Generative Artificial Intelligence (AI), particularly Large Language Models (LLMs), offers new opportunities to connect listeners with audio through deeply personalized and contextually relevant experiences. By integrating vast world knowledge and adapting to diverse contexts, LLMs provide a unique opportunity to craft what we call personal narratives—stories that resonate with listeners and help familiarise them with recommendations on an individual level. This type of engagement supports one of Spotify’s key goals of connecting creators and listeners meaningfully. By leveraging the power of LLMs alongside our expertise in music, podcasts, and audiobooks, we aim to deliver tailor-made experiences that help listeners discover new artists, creators, and authors and provide deeper context to their recommendations. (View Highlight)
Focusing on contextualized recommendations is just one aspect of Spotify’s broader AI journey. As we continue to innovate with cutting-edge technologies, we are unearthing a set of diverse applications to redefine how users interact with audio. These include 1) search and recommendation systems for highly tailored content discovery, 2) advanced audio processing that powers features like the natural, engaging voices of our English and Spanish AI DJs, and 3) generative content, such as podcast chapterization, making podcasts easier to navigate. (View Highlight)
n this blog post, we explore two use cases that illustrate how Spotify uses LLMs to craft contextualized recommendations through personalized narratives: helping users discover new artists with concise, meaningful explanations and delivering engaging, real-time insights tailored to each listener via AI commentary. Along the way, we share insights into how we adapt open-source LLM models to meet our unique needs, ensuring these innovations are scalable, safe, and impactful. (View Highlight)
Over the past decade, Spotify has leveraged various ML techniques, including graph neural networks, reinforcement learning, and more, to transform how users engage with our extensive catalog. As we deepen our efforts in LLM development, it is essential to adopt a principled approach to their integration, ensuring they are aligned to deliver contextualized recommendations through personalized narratives that resonate with both audiences and creators. (View Highlight)
A robust backbone model is one building block to achieve this, as it provides the flexibility for quick experimentation and enables targeted development. We can optimize a general-purpose LLM to fit precise product requirements while driving scalable innovation in personalized storytelling by leveraging a general-purpose LLM as a backbone model. Desirable characteristics of a strong backbone model include:
• Broad World Knowledge: The backbone model should cover a wide range of general and domain-specific knowledge, making it well-suited to our diverse catalog of music, podcasts, and audiobooks. This knowledge base allows it to craft contextual recommendations without extensive retraining.
• Functional Versatility: A good backbone model should ideally excel at tasks like function calling and content understanding, such as topic extraction and safety classification. This versatility enables rapid iteration on features that deliver personalized and engaging user experiences.
• Community Support: Strong community support is important for simplifying fine-tuning, offering efficient large-scale training and inference tools, and driving continuous improvements. This helps keep us at the forefront of LLM advancements, while enhancing our ability to deliver personalized recommendations.
• AI Safety: Safety is critical for ensuring a positive user experience, particularly in the context of personalized narratives. A backbone model must include safeguards to responsibly handle sensitive content, prevent harmful outputs, and ensure compliance with regulatory standards. (View Highlight)
Meta’s family of Llama models emerged as a strong candidate to help us achieve important parts of this work, as it meets essential criteria for a reliable backbone model and is well-suited for domain adaptation. (View Highlight)
Traditionally, Spotify users rely on cover art and familiarity with an artist or genre when deciding whether to engage with music recommendations. We have been exploring ways to add more transparency and context to our recommendations to enhance user confidence and encourage deeper engagement.
LLMs have shown significant potential by offering meaningful, personalized context—almost like a friend’s recommendation would sound. This additional information increases the likelihood that users will explore new content. By leveraging domain adaptation, we have achieved promising results that support this approach. In the following sections, we delve into how this innovation transforms our platform, from AI-generated explanations for recommendations to personalized commentary from our AI DJ. (View Highlight)
LLMs bring a new dimension to Spotify’s personalization work by offering the ability to explain why a particular item might resonate with users. These explanations aim to help users understand the rationale behind recommendations and to provide deeper insight into the content. (View Highlight)
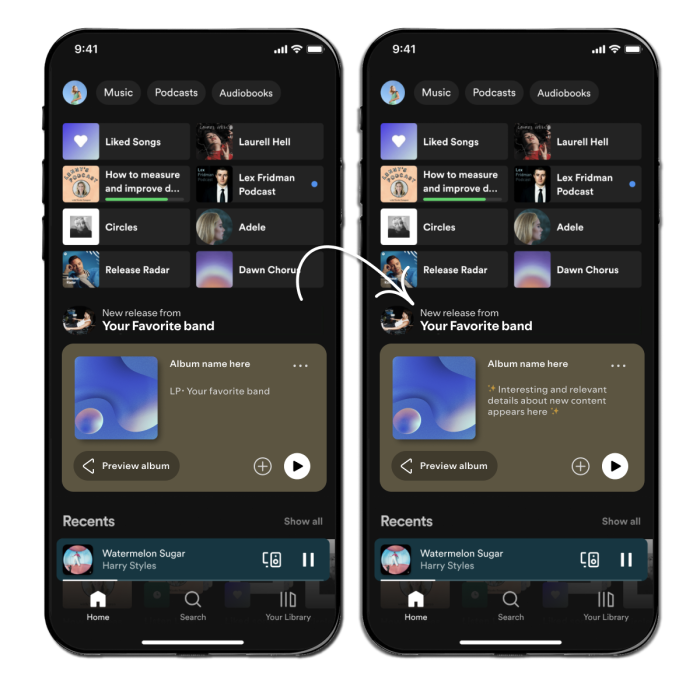
That is why we explored how LLMs can generate concise explanations that add valuable context to recommendations for music, podcasts, and audiobooks over the past months. Combining the broad knowledge of a backbone model with our expertise in audio content, we created explanations that deliver personalized insights into recommended content. These explanations aim to spark curiosity and enhance discovery. For example, “Dead Rabbitts’ latest single is a metalcore adrenaline rush!” or “Relive U2’s iconic 1993 Dublin concert with ZOO TV Live EP.” By adding this extra layer of context, recommendation explanations inform and inspire users to explore more of what Spotify has to offer. (View Highlight)
Using LLMs to bring the recommendation explanations product to life presents unique challenges, including ensuring a consistent generation style that aligns with our expectations, implementing robust safety measures to prevent inappropriate or harmful outputs, mitigating hallucinations to avoid inaccuracies, and effectively understanding user preferences to deliver tailored meaningful explanations. Our initial tests with zero-shot and few-shot prompting of open-source models such as Llama highlighted the need for careful LLM alignment, ensuring outputs are accurate, contextually relevant, and adhere to our standards. (View Highlight)
To achieve this, we adopted a human-in-the-loop approach. Expert editors provided “golden examples” of contextualization. They also provided ongoing feedback to address challenges in LLM output, including artist attribution errors, tone inconsistencies, and factual inaccuracies. In addition to continuous human feedback, we also incorporated targeted prompt engineering, instruction tuning, and scenario-based adversarial testing to generate the recommendation explanations. This iterative process improved the overall quality of our recommendation explanations and aligned them more closely with user preferences and creator expectations. (View Highlight)
Our online tests revealed that explanations containing meaningful details about the artist or music led to significantly higher user engagement. In some cases, users were up to four times more likely to click on recommendations accompanied by explanations, especially for more niche content. (View Highlight)
Another example of how contextual recommendations provide a deeper connection with creators is Spotify’s AJ DJ. Launched in 2023, DJ is a personalized AI guide that deeply understands listeners’ music tastes, providing tailored song selections and insightful commentary on the artists and tracks it recommends. LLMs provide a unique opportunity to scale these personalized narratives, ensuring every listener receives rich, context-driven commentary that deepens their connection to the music and creators. (View Highlight)
One key challenge for LLM-based AI DJ commentary is achieving a deep cultural understanding that aligns with each listener’s tastes. At Spotify, music editors play a central role in meeting this challenge, leveraging their genre expertise and cultural insight to craft experiences that truly embrace the richness of global music. By equipping these editors with generative AI tools, we can scale their expertise more effectively than ever, enabling us to refine the model’s output to ensure cultural relevance. (View Highlight)
We continuously research and refine models powering our generative AI tools to ensure they deliver high-quality DJ commentaries. Through extensive comparisons of external and open-source models, we found that fine-tuning smaller Llama models produces culturally-aware and engaging narratives on par with state-of-the-art, while significantly reducing costs and latency for this task. (View Highlight)
Our personalized narratives for AI DJ allow listeners to explore new music and the stories behind the songs, deepening their connection to the content. Similar to the contextual explanations example**, as we expanded the beta release across a select number of markets, we found by hearing the commentary alongside personal music recommendations, listeners are more willing to listen to a song they may otherwise skip.** This transformative approach redefines how users engage with music and sets the stage for further innovations in personalized storytelling across our platform. (View Highlight)
Building personalized narratives with the help of backbone models requires scalable infrastructure. To meet this need, we developed a comprehensive data curation and training ecosystem that enables the rapid scaling of LLMs. This setup facilitates seamless integration of the latest models while fostering collaboration across multiple teams at Spotify. These teams brought their expertise in building high-quality datasets, enhancing task performance, and ensuring the responsible use of AI. The curated datasets were used for extended pre-training, supervised instruction fine-tuning, reinforcement learning from human feedback, direct preference optimization, and thorough evaluation. (View Highlight)
LLMs like Llama are powerful, general-purpose models, potentially enabling a single model to power multiple use cases, such as contextualizing recommendations and providing personalized AI DJ commentary. To make LLMs more focused on Spotify needs, we adapted backbone LLMs on a carefully curated training dataset that included internal examples, data created by music experts, and synthetic data generated through extensive prompt engineering and using zero-shot inference of state-of-the-art LLMs. (View Highlight)
However, the use cases described in this document are not the only ones Spotify focuses on. We also identified a growing set of tasks within the Spotify domain where AI could significantly enhance performance. To explore this potential, we evaluated a wide range of LLMs from 1B to 8B -sized models, benchmarking their zero-shot performance against existing non-generative, task-specific solutions. Llama 3.1 8B demonstrated competitive performance. Building on this result, we implemented a multi-task adaptation of Llama, targeting 10 Spotify-specific tasks. This approach aimed to boost task performance while preserving the model’s general capabilities. Throughout this process, we used the Massive Multitask Language Understanding (MMLU) benchmark as a guardrail to ensure that the model’s overall abilities remained intact. (View Highlight)
Our results demonstrated that the tailored adaptation led to significant improvements (up to 14%) in Spotify-specific tasks compared to out-of-the-box Llama performance. Additionally, we successfully preserved Llama’s original capabilities, with only minimal differences in MMLU scores from the zero-shot baseline. This achievement underscores the potential for domain-adapting generative LLMs to boost specific performance while retaining the model’s robust foundational capabilities.
(View Highlight)
Distributed training is essential to meet the high computational demands of training LLMs with billions of parameters. A commonly overlooked aspect of this process is resilience to system failures or interruptions during lengthy, large-scale training phases on multi-node, multi-GPU clusters. To address this, we developed a high-throughput checkpointing pipeline that asynchronously saves model progress. By optimizing read/write throughput, we significantly reduced checkpointing time and maximized GPU utilization. (View Highlight)
Our LLM journey, however, extends far beyond fine-tuning. We are tackling challenges across the entire lifecycle, including efficient serving and inference for offline and online use cases. We leverage lightweight models and advanced optimization techniques such as prompt caching and quantization to achieve efficient deployment, minimizing latency while maximizing throughput without sacrificing accuracy. Open-source models further enhance our efforts by fostering a dynamic community of developers who contribute new tools, deployment libraries, and evaluation methods, including training accelerators and inference optimizations. (View Highlight)
Integrating vLLM, a popular inference and serving engine for LLMs, has been a game-changer, delivering significant serving efficiencies and reducing the need for custom techniques. vLLM enables low latency and high throughput during inference, allowing us to deliver real-time generative AI solutions to millions of users. This flexible engine has also facilitated seamless integration of cutting-edge models like Llama 3.1, including the 405B model, immediately upon release. This capability empowers us to benchmark the latest technologies and harness very large models for applications such as synthetic data generation. (View Highlight)
Spotify’s approach highlights the transformative potential of combining cutting-edge generative AI with deep domain expertise to deliver contextualized recommendations through personalized narratives. The tests and learnings shared in this blog showcase how LLMs can be adapted to push the boundaries of recommender systems, enabling real-time, highly personalized experiences like AI DJ commentary and recommendation explanations. These innovations enhance user engagement and redefine how creators and listeners connect through context-driven storytelling. (View Highlight)
mportantly, we are committed to advancing this technology beyond crafting new user experiences. By collaborating with industry leaders and open-source communities, we are driving progress in the broader AI ecosystem while addressing critical challenges like infrastructure optimization and scalability. From foundational research to practical advancements like checkpointing pipelines and multi-task fine-tuning, we are building solutions that deliver exceptional efficiency and effectiveness at scale. (View Highlight)

 (View Highlight)
(View Highlight)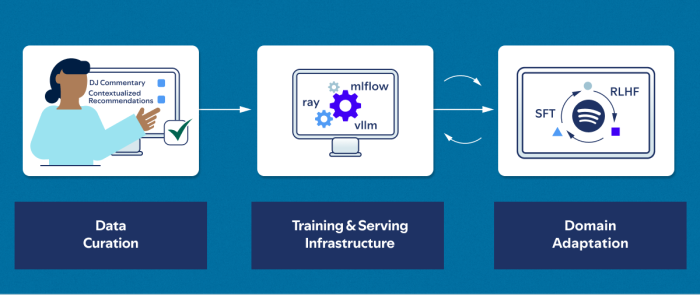 (View Highlight)
(View Highlight)