Mejorar nuestra salud financiera ahora es más fácil gracias a la actualización de una de las funcionalidades que ofrece la app de BBVA: la categorización de movimientos financieros. Las categorías permiten a los usuarios agrupar sus transacciones, para así llevar un mejor control de sus ingresos y gastos, y comprender de forma global la evolución de sus finanzas. (View Highlight)
se desarrolló un modelo que procesa la descripción textual del movimiento para así asignar la categoría más adecuada de entre todas las definidas en BBVA. El resultado que arroja es homogéneo independientemente de la entidad de origen.
Este modelo se construyó como un clasificador multiclase siguiendo un enfoque supervisado2, por lo que era necesario contar con ejemplos etiquetados. (View Highlight)
En noviembre de 2022 implementamos una nueva versión de nuestra Taxonomía de tipos de gastos e ingresos, la cual permite a nuestros clientes conocer los detalles de su salud financiera y actuar para mejorarla. Este cambio de taxonomía implicó la actualización del modelo que clasifica movimientos financieros, tarea realizada con la ayuda de Annotify, una herramienta desarrollada en BBVA AI Factory que permite etiquetar grandes conjuntos de datos. (View Highlight)
Ahora, nuestros clientes pueden comprender de forma más transversal sus finanzas, al tiempo que reciben información sobre nuevos medios de pago, inversiones o suscripciones. El servicio ofrece una visión detallada de los tipos de gastos, ingresos e inversiones, divididos en categorías y subcategorías. Además, en línea con el compromiso de BBVA con la sostenibilidad, se puede obtener información detallada acerca de la huella de carbono, para así emprender acciones para reducirla. Esta información versa, por ejemplo, sobre los gastos asociados tanto a los vehículos privados (impuestos, combustible, parkings…) como al uso del transporte público. (View Highlight)
Con esta nueva taxonomía hemos mejorado sustancialmente las métricas respecto a la versión anterior. En concreto, hemos mejorado tanto la precisión calculada con su definición habitual, como la precisión ponderada y la “macro precisión”. Paralelamente, conseguimos reducir el número de movimientos que se utilizaron para entrenar el modelo: de tres millones a unos cuarenta mil.
Figura 2. Con el modelo actual, logramos mejorar la precisión un 28%, mientras reducimos en más de un 98% el número de movimientos etiquetados necesarios para entrenar el modelo.
Figura 2. Con el modelo actual, logramos mejorar la precisión un 28%, mientras reducimos en más de un 98% el número de movimientos etiquetados necesarios para entrenar el modelo. (View Highlight)
El objetivo de la nueva taxonomía era doble. Por un lado, la actualización busca mejorar los resultados del modelo para que nuestros clientes tengan una visión completa de sus movimientos financieros que les ayude a tomar decisiones más convenientes. Por otro lado, se aprovechó para mejorar el proceso de desarrollo del modelo de clasificación (Machine Learning) para movimientos realizados en otras entidades financieras, reduciendo los esfuerzos en el etiquetado de los datos. (View Highlight)
El desarrollo del anterior modelo implicó el etiquetado de tres millones de movimientos con diferentes estrategias, entre ellas el etiquetado manual de datos muestreados y el uso de reglas automáticas de etiquetado a partir de la similitud con otras etiquetas de movimientos bancarios. Para crear el modelo actual partimos del conjunto de movimientos más recientes e hicimos la traducción a la nueva taxonomía 2.0. De tres millones de etiquetas pasamos a un millón, pero con dos inconvenientes:
Eran datos con cierta antigüedad, por lo que había tipos de gastos, de inversiones y de comercios que no estaban reflejados en el dataset;
Debido a la manera en la que se etiquetaron esos primeros datos, la distribución de los movimientos por subcategorías no representaba la realidad. Por esto, nos encontramos con la necesidad de etiquetar datos nuevamente. (View Highlight)
Annotify es una librería que ejecuta métodos de Active Learning (AL), un caso específico de Machine Learning en el que un algoritmo de aprendizaje consulta a un usuario (o a alguna otra fuente de información) a la hora de etiquetar nuevas muestras de datos. Con estas técnicas reducimos la cantidad total de datos etiquetados necesarios para obtener un buen desempeño del modelo, ya que se proponen muestras a etiquetar más valiosas, evitando seleccionar muestras de forma aleatoria. (View Highlight)
En esta línea, empleamos AL para seleccionar movimientos financieros que fuesen útiles para el modelo, partiendo de un total de un millón de registros. De estos, se seleccionaron treinta mil registros, pues este dataset más reducido ya era representativo para el modelo (esto es, el rendimiento del mismo no mejoraba sustancialmente al incluir más movimientos).
Sin embargo, con este primer dataset todavía no obteníamos las métricas que esperábamos para el modelo. Para aumentar su rendimiento, volvimos a usar AL seleccionando movimientos del último año, ya que eran los que resultaban más confusos para el primer modelo. El flujo de trabajo que seguimos fue el siguiente: (View Highlight)
Entrenar el modelo con el dataset que ya teníamos etiquetado;
Aplicar AL para seleccionar nuevos movimientos a etiquetar;
Etiquetarlos y añadirlos al dataset de datos etiquetados;
Repetimos este ciclo hasta obtener unas métricas que nos convencían, considerando el compromiso entre coste de desarrollo y mejora obtenida en cada iteración.
Figura 3. Entrenamos un primer modelo partiendo de una primera anotación manual y dividiendo las muestras en dos conjuntos: entrenamiento y evaluación. Posteriormente, Annotify propone nuevas muestras a etiquetar, que son corregidas por CleanLab cuando hay discrepancias. Con este conjunto de datos actualizado, podemos volver a entrenar un nuevo modelo y seguir el ciclo de nuevo. (View Highlight)
Complementamos el uso de AL con Cleanlab, una librería open-source que detecta el ruido en las etiquetas de un dataset. Esto fue necesario porque, si bien íbamos definiendo y unificando criterios de anotación para los movimientos, algunos se podían vincular a varias subcategorías según la interpretación del anotador. Para reducir el impacto de tener subcategorías diferentes para movimientos similares, empleamos Cleanlab en la detección de discrepancias. Finalmente, obtuvimos un dataset de cuarenta mil movimientos etiquetados en total.
Figura 4. Las muestras propuestas por Annotify son etiquetadas por los anotadores. Posteriormente, CleanLab resuelve las posibles discrepancias de los anotadores a la hora de etiquetar movimientos (muestras) similares.
Figura 4. Las muestras propuestas por Annotify son etiquetadas por los anotadores. Posteriormente, CleanLab resuelve las posibles discrepancias de los anotadores a la hora de etiquetar movimientos (muestras) similares. (View Highlight)

 Figura 2. Con el modelo actual, logramos mejorar la precisión un 28%, mientras reducimos en más de un 98% el número de movimientos etiquetados necesarios para entrenar el modelo.
Figura 2. Con el modelo actual, logramos mejorar la precisión un 28%, mientras reducimos en más de un 98% el número de movimientos etiquetados necesarios para entrenar el modelo.
 Figura 2. Con el modelo actual, logramos mejorar la precisión un 28%, mientras reducimos en más de un 98% el número de movimientos etiquetados necesarios para entrenar el modelo. (View Highlight)
Figura 2. Con el modelo actual, logramos mejorar la precisión un 28%, mientras reducimos en más de un 98% el número de movimientos etiquetados necesarios para entrenar el modelo. (View Highlight)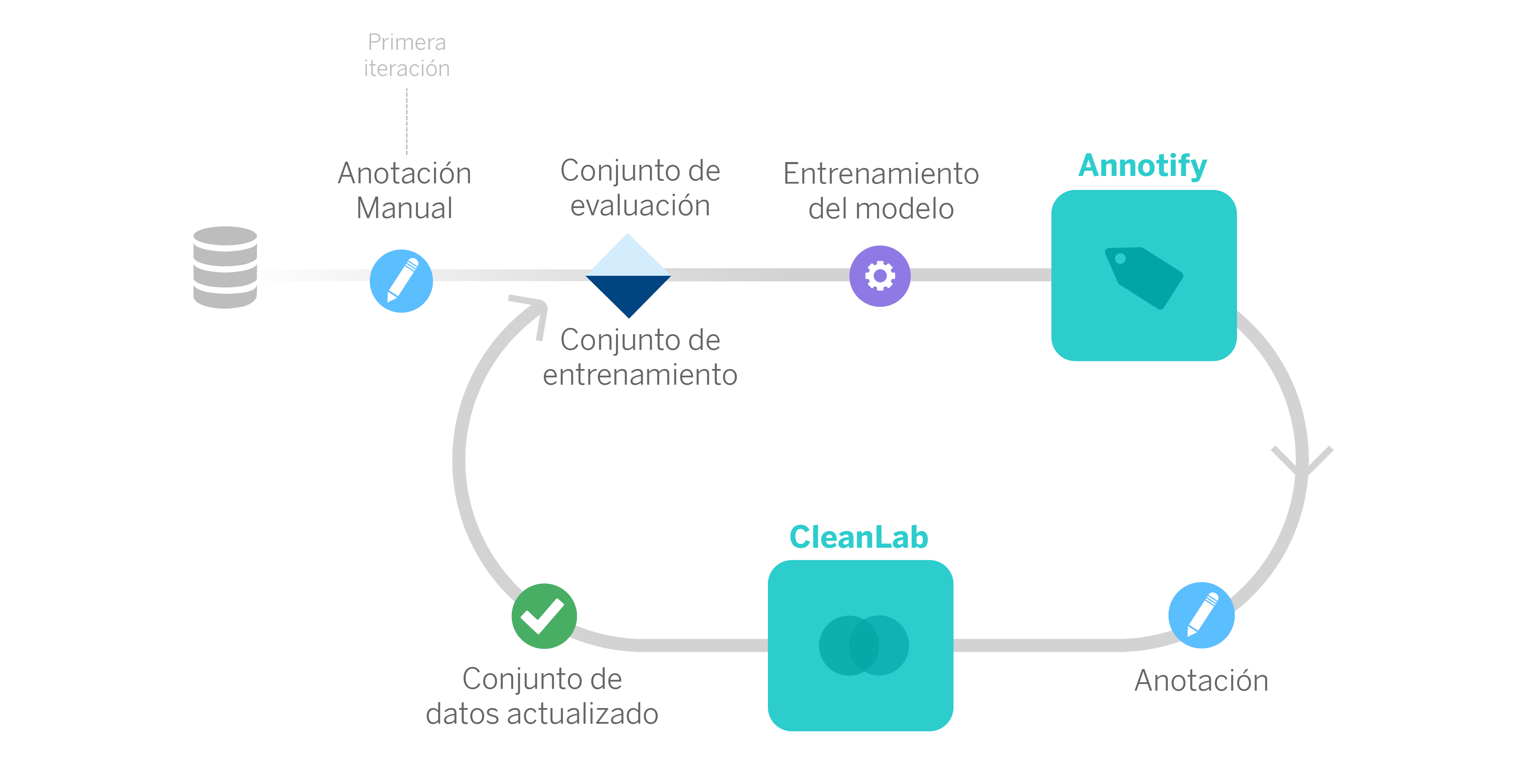 Figura 3. Entrenamos un primer modelo partiendo de una primera anotación manual y dividiendo las muestras en dos conjuntos: entrenamiento y evaluación. Posteriormente, Annotify propone nuevas muestras a etiquetar, que son corregidas por CleanLab cuando hay discrepancias. Con este conjunto de datos actualizado, podemos volver a entrenar un nuevo modelo y seguir el ciclo de nuevo. (View Highlight)
Figura 3. Entrenamos un primer modelo partiendo de una primera anotación manual y dividiendo las muestras en dos conjuntos: entrenamiento y evaluación. Posteriormente, Annotify propone nuevas muestras a etiquetar, que son corregidas por CleanLab cuando hay discrepancias. Con este conjunto de datos actualizado, podemos volver a entrenar un nuevo modelo y seguir el ciclo de nuevo. (View Highlight)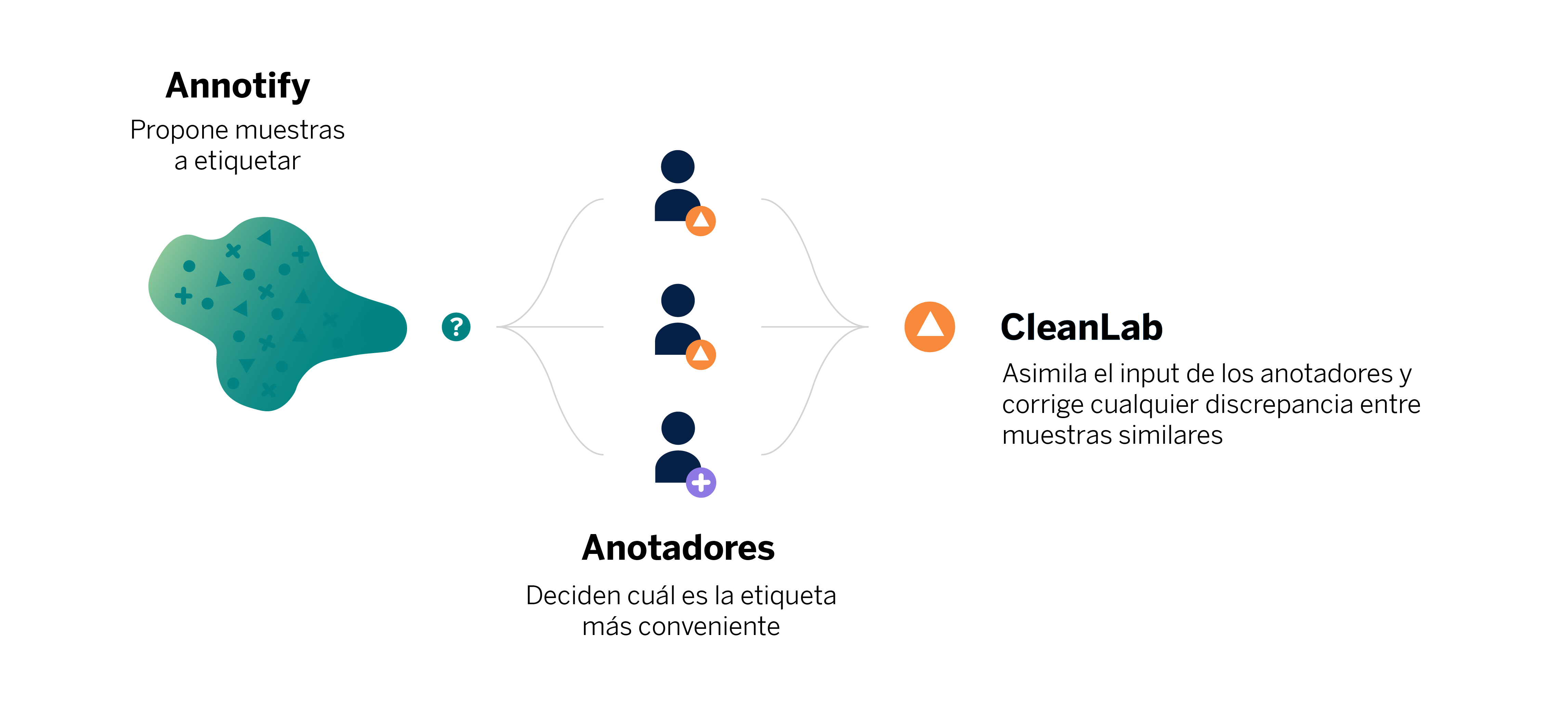 Figura 4. Las muestras propuestas por Annotify son etiquetadas por los anotadores. Posteriormente, CleanLab resuelve las posibles discrepancias de los anotadores a la hora de etiquetar movimientos (muestras) similares.
Figura 4. Las muestras propuestas por Annotify son etiquetadas por los anotadores. Posteriormente, CleanLab resuelve las posibles discrepancias de los anotadores a la hora de etiquetar movimientos (muestras) similares.
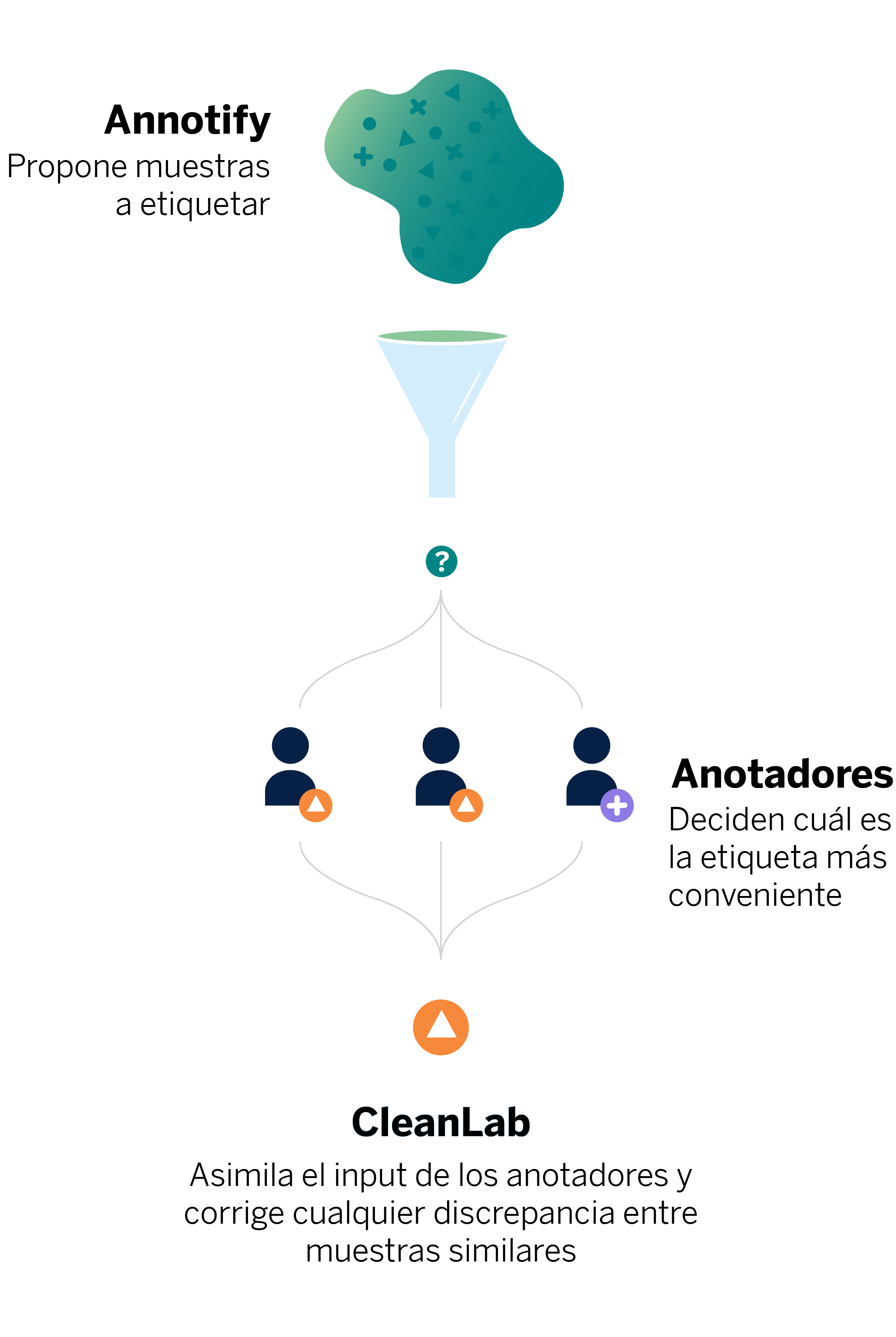 Figura 4. Las muestras propuestas por Annotify son etiquetadas por los anotadores. Posteriormente, CleanLab resuelve las posibles discrepancias de los anotadores a la hora de etiquetar movimientos (muestras) similares. (View Highlight)
Figura 4. Las muestras propuestas por Annotify son etiquetadas por los anotadores. Posteriormente, CleanLab resuelve las posibles discrepancias de los anotadores a la hora de etiquetar movimientos (muestras) similares. (View Highlight)