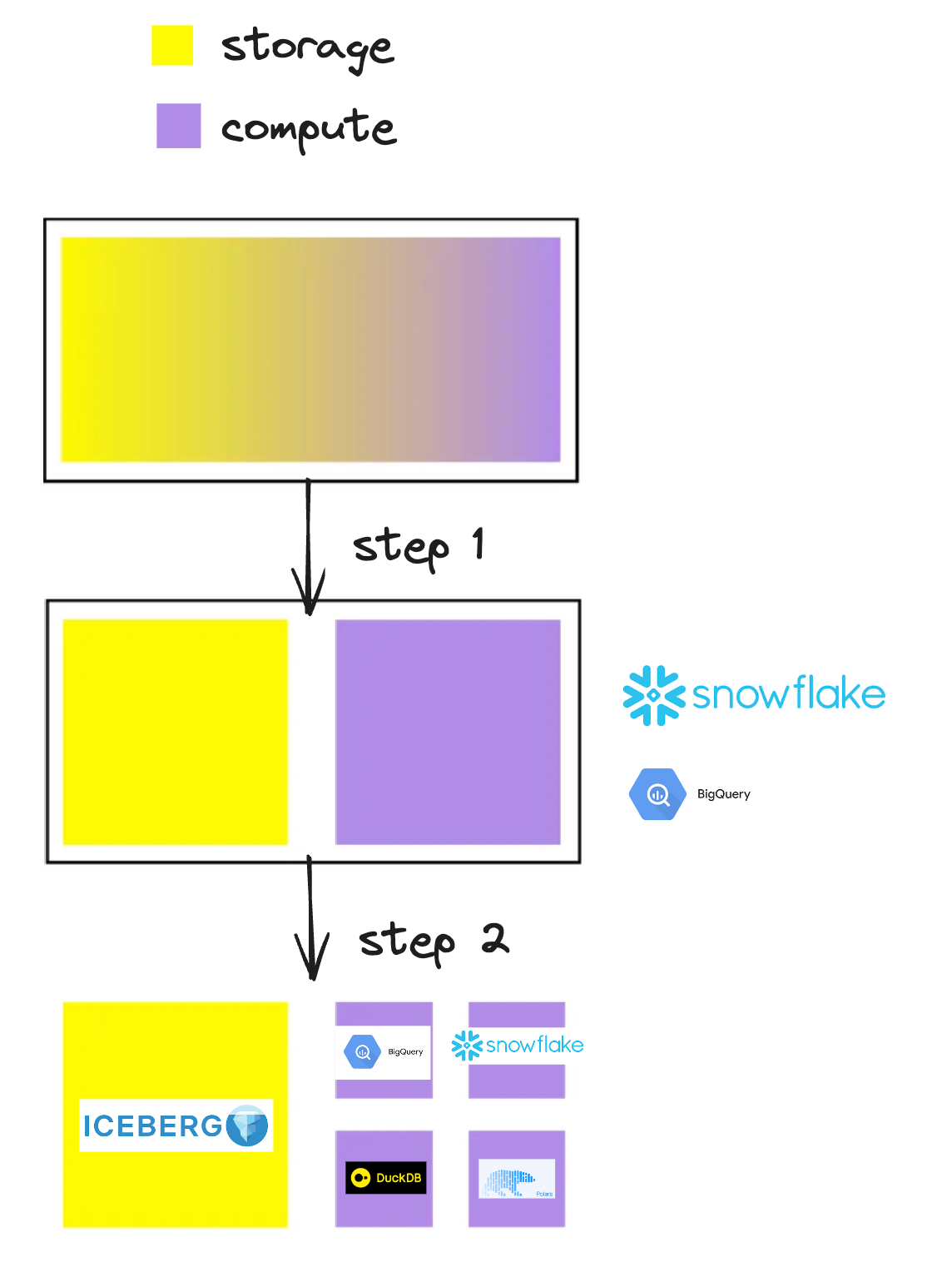
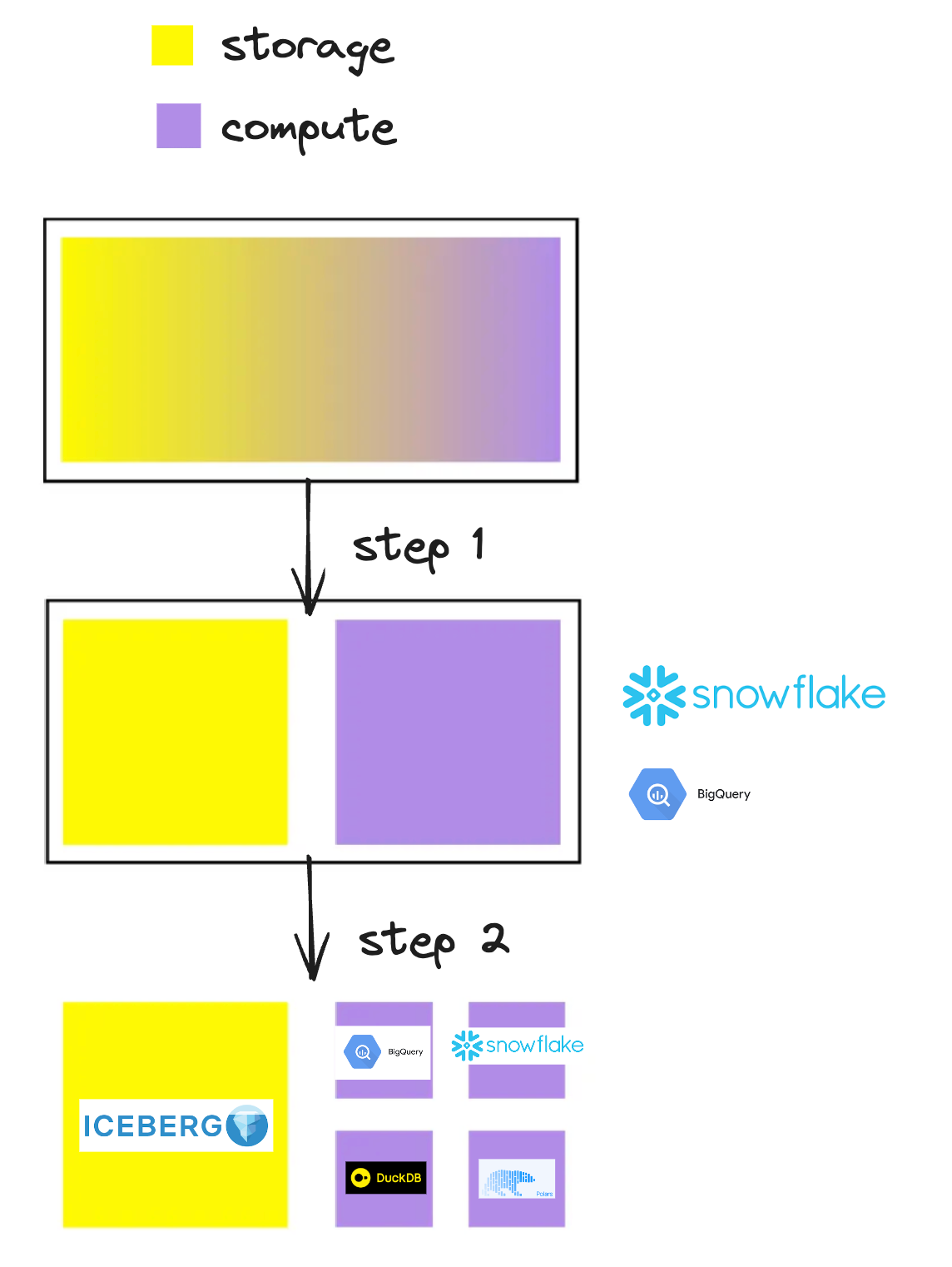
The compute category has evolved a lot these past years
We started with warehouses where compute and storage were tightly coupled.
Next, we transitioned to solutions with separate compute and storage within the same provider.
Now, we are adopting fully decoupled storage using Iceberg.
(View Highlight)
The most significant advantage of this transition is the ease of integrating single-node engines (like DuckDB, Polars, and others) with the rest of the stack.
Previously, taking parts of a pipeline outside the warehouse required a separate ETL to move data around.
Building and maintaining this ETL often killed the ROI of using cheaper compute.
With Iceberg as a bridge, we can now run workflows on different engines without copying data.
I’ve been considering how to integrate these engines into a pipeline over the past few weeks. (View Highlight)
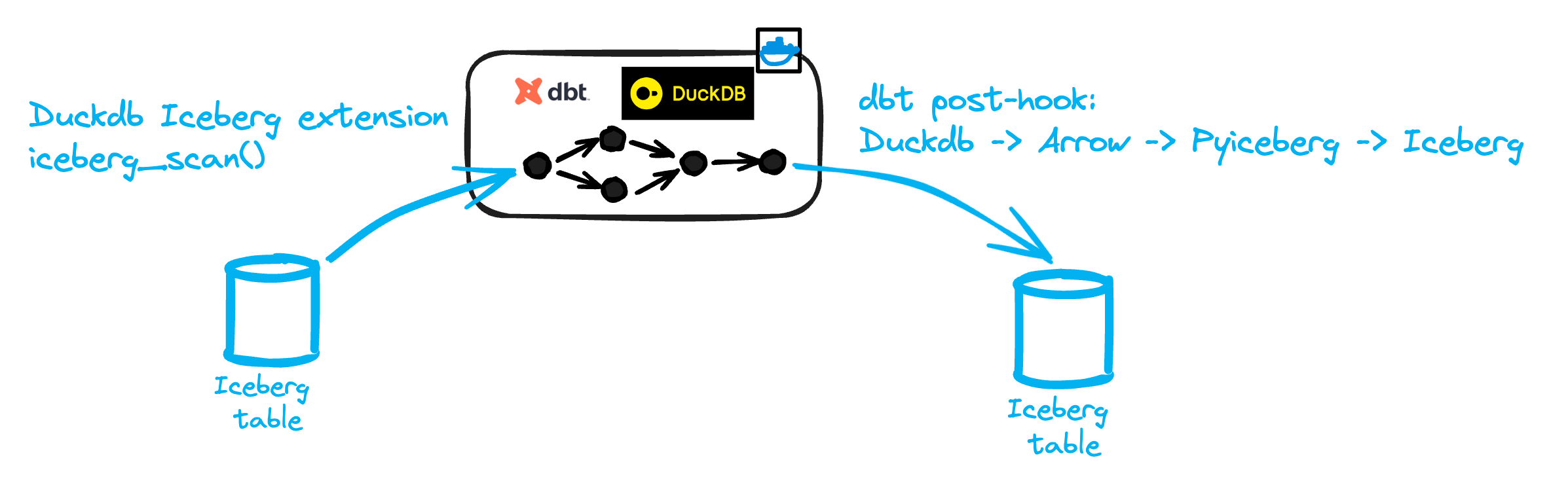
This is the most straightforward approach: run your entire dbt project in a single Docker container using DuckDB as the sole engine.
The workflow looks like this:
dbt sources are read via the DuckDB Iceberg extension
The dbt DAG is executed with DuckDB as the engine.
Target tables are materialized to Iceberg using PyIceberg.
Pros:
• Simplicity
• Efficient data passing across models
Cons:
• All models must fit in the instance’s memory
• No materialization of intermediate models (View Highlight)
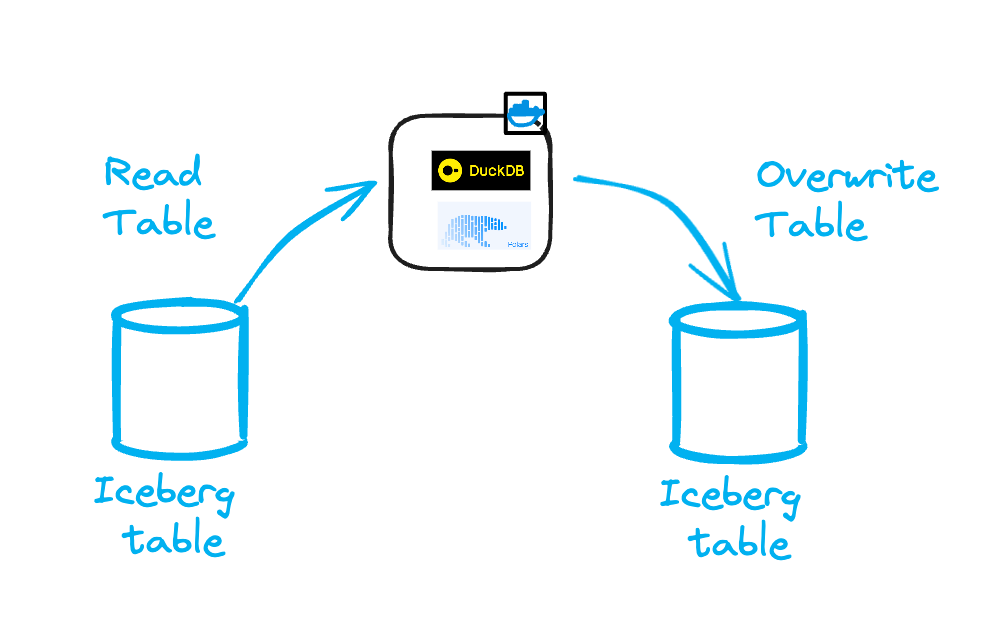
Option 2: one model = one worker
In this model, each transformation is handled by a separate worker.
This worker loads the source table into memory, performs the query, and writes the results to a destination Iceberg table.
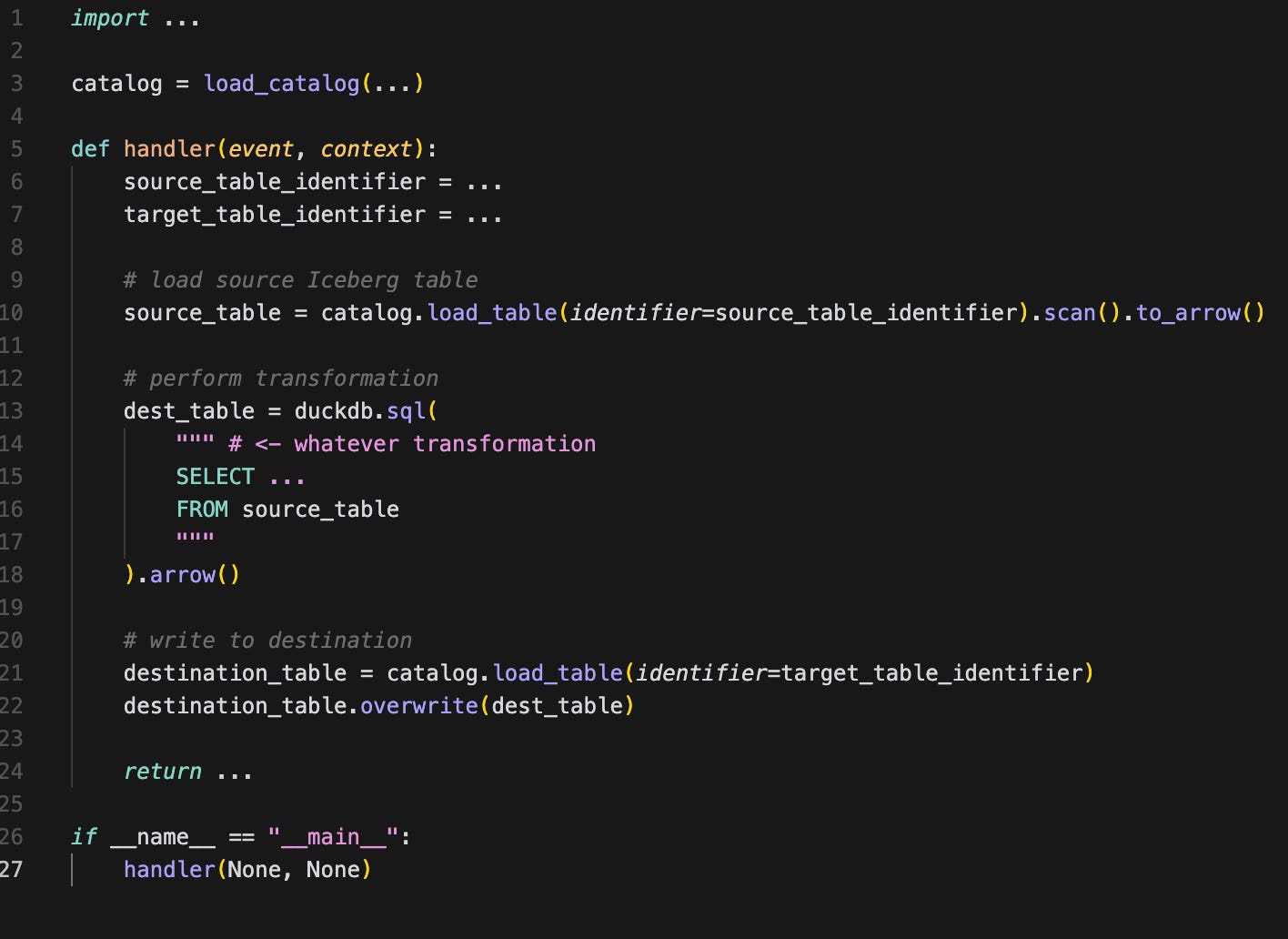
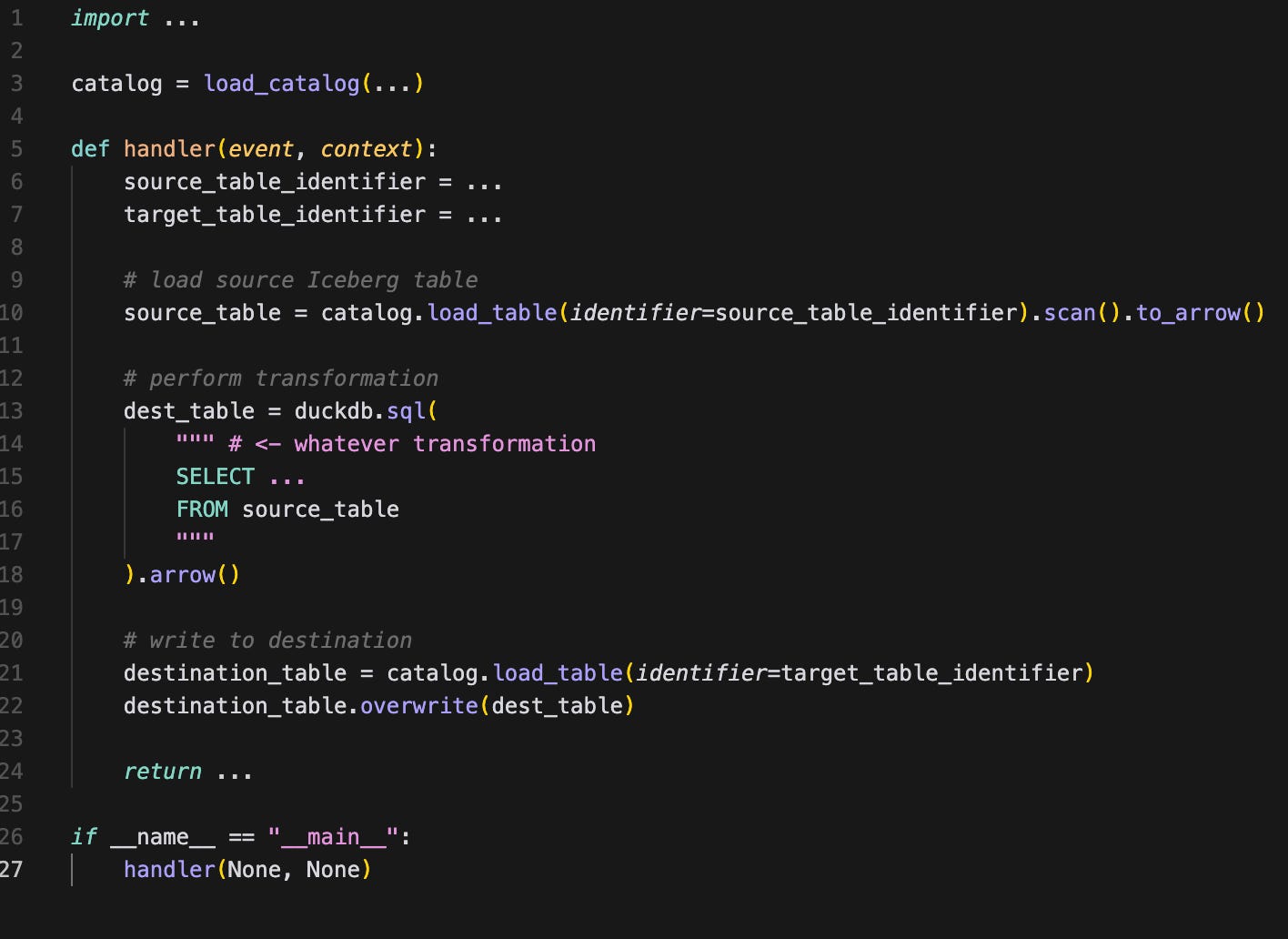
The code using DuckDB would look like this:
The code is oversimplified here; it should be made more generic to accept queries, as well as source and destination tables as inputs.
Instead of running a full materialization, we could switch to an incremental load.
However, PyIceberg isn’t yet optimized for MERGE INTO operations.
Currently, the only option is to use OVERWRITE with an overwrite_filter matching updated rows, but I’ve experienced performance degradation with this method.
Pros:
• All models are materialized to Iceberg.
• You can control the resources used by each model (instance size).
Cons:
• It only works as long as table fits in worker’s memory.
• Inefficient incremental models. (View Highlight)
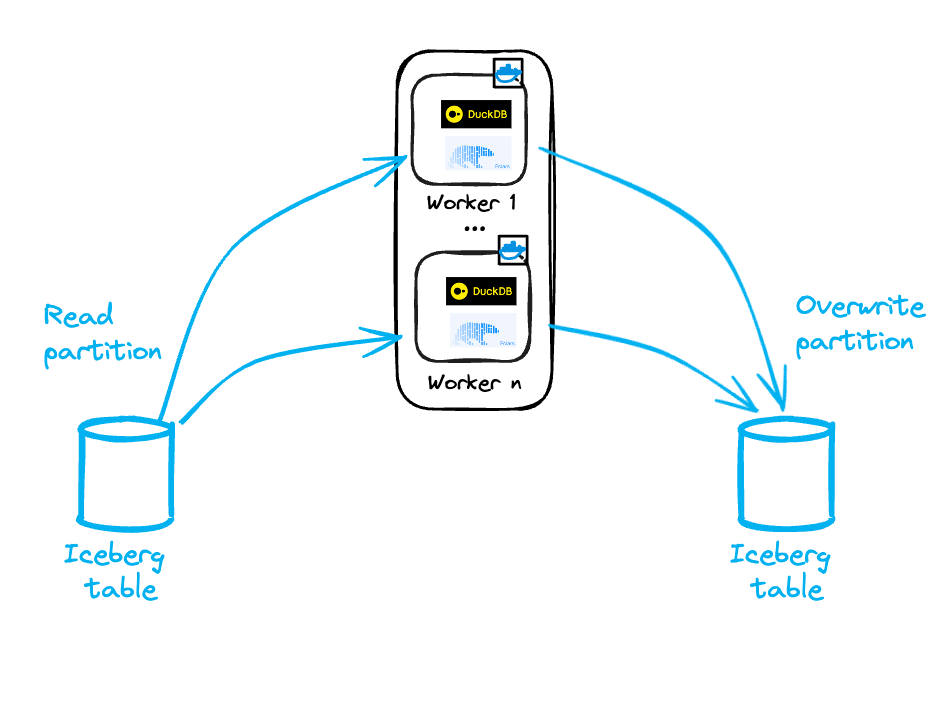
Option 3: one partition = one worker
One possible approach to counter the abovementioned limitations is to work at the partition level.
I discussed this approach in a previous article:
Debugging Data PipelinesJulien Hurault
·
Jun 21
Read full story
The idea is to divide a dataset into partitions that exist independently.
Each partition is immutable and consistently overwritten, avoiding the row-level limitations of PyIceberg discussed earlier.
Each worker is then sized to handle a single partition.
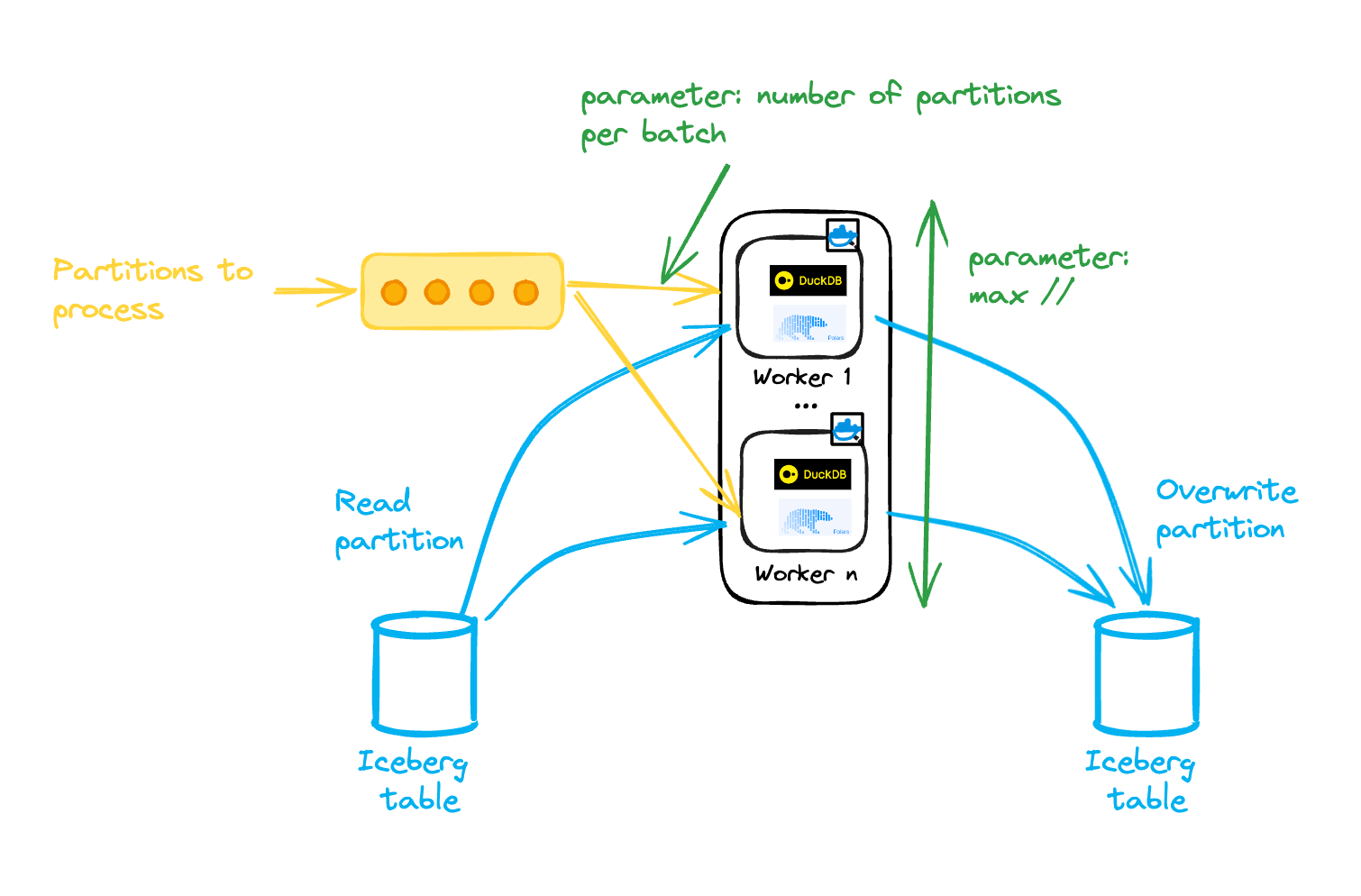
Add more workers to process additional partitions for large backfills or initial loads—there’s no need for a particular ‘large’ instance.
Limiting the number of concurrent workers can be beneficial in this setup, as too many can lead to excessive write conflicts and retries.
This can be achieved by adding a buffer/queue from which each worker pulls partitions to process.
To boost throughput, you can then allocate more memory to a worker and process multiple partitions in a single run (one Iceberg commit).
You might ask: what if I want to perform cross-partition aggregations?
In that case, if a single worker isn’t large enough, our favorite data warehouses are here to help :)
Pros:
• Can handle large tables.
• Offers better control over worker sizing as the tables grow.
• Capable of handling large backfills and continuous loads with the same setup.
Cons:
• Requires an orchestrator to track which partitions to process.
• Must control the number of concurrent writers. (View Highlight)
AWS Implementation
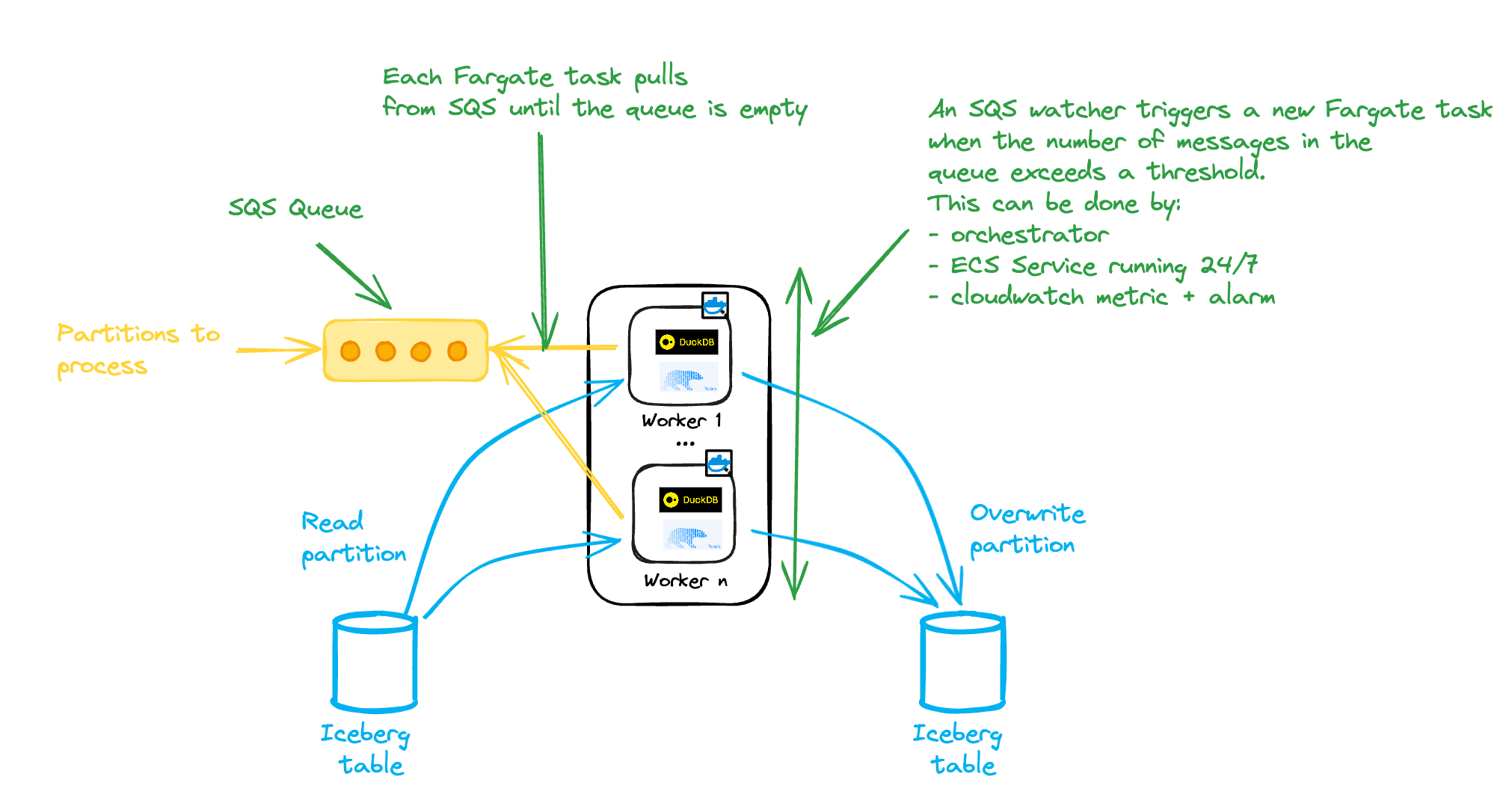
If your partition processing fits within the Lambda limitations of 10GB and 15 minutes, you can directly leverage the SQS + Lambda pattern.
But that’s probably not the case, and you’ll probably need to move to ECS Fargate.
ECS Fargate is an AWS service that allows you to run containers in a serverless manner.
You can get large runners (up to 120GB, 16vpcu) that run containers hosted in ECR.
This comes with some limitations:
• Tasks must run in a VPC (a distinct IP is assigned to each task, so ensure enough IPs are available).
• Has a longer cold start time than Lambda (~ 1 min).
• Does not support SQS triggers.
Since there is no direct SQS to Fargate trigger, we need to implement an additional SQS-watching service that will start new tasks based on the SQS queue depth:
(View Highlight)
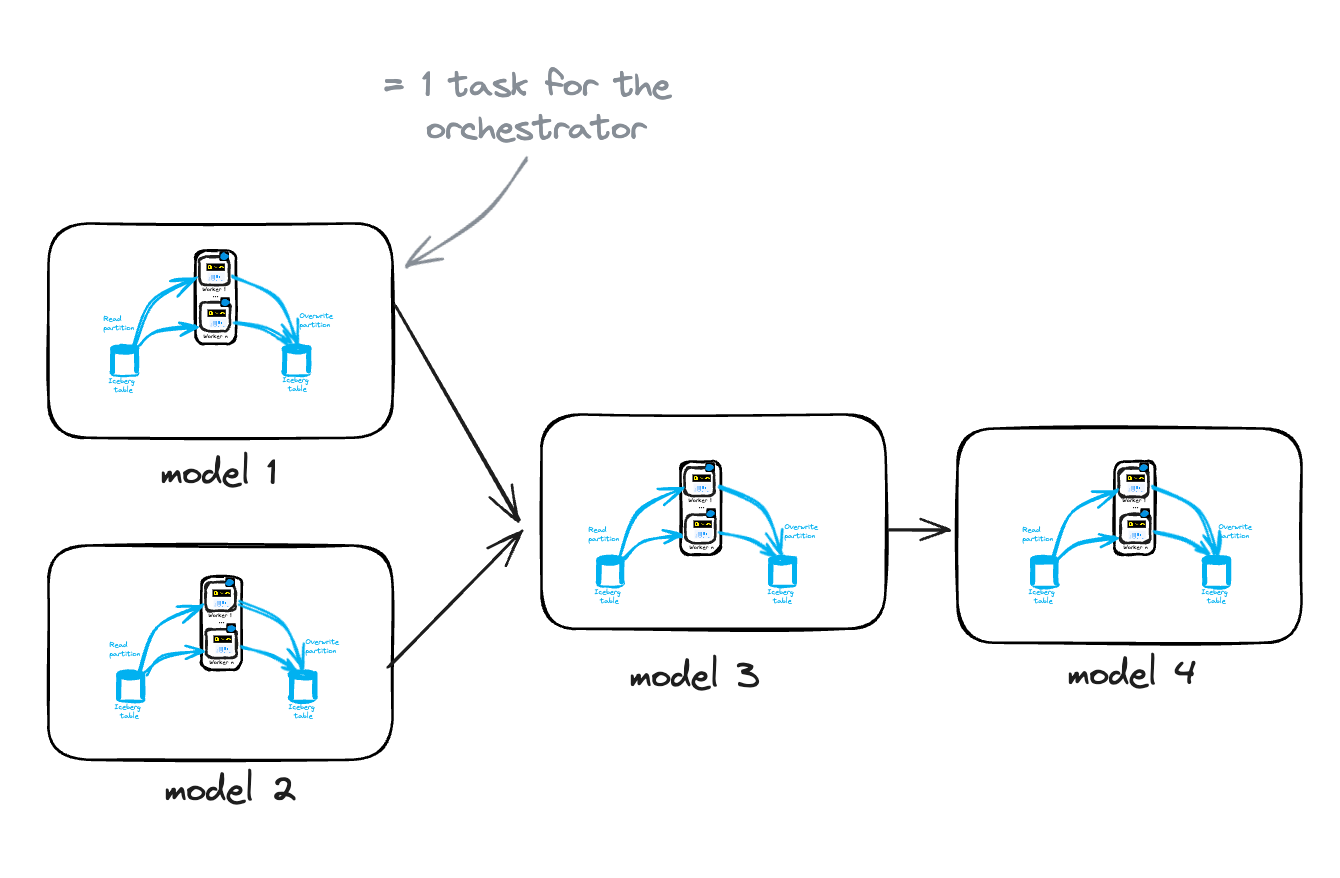
Orchestration
Ideally, we would like to use a tool like dbt to handle model lineage, but dbt does not currently support remote execution in an ECS task or Iceberg (for now).
Therefore, we must rely on an orchestrator to manage the various models.
This orchestrator needs to perform the following tasks for each model:
• 1: Get the partitions to update
• 2: Trigger the processing of each partition (ECS task) while controlling concurrency.
• 3: Wait for the processing of all the partitions
This can be done with various orchestrators:
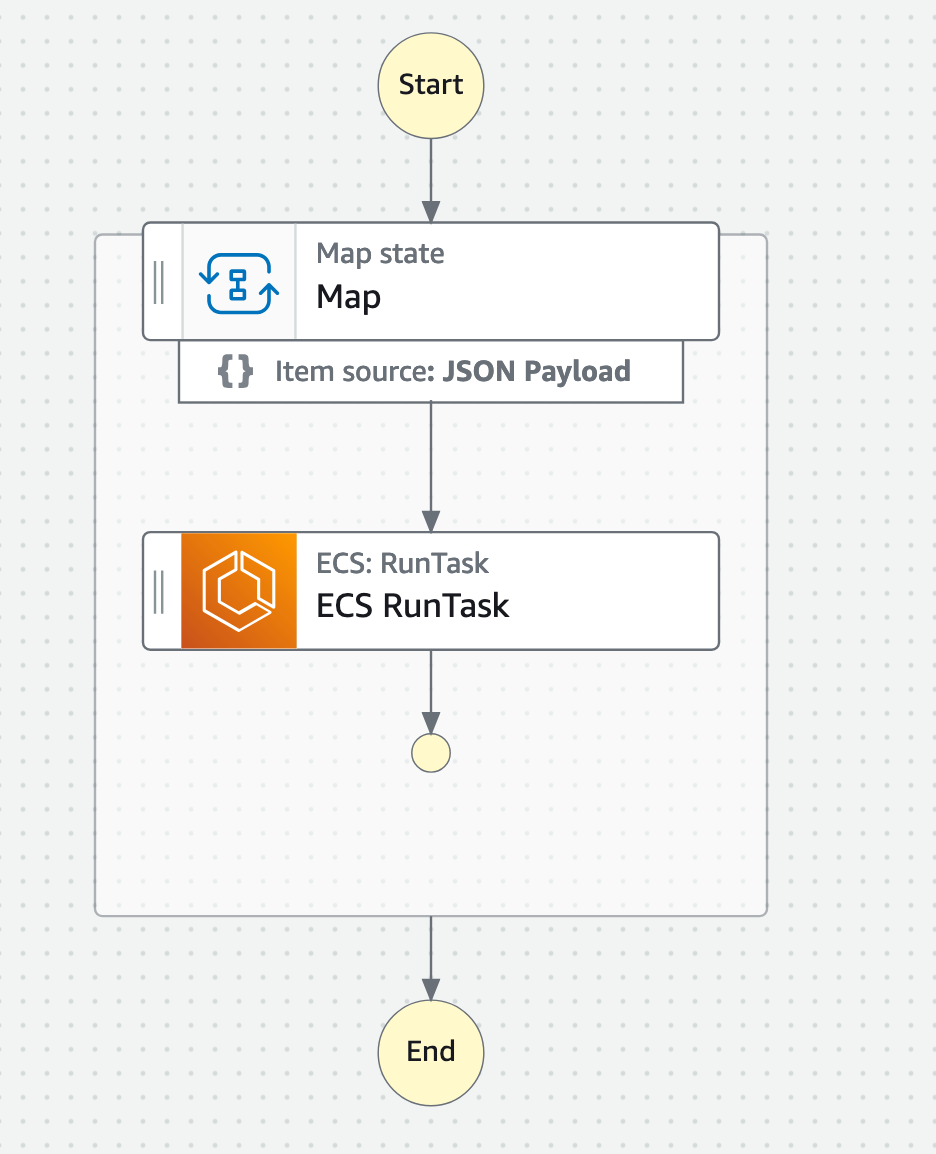
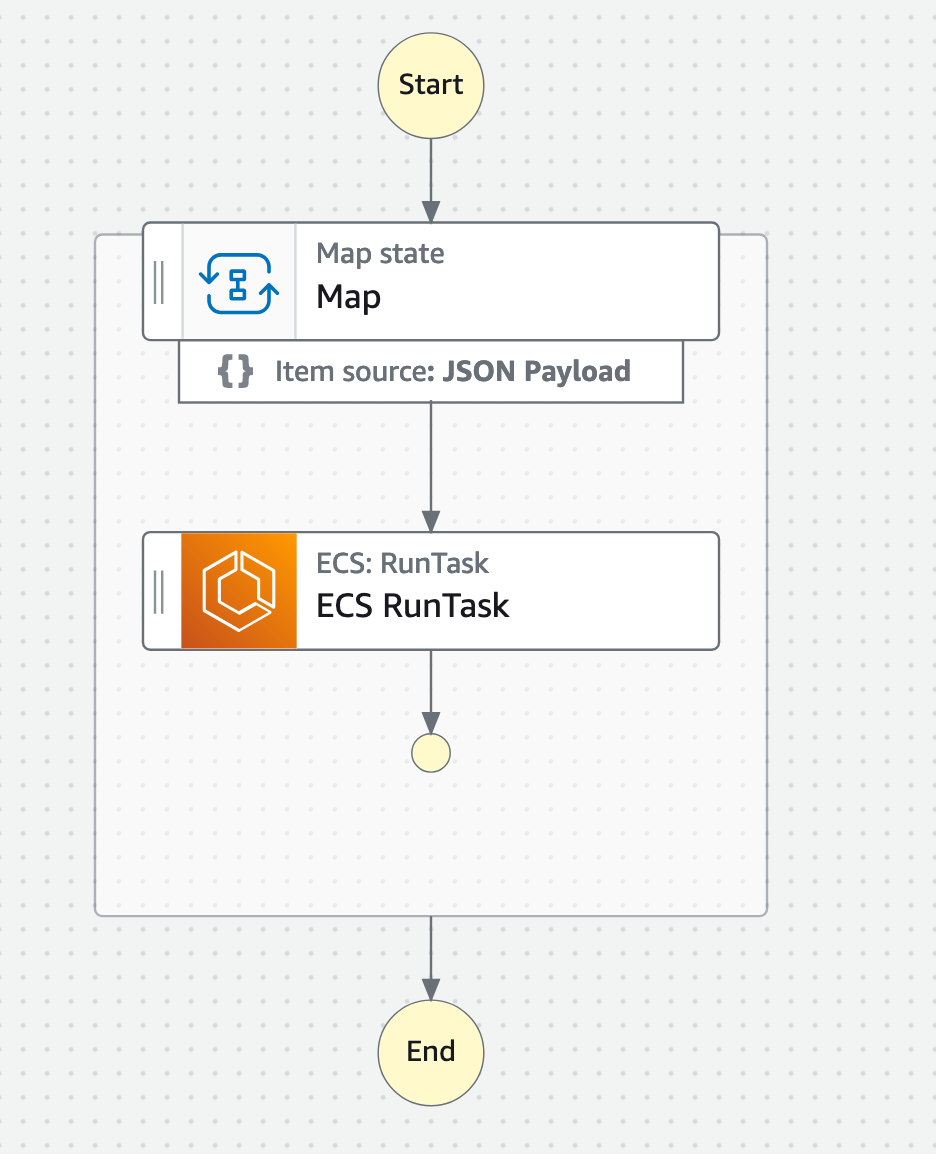
• Step function with Map + ECS RunTask state
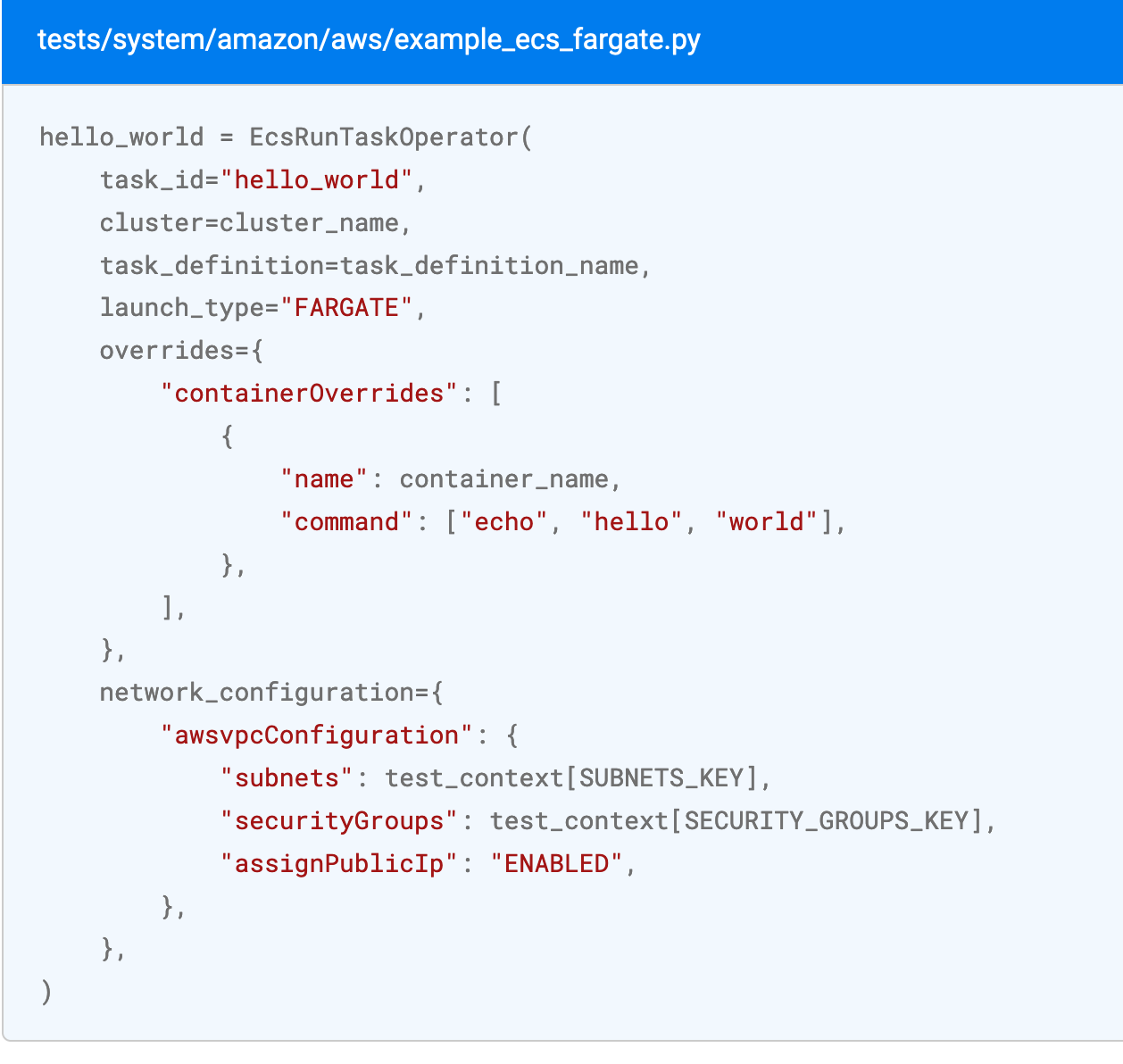
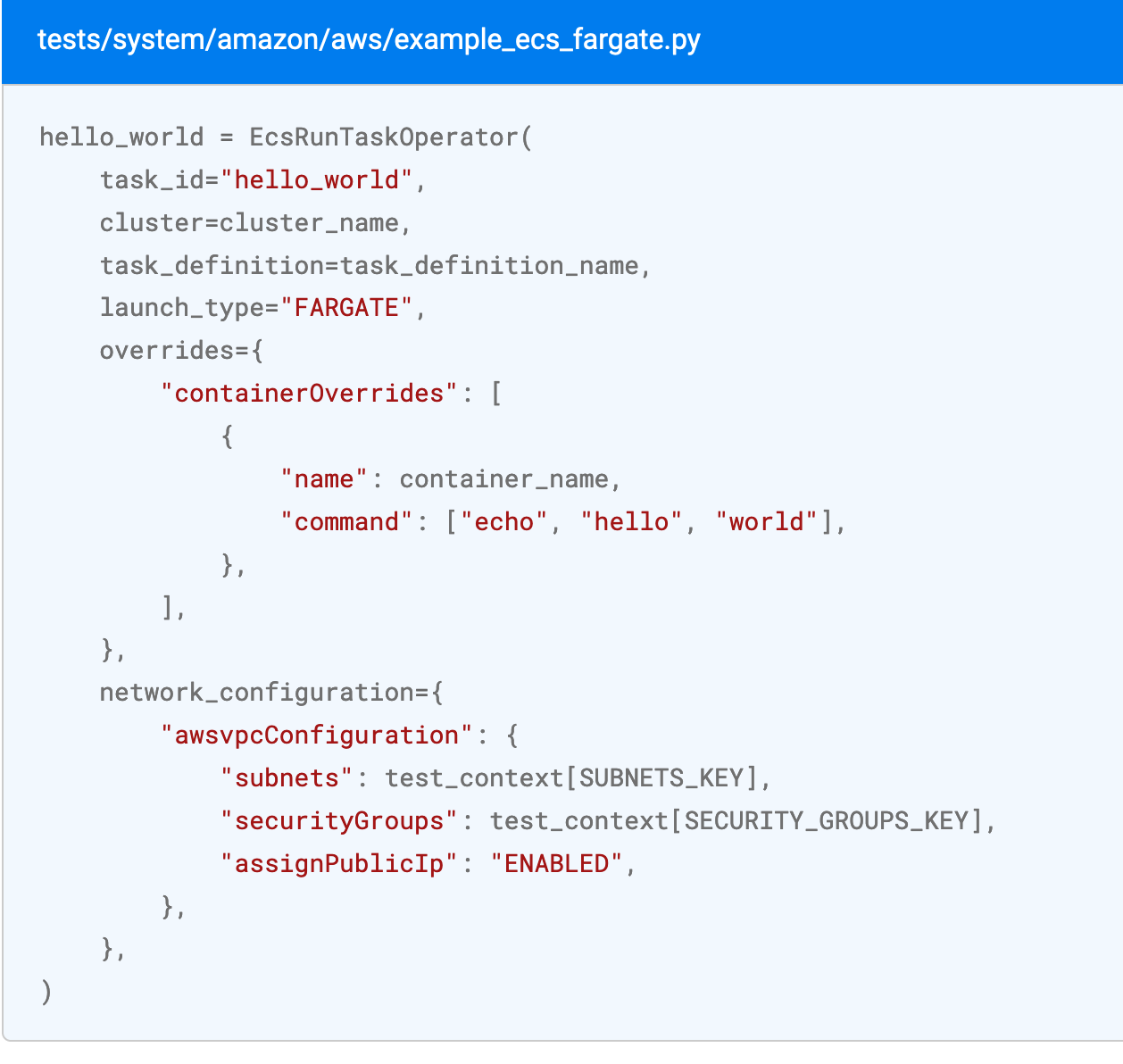
• Airflow with EcsRunTaskOperator + Dynamic Task Mapping
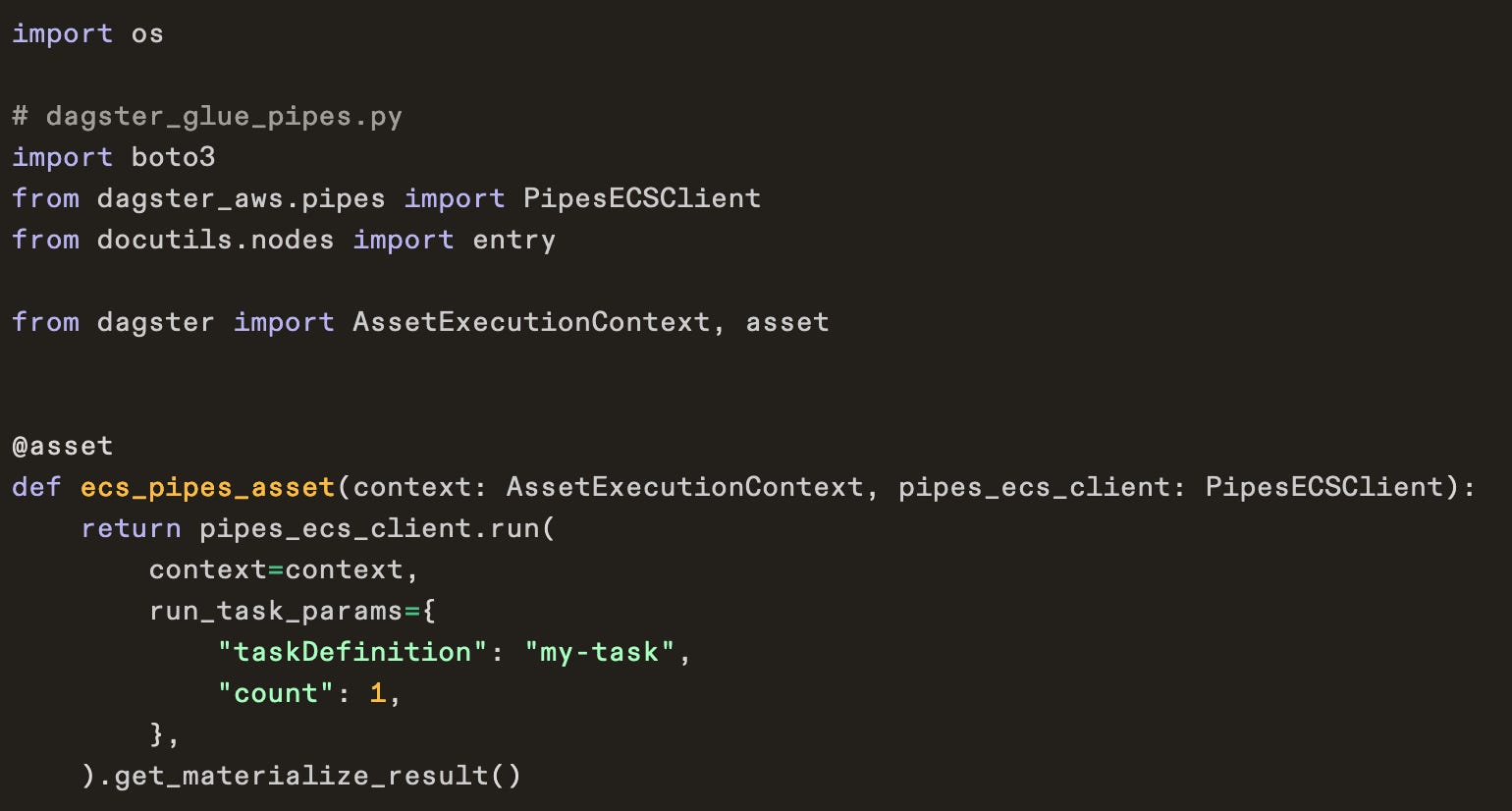
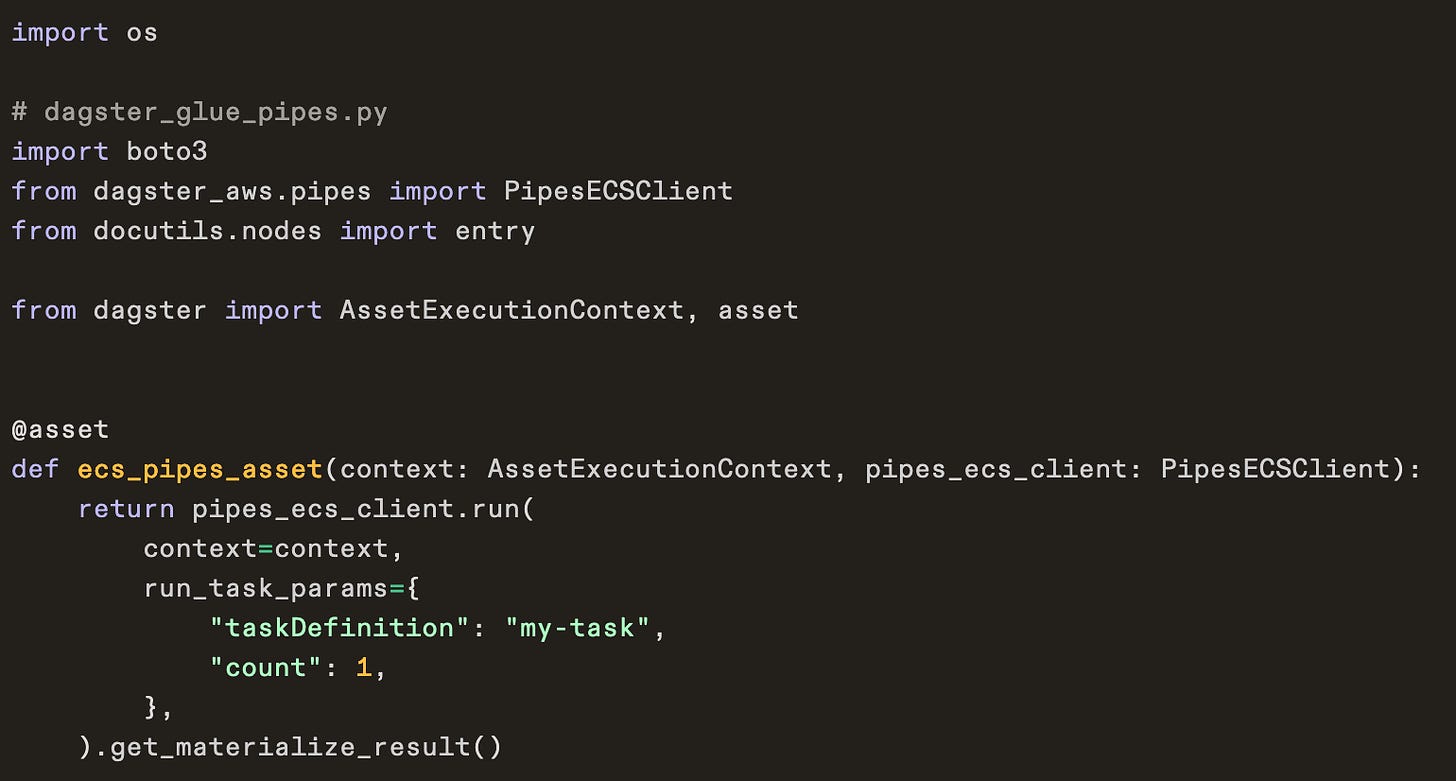
• Dagster via PipesECSClient + partitioned asset
I’ll likely share a detailed implementation with one of these orchestrators in a future (View Highlight)

 (View Highlight)
(View Highlight)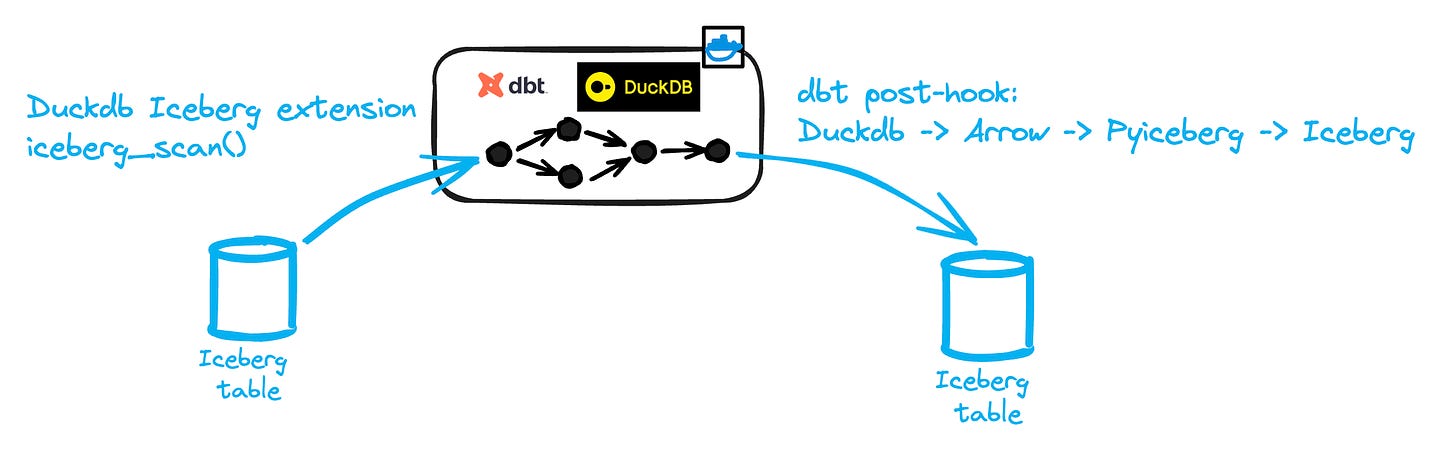 Pros:
• Simplicity
• Efficient data passing across models
Cons:
• All models must fit in the instance’s memory
• No materialization of intermediate models (View Highlight)
Pros:
• Simplicity
• Efficient data passing across models
Cons:
• All models must fit in the instance’s memory
• No materialization of intermediate models (View Highlight)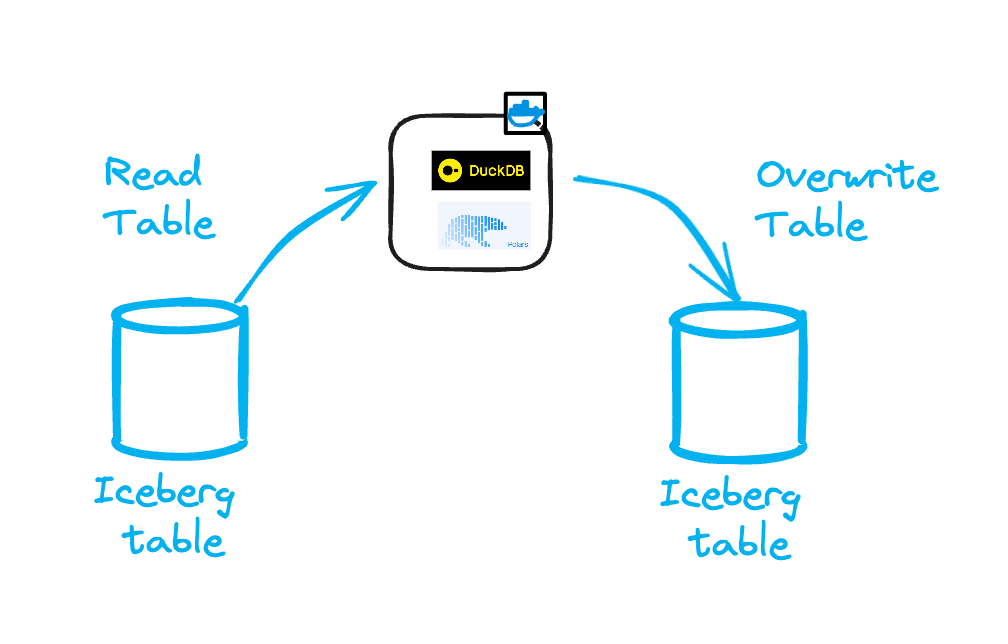 The code using DuckDB would look like this:
The code using DuckDB would look like this:
 The code is oversimplified here; it should be made more generic to accept queries, as well as source and destination tables as inputs.
Instead of running a full materialization, we could switch to an incremental load.
However, PyIceberg isn’t yet optimized for MERGE INTO operations.
Currently, the only option is to use OVERWRITE with an overwrite_filter matching updated rows, but I’ve experienced performance degradation with this method.
Pros:
• All models are materialized to Iceberg.
• You can control the resources used by each model (instance size).
Cons:
• It only works as long as table fits in worker’s memory.
• Inefficient incremental models. (View Highlight)
The code is oversimplified here; it should be made more generic to accept queries, as well as source and destination tables as inputs.
Instead of running a full materialization, we could switch to an incremental load.
However, PyIceberg isn’t yet optimized for MERGE INTO operations.
Currently, the only option is to use OVERWRITE with an overwrite_filter matching updated rows, but I’ve experienced performance degradation with this method.
Pros:
• All models are materialized to Iceberg.
• You can control the resources used by each model (instance size).
Cons:
• It only works as long as table fits in worker’s memory.
• Inefficient incremental models. (View Highlight) Debugging Data Pipelines
Julien Hurault
·
Jun 21
Read full story
The idea is to divide a dataset into partitions that exist independently.
Each partition is immutable and consistently overwritten, avoiding the row-level limitations of PyIceberg discussed earlier.
Debugging Data Pipelines
Julien Hurault
·
Jun 21
Read full story
The idea is to divide a dataset into partitions that exist independently.
Each partition is immutable and consistently overwritten, avoiding the row-level limitations of PyIceberg discussed earlier.
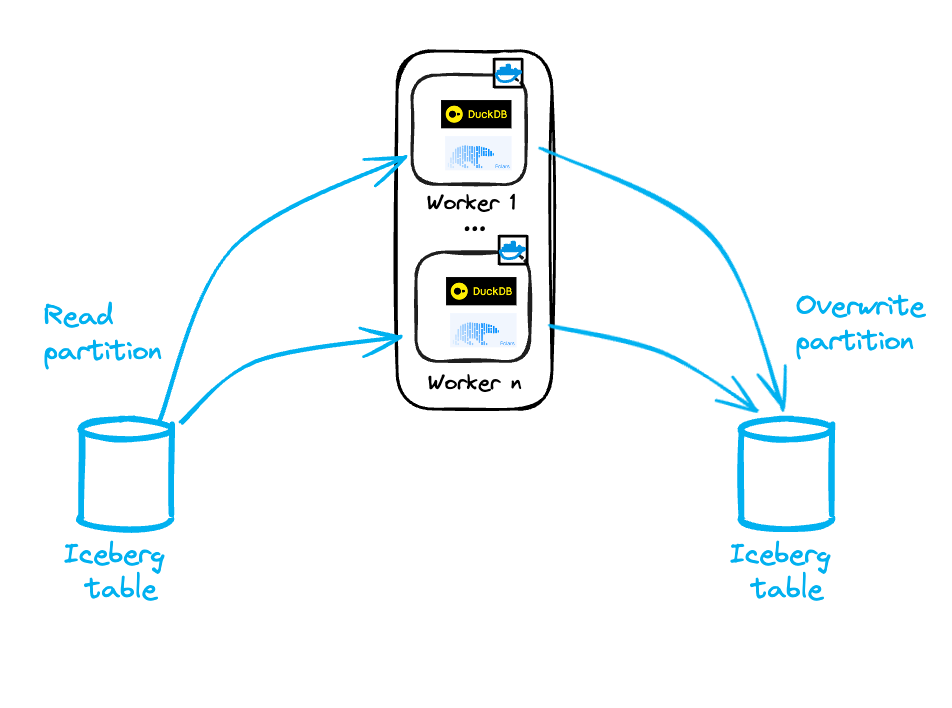 Each worker is then sized to handle a single partition.
Add more workers to process additional partitions for large backfills or initial loads—there’s no need for a particular ‘large’ instance.
Limiting the number of concurrent workers can be beneficial in this setup, as too many can lead to excessive write conflicts and retries.
This can be achieved by adding a buffer/queue from which each worker pulls partitions to process.
To boost throughput, you can then allocate more memory to a worker and process multiple partitions in a single run (one Iceberg commit).
Each worker is then sized to handle a single partition.
Add more workers to process additional partitions for large backfills or initial loads—there’s no need for a particular ‘large’ instance.
Limiting the number of concurrent workers can be beneficial in this setup, as too many can lead to excessive write conflicts and retries.
This can be achieved by adding a buffer/queue from which each worker pulls partitions to process.
To boost throughput, you can then allocate more memory to a worker and process multiple partitions in a single run (one Iceberg commit).
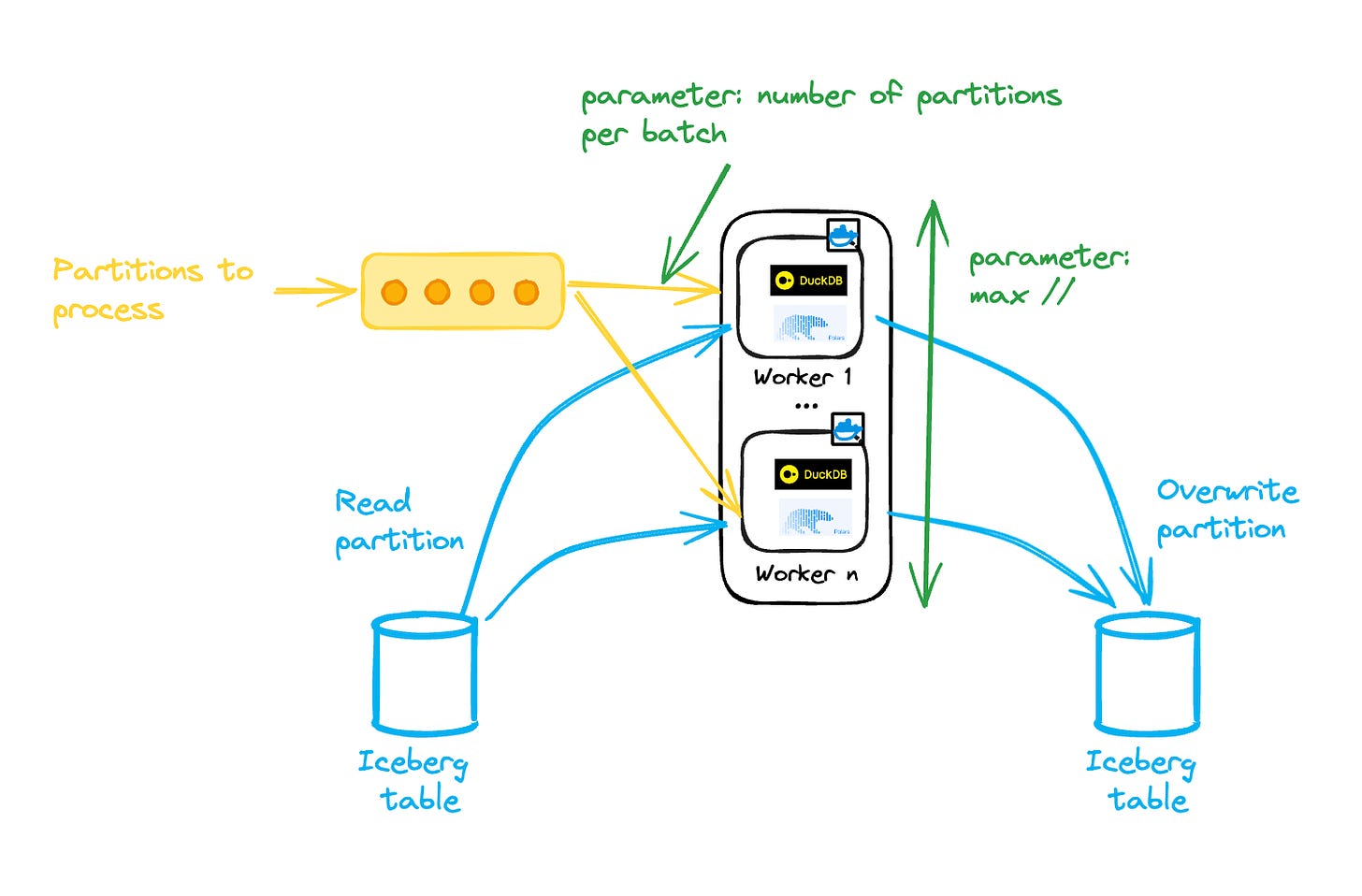 You might ask: what if I want to perform cross-partition aggregations?
In that case, if a single worker isn’t large enough, our favorite data warehouses are here to help :)
Pros:
• Can handle large tables.
• Offers better control over worker sizing as the tables grow.
• Capable of handling large backfills and continuous loads with the same setup.
Cons:
• Requires an orchestrator to track which partitions to process.
• Must control the number of concurrent writers. (View Highlight)
You might ask: what if I want to perform cross-partition aggregations?
In that case, if a single worker isn’t large enough, our favorite data warehouses are here to help :)
Pros:
• Can handle large tables.
• Offers better control over worker sizing as the tables grow.
• Capable of handling large backfills and continuous loads with the same setup.
Cons:
• Requires an orchestrator to track which partitions to process.
• Must control the number of concurrent writers. (View Highlight) You can get large runners (up to 120GB, 16vpcu) that run containers hosted in ECR.
This comes with some limitations:
• Tasks must run in a VPC (a distinct IP is assigned to each task, so ensure enough IPs are available).
• Has a longer cold start time than Lambda (~ 1 min).
• Does not support SQS triggers.
Since there is no direct SQS to Fargate trigger, we need to implement an additional SQS-watching service that will start new tasks based on the SQS queue depth:
You can get large runners (up to 120GB, 16vpcu) that run containers hosted in ECR.
This comes with some limitations:
• Tasks must run in a VPC (a distinct IP is assigned to each task, so ensure enough IPs are available).
• Has a longer cold start time than Lambda (~ 1 min).
• Does not support SQS triggers.
Since there is no direct SQS to Fargate trigger, we need to implement an additional SQS-watching service that will start new tasks based on the SQS queue depth:
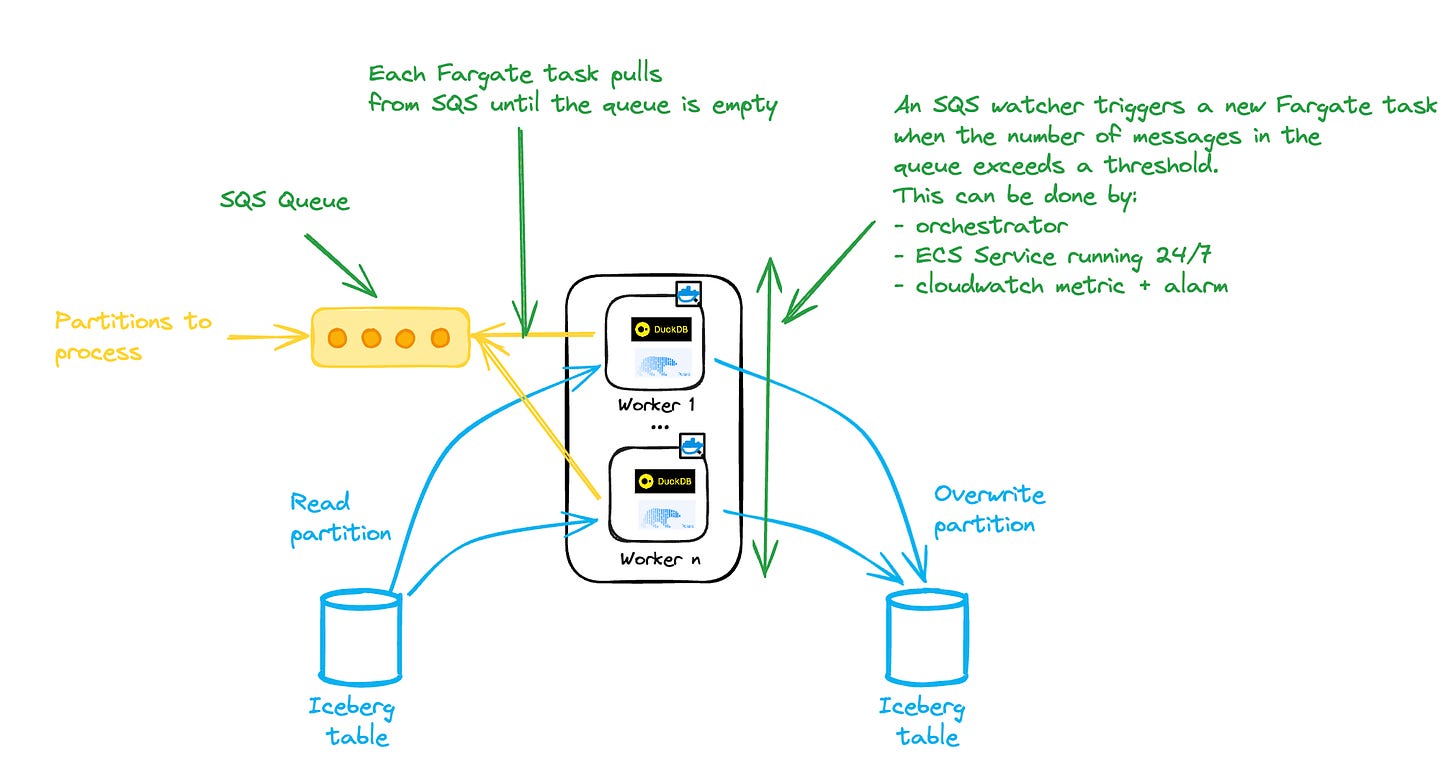 (View Highlight)
(View Highlight)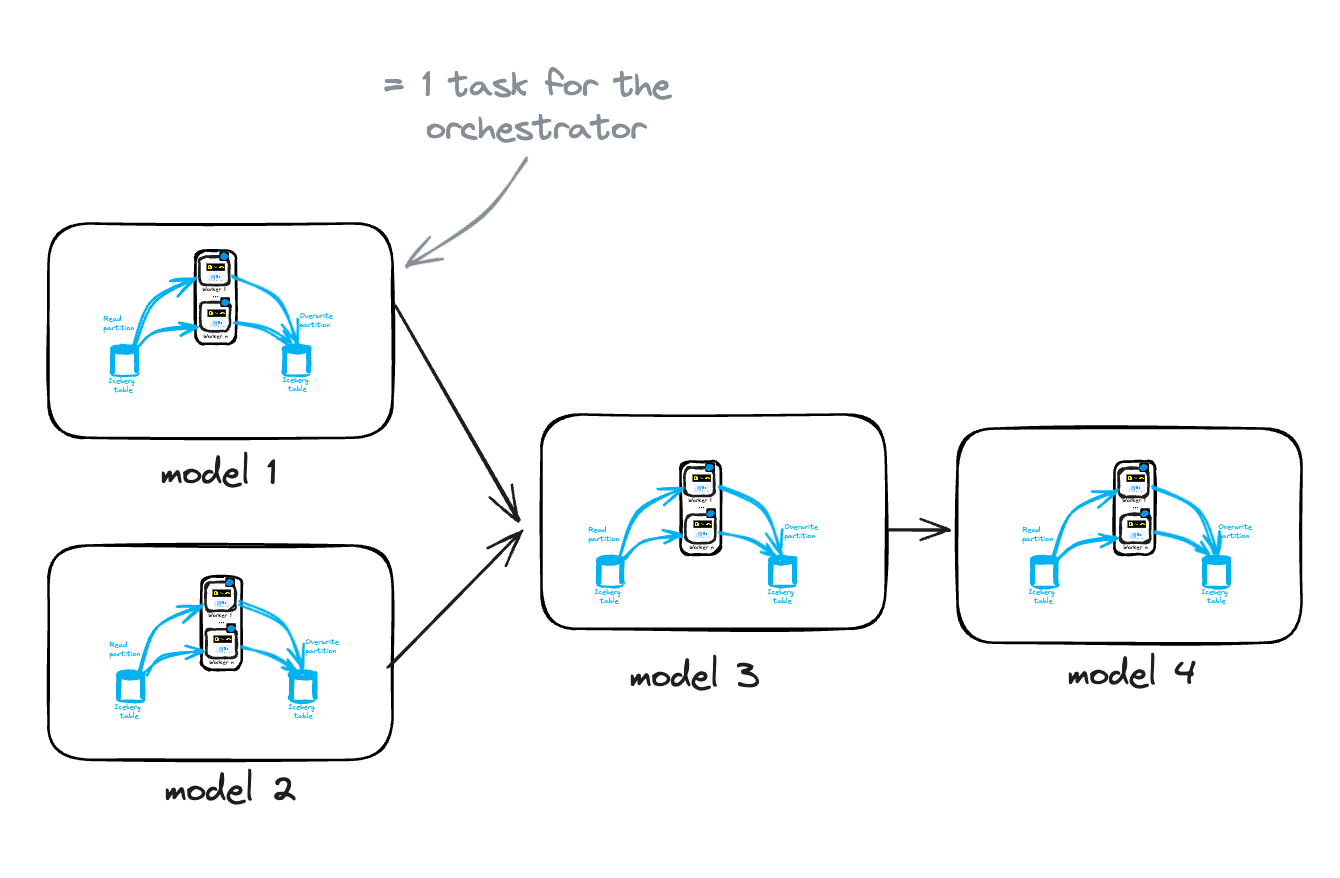 This can be done with various orchestrators:
• Step function with Map + ECS RunTask state
This can be done with various orchestrators:
• Step function with Map + ECS RunTask state
 • Airflow with EcsRunTaskOperator + Dynamic Task Mapping
• Airflow with EcsRunTaskOperator + Dynamic Task Mapping
 • Dagster via PipesECSClient + partitioned asset
• Dagster via PipesECSClient + partitioned asset
 I’ll likely share a detailed implementation with one of these orchestrators in a future (View Highlight)
I’ll likely share a detailed implementation with one of these orchestrators in a future (View Highlight)