Image Encoder: Converts the image into a numerical format.
Multimodal Projector: Aligns the image and text representations.
Text Decoder: Generates text based on the combined image-text input.
For example, the LLaVA model uses a CLIP image encoder, a multimodal projector, and a Vicuna text decoder. The model learns to align images and text by comparing its output to ground truth captions. (View Highlight)
With TRL’s SFTTrainer, you can customize a VLM for your specific needs. (View Highlight)
VLM Superpowers
VLMs can do a lot of nifty things:
• Image Captioning: Describe what’s happening in a picture.
• Visual Question Answering: Answer questions about images.
• Image Recognition: Identify objects or scenes in images based on instructions.
• Document Understanding: Make sense of text within images, like scanned documents.
• Spatial Understanding: Detect and segment objects in an image, even telling their positions. (View Highlight)
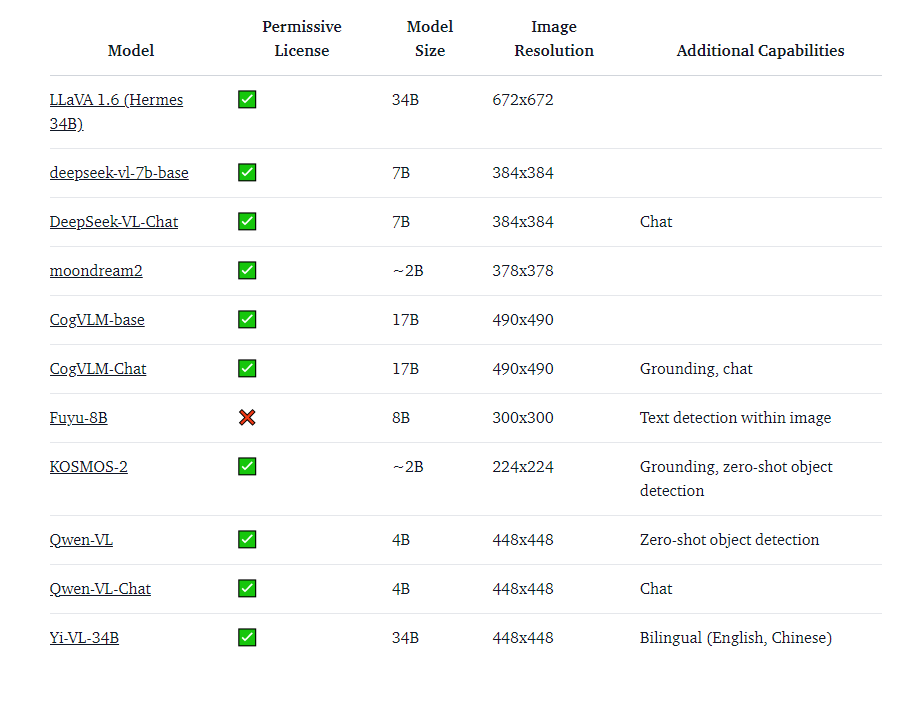
Choosing a VLM can feel like picking a new gadget. Here’s how to make it easier:
Vision Arena: Think of it as a friendly competition where users submit images and prompts, and then vote on the best model output. The leaderboard here is based purely on human preferences.
Open VLM Leaderboard: Models are ranked based on various metrics. You can filter models by size, license type, and performance on specific tasks.
VLMEvalKit: A toolkit to benchmark VLMs, powering the Open VLM Leaderboard.
These resources help you find the perfect model for your needs, whether it’s chatting about images or performing complex visual tasks. (View Highlight)