
Metadata
- Author: Gergely Orosz
- Full Title: ✍️ Ser Data-Driven No Es De Guapas
- URL: https://brain.drmario.tech/pages/%E2%9C%8D%EF%B8%8F+Ser+data-driven+no+es+de+guapas
Highlights
-
Data-drivenness is about building tools, abilities, and, most crucially, a culture that acts on data (p. 1) (Fun fact, Carl Anderson es, ni más ni menos, que el VP de Data de Weight Watchers, lo de la comida con “punticos” para perder peso). (View Highlight)
- El objetivo último de una compañía (privada) es maximizar beneficios, esto es construir un producto o dar un servicio por el que la gente quiera pagar más que lo que le cuesta crearlo. ¿Cómo se hace esto? Hay distintos frameworks / magufadas que intentan guiar semejante tortuoso camino. Quizá uno de los más sencillos para el caso que nos ocupa es el de The Lean Startup de Eric Ries, que nos introduce un feedback loop:
- At its heart, a startup is a catalyst that transforms ideas into products. As customers interact with those products, they generate feedback and data. The feedback is both qualitative (such as what they like and don’t like) and quantitative (such as how many people use it and find it valuable). (…) the products a startup builds are really experiments; the learning about how to build a sustainable business is the outcome of those experiments. For startups, that information is much more important than dollars, awards, or mentions in the press, because it can influence and reshape the next set of ideas. (View Highlight)
 que me recuerda mucho a esto de Andrejs Dunkels a través de 📖 Naked Statistics:
que me recuerda mucho a esto de Andrejs Dunkels a través de 📖 Naked Statistics:
Swedish mathematician and writer Andrejs Dunkels: It’s easy to lie with statistics, but it’s hard to tell the truth without them. (p. xv) (View Highlight)
- In a fascinating study, MIT Sloan Management Review collaborated with IBM Institute for Business Value to survey 3,000 managers and analysts across 30 industries about their use of and beliefs about the value of analytics. (LaValle, S., M. S. Hopkins, E. Lesser, R. Shockley, N. Kruschwitz, “Analytics: The New Path to Value.” MIT Sloan Management Review, October 24, 2010.).
Interestingly, compared to lower per‐ formers, top performers were: • Five times more likely to use analytics
• Three times more likely to be sophisticated analytics users
• Two times more likely to use analytics to guide day-to-day operations
• Two times more likely to use analytics to guide future strategies (…)
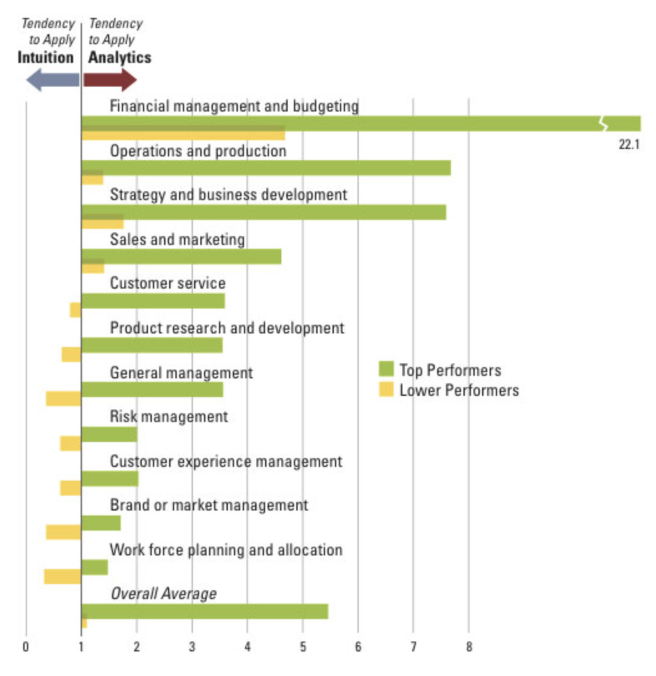 (View Highlight)
(View Highlight) - Por otro lado, “data-driven” es un término bastante denostado: deberíamos hablar de data-informed o data-inspired (Data-driven vs data-informed):
 (View Highlight)
(View Highlight) - Esta encuesta annual de la consultora NewVantage Partners suele aparecer en todos los sitios de sospechosos habituales: The Wall Street Journal, Harvard Business Review, MIT Sloan Management Review, Forbes: Data and Analytics Leadership Annual Executive Survey 2023. Según ellos mismos:
It has become the established industry benchmark for tracking the adoption of Big Data and AI within Fortune 1000 businesses. Ahí se ve que no solo es que la adopción no es buena, si no que vamos a peor en los últimos años:
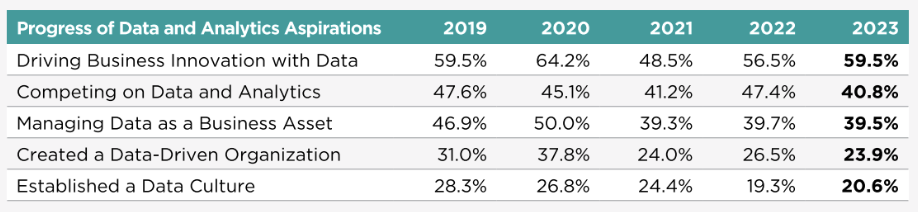 Yet it would appear that too much of the focus of data executives is on non-human issues — data modernization, data products, AI and ML, data quality, and various data architectures. Less than 2% of respondents ranked “data literacy” as their top investment priority. Could it be that we are leading the horse to water, but it isn’t drinking? (View Highlight) (View Highlight)
Yet it would appear that too much of the focus of data executives is on non-human issues — data modernization, data products, AI and ML, data quality, and various data architectures. Less than 2% of respondents ranked “data literacy” as their top investment priority. Could it be that we are leading the horse to water, but it isn’t drinking? (View Highlight) (View Highlight) -
The increase of disorder or entropy with time is one example of what is called an arrow of time, something that distinguishes the past from the future, giving a direction to time. (View Highlight) Lo más interesante de esta idea es que es una cuestión de probabilidad: The second law of thermodynamics results from the fact that there are always many more disordered states than there are ordered ones. For example, consider the pieces of a jigsaw in a box. There is one, and only one, arrangement in which the pieces make a complete picture. On the other hand, there are a very large number of arrangements in which the pieces are disordered and don’t make a picture. (View Highlight) Esto hay una manera literaria muy guay de contarlo que es: One of the most famous opening lines in literature comes from Anna Karenina by Leo Tolstoy. He writes, “Happy families are all alike; every unhappy family is unhappy in its own way (View Highlight) (View Highlight)
- The most fundamental problem in computer science is problem decomposition: how to take a complex problem and divide it up into pieces that can be solved independently. Problem decomposition is the central design task that programmers face every day. (View Highlight)
- original Data Mesh Principles and Logical Architecture quedaba más claro que se basa en introducir el tratamiento de los datos dentro de esta separación por bounded contexts que tuviéramos. Igual que ofrecemos APIs en cada dominio, para ser consumidos por otros dominios, ofrecemos datos para propósitos analíticos como si fueran una API (es decir, los tratamos como un producto de nuestro equipo, tenemos ownership sobre los mismos, definimos contratos, etc.).
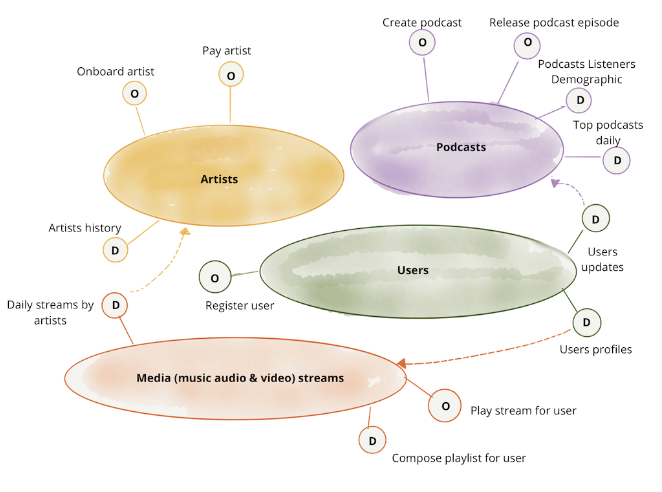 “O” represent operational endpoints (traditional APIs), while “D” represents that the data is also and endpoint. (View Highlight)
“O” represent operational endpoints (traditional APIs), while “D” represents that the data is also and endpoint. (View Highlight) - Chad Sanderson, otro de los grandes escritores blogueros en data (y ha estado en mil sitios haciendo data: Subway, Sephora, Microsoft…) cuenta lo que le pasaba en una startup llamada “Convoy”, del mundo de la logística. En Data is not a Microservice explica que:
For instance, at Convoy, a metric called shipment_margin was calculated as the revenue we made servicing a load minus the costs of servicing the load. Many teams had a separate view of which costs were germane to their particular revenue stream. These teams would add dimensions, stack CASE statements on top of their SQL queries like Jenga blocks, rename columns, and ultimately push data to new models where it was reused later, often with vastly different assumptions.
As a data consumer, this made life miserable. It was impossible to tell which data could be depended on, which was production-grade and which was experimental, how columns or tables with similar names differed from each other without exploring the underlying query and resulted in the analyst spending weeks contacting upstream developers to understand what the incoming data meant and how to use it in order to recreate the wheel all over again.
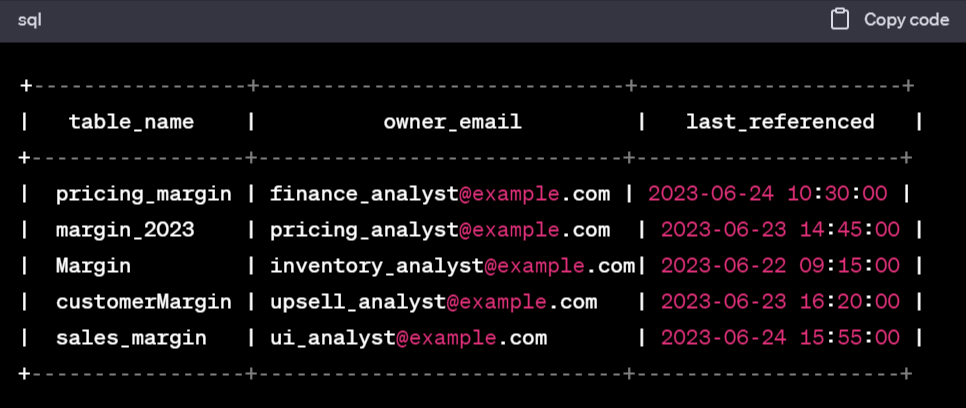 Which one of these should I use if I want margin? (View Highlight)
Which one of these should I use if I want margin? (View Highlight) - The purpose of data is decision-making. Its primary function is TRUTH. How that truth is used can be operational (like an ML model) or analytical (answering some interesting question). (View Highlight)
- en 🗞️ Good Data Citizenship Doesn’t Work, que es:
Data, it turns out, doesn’t so much drift towards entropy, but sprints at it. O sea, no solo el desorden es más grave (porque buscamos la verdad y la verdad es antitética al orden), no solo no tenemos un mecanismo de descomposición bueno del problema, si no que encima hay MÁS desorden, entre otras cosas porque hay más peña pidiendo. De 📖 Data Means Business: Business value from data will almost certainly not be limited to one team, one business problem or one area of your organisation. Data (and its value) is pervasive and prevalent in every customer interaction, every system key stroke, every employee connection (…) Nearly all people in your organization are your stakeholders. This is a unique challenge for data strategies. Possibly the only other area in the business like that is human resources. (p. 71) (View Highlight)
- También es casi infinito lo que puedes capturar, relativamente fácil de hacerlo y barato. Y muy tentador. Entonces, lo hacemos. Pero nos estamos haciendo un poco la puñeta en realidad: estamos haciendo el pajar más grande, pero buscamos la misma cantidad de agujas. De Nate Silver en 📖 La señal y el ruido:
si bien la cantidad de información disponible aumenta diariamente en 2,5 trillones de bytes, la cantidad de información útil no lo hace. La mayor parte de esa información es sólo ruido y el ruido aumenta mucho más rápido que la señal. Hay una cantidad creciente de hipótesis que analizar y de información que desbrozar, pero la cantidad de verdad objetiva se mantiene relativamente constante. (View Highlight)
- En el paper Common neural code for reward and information value, por ejemplo, a traves de imágenes de resonancia magnética de los sujetos, demuestra que recibir información produce la misma estimulación que las drogas, la comida, o recibir una recompensa monetaria (sea o no información útil para nosotros).
Y además resulta que nos creemos que con esto “hacemos algo”… Del paper Why do people worry:
subjects believe that worrying can prevent negative outcomes from happening, minimize the effects of negative events by decreasing guilt, avoiding disappointment, distraction from thinking about things that are even worse. (View Highlight) Imaginaos entonces las reacciones viscerales cuando intentas limitar la información a producir y consumir en la compañía. (View Highlight)
- Por supuesto, también tenemos problemas para interpretar correctamente las respuestas. Data es un false friend y no se libra nadie, ni Bill Gates, que escribía este tweet:
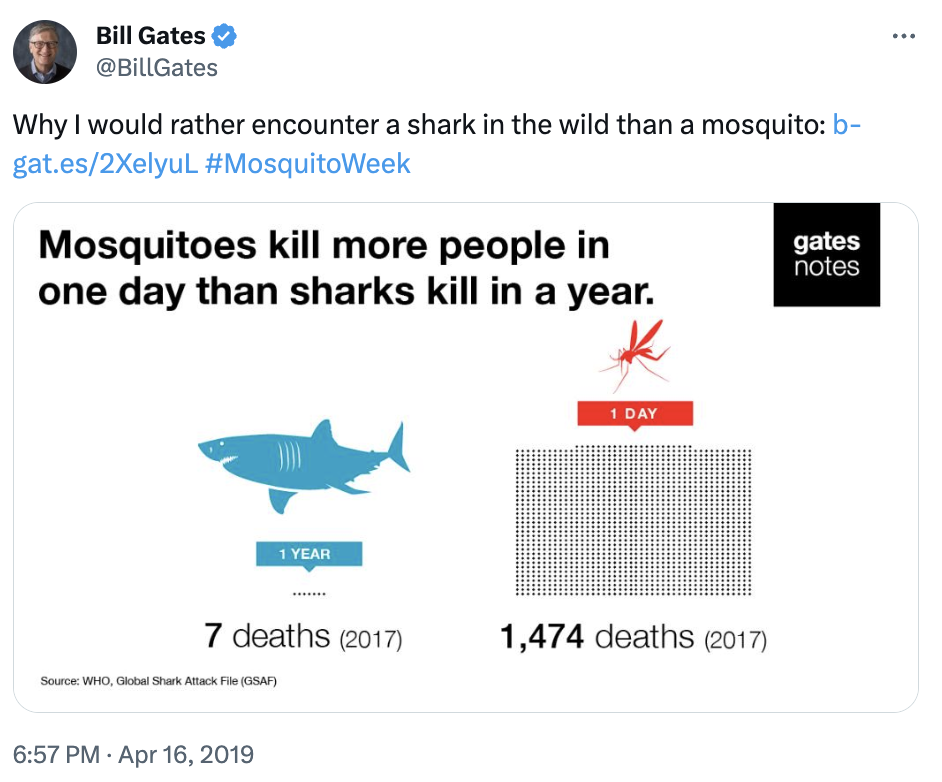 En la imagen hablamos de cómo de mortíferos son los tiburones y los mosquitos en general. Pero la preferencia que expresa Bill Gates tiene que ver con la probabilidad condicionada: dado que me encuentre con un tiburón, ¿cuál es la probabilidad de que me mate? (hint: alta) vs. dado que me encuentre con un mosquito, ¿cuál es la probabilidad de que me mate? (View Highlight)
En la imagen hablamos de cómo de mortíferos son los tiburones y los mosquitos en general. Pero la preferencia que expresa Bill Gates tiene que ver con la probabilidad condicionada: dado que me encuentre con un tiburón, ¿cuál es la probabilidad de que me mate? (hint: alta) vs. dado que me encuentre con un mosquito, ¿cuál es la probabilidad de que me mate? (View Highlight) - ..la gente suele pensar que confianza es lo mismo que competencia, y por esa razón un pronosticador que dice que algo tiene medianas probabilidades de ocurrir es menos respetado. Según un estudio realizado al respecto, la gente “interpreta predicciones de ese tipo como indicaciones de que los pronosticadores son incompetentes, que ignoran los hechos pertinentes o son perezosos, que no están dispuestos a hacer el esfuerzo necesario para reunir la información que justificaría una seguridad mayor en sus respuestas” (View Highlight)
- Por si todo esto fuera poco, ya no es que nos perdamos en una avalancha de información, y que encima esta sea difícil de interpretar pero queramos respuestas. Es que encima la peña va buscando la respuesta que les interesa. El famoso sesgo de confirmación. Esto lo cuenta en profundidad Jonathan Haidt en 📖 The Righteous Mind:
Peter Wason [1960] called this phenomenon the confirmation bias, the tendency to seek out and interpret new evidence in ways that confirm what you already think. People are quite good at challenging statements made by other people, but if it’s your belief, then it’s your possession—your child, almost—and you want to protect it, not challenge it and risk losing it. (chapter 4) (View Highlight)
- De 📖 Range: Según el inside view, acuñado por Kahneman y Tversky, cuanto más nivel de detalle se conoce de algo, más extremo se hace el juicio sobre ese algo. También curioso en este sentido es Dan Kahan, profesor de psicología en Yale, que afirma que los adultos versados en ciencia son más proclives al dogmatismo y a polarizarse en torno a temas políticos, porque encuentran con más facilidad argumentos que apoyan sus sentimientos (sesgos de confirmación). (View Highlight)
- Fijaos entonces que de nuevo hay que sobreponerse a algo muy intenso, muy emocional, atávico, para poder hacer un buen trabajo. De 📖 Noise. A Flaw in Human Judgement:
The only measure of cognitive style or personality that they found to predict forecasting performance was (…) developed by psychology professor Jonathan Baron to measure “actively open-minded thinking.” To be actively open-minded is to actively search for information that contradicts your preexisting hypotheses (…). They disagree with the proposition that (…) “intuition is the best guide in making decisions.” (p. 234) (View Highlight)
- our approach to earning that trust—Method 1[tracing the whole lineage of a metric, checking each step]—is fatally flawed. The road from raw data to reliable metric has a limitless variety of potholes; there can be no system, no matter how complete or comprehensive, that can tell us we’ve patched all of them. Contracts, observability tools, data tests—these are mallets for playing whack-a-mole against an infinite number of moles. (View Highlight)
- *Adanismo: Hábito de comenzar una actividad cualquiera como si nadie la hubiera ejercitado anteriormente. / “*Adamism” (from Adam): the habit of starting an activity as if nobody did it before. (View Highlight)
-
Companies aren’t snowflakes (…) 90% of the dashboards at a company could be standardized. Sin embargo, la inmensa mayoría de compañías se monta un pifostio de narices, se vuelven creativos inventándose métricas y su manera de calcularlas… El por qué ocurre esto lo exploro más en detalle en ✍️ Refusing to stand on the shoulders of giants. (View Highlight)
- Del Data Mesh que hemos visto antes, hay una idea fantástica: vuestros datos son también una API. Igual que entendimos en ingeniería de software que teníamos una separación rara de tareas con respecto al testing y con respecto a desplegar software, y parte del movimiento DevOps fue traerse el ownership de ello a los equipos, por la misma razón tiene sentido traerse ownership en la producción de datos: no necesariamente de todos, pero sí de aquellos que están siendo útiles. Especialmente porque arreglar (o prevenir rotura) en la fuente es infinitamente más sencillo que parchear en las dependencias que vienen después. Tenéis mucha palanca en hacer que toda esta bola de complejidad sea más sencilla. Y al margen de cómo hacerlo técnicamente, quizá podemos empezar con “awareness”, en colaboración con los roles de data: qué data assets de los que produce mi equipo son importantes, tienen dependencias y estaría bien que monitorizáramos en caso de cambios (o incluso deben estar en test unitarios por ejemplo, cuando lanzo eventos de analítica). (View Highlight)
-
Question whether the work you are asking for is worth the total cost (View Highlight) Sobre todo porque… de 📖 Building Analytics Teams: We are not undertaking data and analytics projects to indulge our intellectual curiosity; we are doing so to drive change and improvement (p. 258) (View Highlight)
- Por otro lado, antes explicaba que uno de los grandes problemas del desorden en data venía por tener mucha gente pidiendo. En realidad, no necesariamente es un problema si fijamos una capacidad máxima de trabajo (el tamaño del equipo de Data que queramos tener) y lo que hacemos es priorizar dónde enfocar los esfuerzos.
De hecho, hay una marco de management que aparece en el 📖 Extreme Programming Explained, pero no es de ahí, es bastante más antiguo, que es muy interesante, y que se llama la Theory of constraints (que aparece un libro mítico de management de los 80, The Goal).
The Theory of Constraints says that in any system there is one constraint at a time (occasionally two). To improve overall system throughput you have to first find the constraint; make sure it is working full speed; then find ways of either increasing the capacity of the constraint, offloading some of the work onto non-constraints, or eliminating the constraint entirely. (View Highlight)
- Es decir, que podríamos orientar los esfuerzos de los equipos de Data a buscar esas restricciones y moverlas (de manera directa o ayudando a otros equipos para ello). Muy relacionado con esto está el concepto de los Metric trees, como argumenta Ergest Xheblati en How Analytics Can Make a Massive Impact on the Bottom Line. >
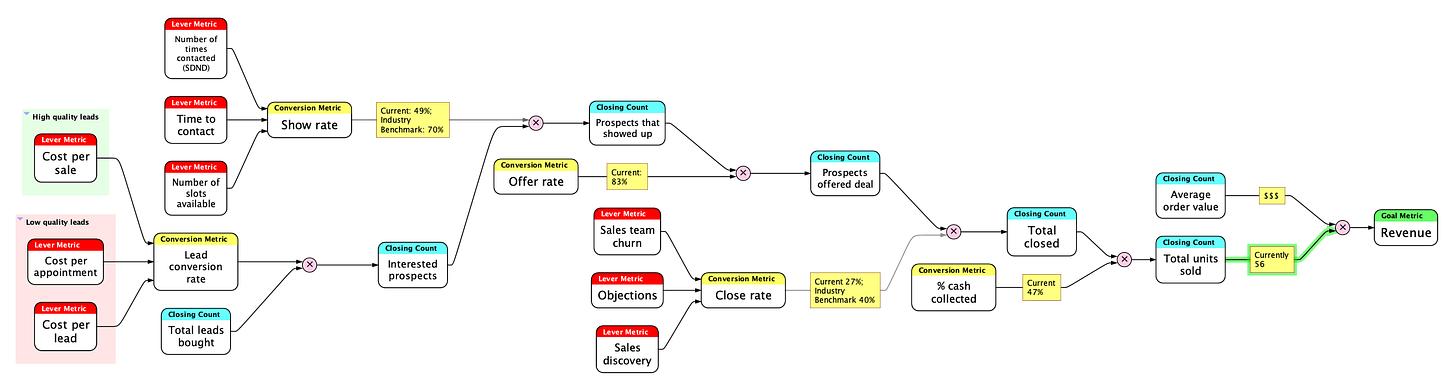 (View Highlight) (View Highlight)
(View Highlight) (View Highlight) -
The Theory of Constraints shares with other theories of organizational change the assumption that the whole organization is focused on overall throughput, not on micro-optimization. If everyone is trying to make sure his function is not seen as the constraint, no change will happen… Vamos… que les podemos pedir lo que queramos, pero lo que hay que hacer es pedir alineamiento a la compañía. (View Highlight)
 ¿Qué significa exactamente? Pues que tenga un buen Head of Data (como servidor), y le apoye con los mensajes en esta ardua tarea. En realidad, es algo tan simple, pero a la vez tan complicado, como estar alineado con las actitudes y medidas necesarias para enfrentarse a los problemas que contaba aquí entre otros:
• Cuestionar la recolección y/o el análisis de datos si no hay acciones previstas en función de lo que se vea con esos datos. Y sin pasarse: al mismo tiempo pedir que las decisiones vengan informadas con datos donde tenga sentido.
• Hacer challenge a los equipos con sus hipótesis.
• Alinearse con el ownership de los datos/métricas (es decir, no pedir simultáneamente que los equipos de ing. software cambien cosas muy rápido y al mismo tiempo exigir que no haya inconsistencias en los datos).
• Entender los retos, el peligro de trabajar con datos
• …
Por otro lado, también es importante descubrir en qué tipo de compañía estas: si en una donde realmente se confía en el impacto de los datos… o una en la que lo parece pero en realidad no interesa tanto, y en el mejor de los casos Data se ve como un centro de costes (en el peor, como algo incluso distractor de la misión de otros equipos). Un buen número de compañías se beneficiarían de una introspección sincera sobre su posición respecto a ser data-driven y simplemente tener una política de mínimo (View Highlight)
¿Qué significa exactamente? Pues que tenga un buen Head of Data (como servidor), y le apoye con los mensajes en esta ardua tarea. En realidad, es algo tan simple, pero a la vez tan complicado, como estar alineado con las actitudes y medidas necesarias para enfrentarse a los problemas que contaba aquí entre otros:
• Cuestionar la recolección y/o el análisis de datos si no hay acciones previstas en función de lo que se vea con esos datos. Y sin pasarse: al mismo tiempo pedir que las decisiones vengan informadas con datos donde tenga sentido.
• Hacer challenge a los equipos con sus hipótesis.
• Alinearse con el ownership de los datos/métricas (es decir, no pedir simultáneamente que los equipos de ing. software cambien cosas muy rápido y al mismo tiempo exigir que no haya inconsistencias en los datos).
• Entender los retos, el peligro de trabajar con datos
• …
Por otro lado, también es importante descubrir en qué tipo de compañía estas: si en una donde realmente se confía en el impacto de los datos… o una en la que lo parece pero en realidad no interesa tanto, y en el mejor de los casos Data se ve como un centro de costes (en el peor, como algo incluso distractor de la misión de otros equipos). Un buen número de compañías se beneficiarían de una introspección sincera sobre su posición respecto a ser data-driven y simplemente tener una política de mínimo (View Highlight)- Yo soy una persona algo neurótica y una de mis principales fuentes de sufrimiento es sufrir más por el hecho de creer que existe un escenario ideal al que no estoy llegando que por que una situación concreta en sí me haga sufrir. (View Highlight)
- Una de las cosas que me llevo yo de este ejercicio de introspección es, como dijeron las Twin Melody en el BenidormFest 2023, es que esto es lo que hay (aunque a veces duela, ay ay ay). He encontrado liberador entender que todo lo que os he contado es consustancial a la profesión. De 📖 Building Analytics Teams (él fija unos años donde cree que tener data literacy será común):
Generally, people do not enthusiastically embrace what they do not understand. You won’t find many, if any, of that generation of executives and managers who will freely admit that they do not fully understand basic computing technology (…) I am certain that there is an infinitesimally small percentage of that managerial population who understand basic descriptive statistics, let alone advanced analytics and AI (…) Given that this is a reality for the next 7 to 10 years, what do we do about it? Patience and clear communication are recommended for a start. Normally, I would have said concise communication, but in this case, a serious and significant amount of talking, writing, coercing, and convincing will be needed on your part. (p. 208) Por definición, trabajar en roles de Data va a ser algo que va a la contra. Va ser normal que haya una sensación de confrontación visceral, de alienamiento incluso en determinados momentos (porque tienes que decir mucho que no, porque literalmente tu curro si lo haces bien se basa en cuestionar instintos, porque aunque tienes que ayudar a tomar decisiones, a veces los datos no te van a dar decisiones claras). Es entender que somos una especie de contrapeso para el equilibrio de una compañía, el Yang del Ying… (View Highlight)
- Trabajar en Data tiene momentos de “nacida para ser segunda”. Dice Taylor A. Murphy (otro de los blogueros populares de Data, fue parte de uno de lo que al menos desde fuera parece uno de los mejores equipos de Data ever, el de Gitlab (y ex-líder de Meltano, una herramienta popular de extracción de datos, dentro de Gitlab):
The analytics function, and by extension a data team supporting it, is a 2nd order need of running an organization. A 1st order need is one that is critical to the functioning of the company. I would say most (>90%) companies can function without a data team and the analytics they would produce. They wouldn’t be as successful in this state, but it’s not strictly necessary. (View Highlight) (View Highlight)
- A mi esta idea también me ha hecho sufrir, especialmente viniendo de ser ingeniero de software, de ser “el que hace” (que ojo, en los equipos de data también se construye, lógicamente, e.g., activaciones de datos, no solo ayuda a la decisión). Enfrentarse a este pensamiento es complicado en varios niveles: está el ego de querer ser importante, está el sentir realizado (¿sirve para algo este trabajo entonces?¿Es un 📖 Bullshit Jobs?), o incluso sentirse amenazado (si no es importante… lo mismo no puedo vivir de esto). (View Highlight)
- Del ego hay mucho escrito, pero vamos, mal camino si mi ego depende del trabajo, en general. Pero lo de sentirse seguro, eso sí es importante: afortunadamente, hay que entender bien lo que significa esto que dice Taylor. Una cosa es que se pueda funcionar sin equipo de data, pero otra es que un equipo de data no aporte valor (igual que una gallina puede vivir sin cabeza un rato). A lo que a mi me ayuda mucho esto es que es a tener eyes on the prize y enfocarse en el impacto del curro. Y no creo que sea tan distinto en software, la verdad, de hecho puede ser más engañoso porque construimos cosas, pero eso no es sinónimo tampoco de aportar valor, aunque tengamos algo más tangible en las manos. (View Highlight)
- Por otro lado, tampoco tenemos que permitir colocarnos en una posición puramente transaccional (porque eso tampoco es hacer bien data) como cuenta Robert Yi en Why Analytics Sucks de cuando estaba en AirBnB como data scientist y uno de sus análisis dio pie al lanzamiento de una feature interesante… de la que ni siquiera le avisaron:
I’d never felt more viscerally that my role in the product-building process was that of data vending machine: request in, data out. It’s precisely this sort of transactional quality to our work that leads many of us to leave the industry (View Highlight) (View Highlight)
- A pesar de esta inmensidad de movidas que he contado aquí y un poco esta sensación de “estamos condenados” (porque luchar por cambiar la naturaleza humana, ojo cuidao con eso)… pues es que nunca falta un roto pa un descosío. Ya hemos visto antes que nuestra mente funciona en mysterious ways, primero tenemos una emoción y luego intentamos racionalizarla. Y me crucé con esto de Kiko Llaneras, periodista de datos, donde sentí como si hablaran por mi. Es del podcast “La Fucking Condicion Humana”. Cuenta cómo ya de crío paró con sus padres en un área de servicio y como se puso a recoger chapas de las botellas y sentía que tenía que coger TODAS las chapas distintas que hubiera y frustrarse “Hay demasiadas chapas”.
Impulso a ordenar como profesión (View Highlight)
- En formato texto:
Esa sensación que tienen muchas personas ante la inmensidad del mundo, mi frustración no era tanto por sentirme tan pequeño, que es el sentimiento más común, si no no poder dejar esto ordenado antes de irme. Esa pulsión la he tenido desde que recuerdo. Uno de los grandes golpes de suerte de mi vida es canalizar ese impulso por ordenar cosas hacia algo pagado y más o menos útil y más o menos elegante que es hacer lo mismo para algo que va leer otra gente, es decir, ordenar para los demás. (View Highlight)
 (
(