LLaVA-Plus maintains a skill repository that contains a wide range of vision and vision-language pre-trained models (tools), and is able to activate relevant tools, given users’ multimodal inputs, to compose their execution results on the fly to fulfill many real-world tasks.
New multimodal instruction-following tool use data. We present a new pipeline for curating vision-language instruction-following data, dedicated for tool use in human-AI interaction sessions, leveraging ChatGPT and GPT-4 as labeling tools
🌋 LLaVA-Plus Model. We have developed LLaVA-Plus, a general-purpose multimodal assistant that extends LLaVA by incorporating a large and diverse set of external tools that can be selected, composed, and activated on the fly for performing tasks
Performance. Our empirical study validates the effectiveness of LLaVA-Plus with consistently improved results on multiple benchmarks, and in particular, new SoTA on VisIT-Bench with a diverse set of real-life tasks.
Open-source. We will release the following assets to the public: the generated multimodal instruction data, the codebase, the LLaVA-Plus checkpoints, and a visual chat demo. (View Highlight)
LLaVA-Plus enables tool use with four steps.
① Humans provide a task instruction Xq related to an image Iq.
② The LMM-powered assistant analyzes both Xq and Iq, and outputs Xskill_use that chooses the tool from skill repository and writes the appropriate prompt as the tool argument.
③ By executing the tool, the result Xskill_result is returned to the assistant.
④ The assistant aggregates Xskill_result with Xq and Iq, and outputs Xanwser to humans. (View Highlight)
Only the green sub-sequences (or tokens) are used to compute the loss, and thus the model learns to predict skill use, answers, and when to stop. One example of the training data sequence is shown as below.
Training Data Example (View Highlight)

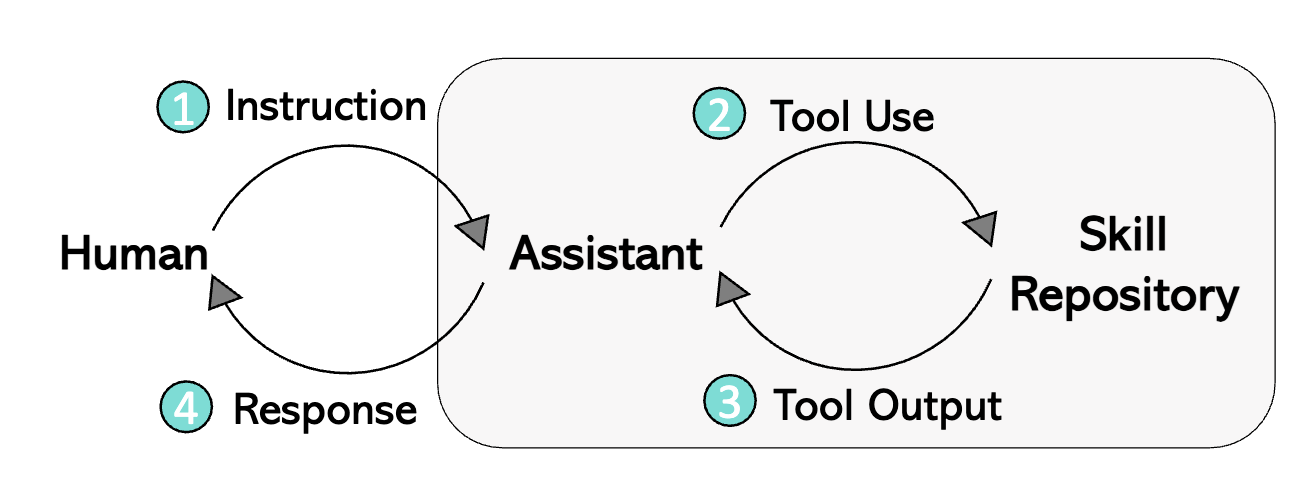 LLaVA-Plus enables tool use with four steps.
① Humans provide a task instruction Xq related to an image Iq.
② The LMM-powered assistant analyzes both Xq and Iq, and outputs Xskill_use that chooses the tool from skill repository and writes the appropriate prompt as the tool argument.
③ By executing the tool, the result Xskill_result is returned to the assistant.
④ The assistant aggregates Xskill_result with Xq and Iq, and outputs Xanwser to humans. (View Highlight)
LLaVA-Plus enables tool use with four steps.
① Humans provide a task instruction Xq related to an image Iq.
② The LMM-powered assistant analyzes both Xq and Iq, and outputs Xskill_use that chooses the tool from skill repository and writes the appropriate prompt as the tool argument.
③ By executing the tool, the result Xskill_result is returned to the assistant.
④ The assistant aggregates Xskill_result with Xq and Iq, and outputs Xanwser to humans. (View Highlight) Training Data Example
Training Data Example (View Highlight)
(View Highlight)