Xv Assistant : Xc. Though cheap to construct, this simple expanded version lacks diversity and in-depth reasoning in both the instructions and responses. (View Highlight)
To mitigate this issue, we leverage language-only GPT-4 or ChatGPT as the strong teacher (both accept only text as input), to create instruction-following data involving visual content. Specifically, in order to encode an image into its visual features to prompt a text-only GPT, we use two types of symbolic representations: (i) Captions typically describe the visual scene from various perspectives; (ii) Bounding boxes usually localize the objects in the scene, and each box encodes the object concept and its spatial location. (View Highlight)
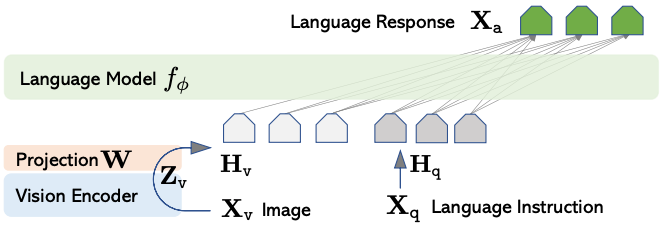
Let’s look at the model next. LLaVA has three components:
Visual Encoder: This converts the image into visual features. The encoder itself is a pre-trained CLIP ViT-L/14.
Language Model: A pre-trained Vicuna, known for its instruction-following capabilities, converts text into embeddings.
Projection: This is a simple linear layer that “projects” the visual features from the encoder into the word embedding space.
The LLaVA architecture - From [2] (View Highlight)
Although LLaVA is trained on a smaller instruction-following dataset, it performs surprisingly well compared to GPT-4. For example, these are the results on two images that are out-of-domain for LLaVa. It still understands the scenes well and follows the questions. BLIP-2 and OpenFlamingo focus on just describing the image. (View Highlight)

 The LLaVA architecture - From [2] (View Highlight)
The LLaVA architecture - From [2] (View Highlight)